




一、语音识别的原理
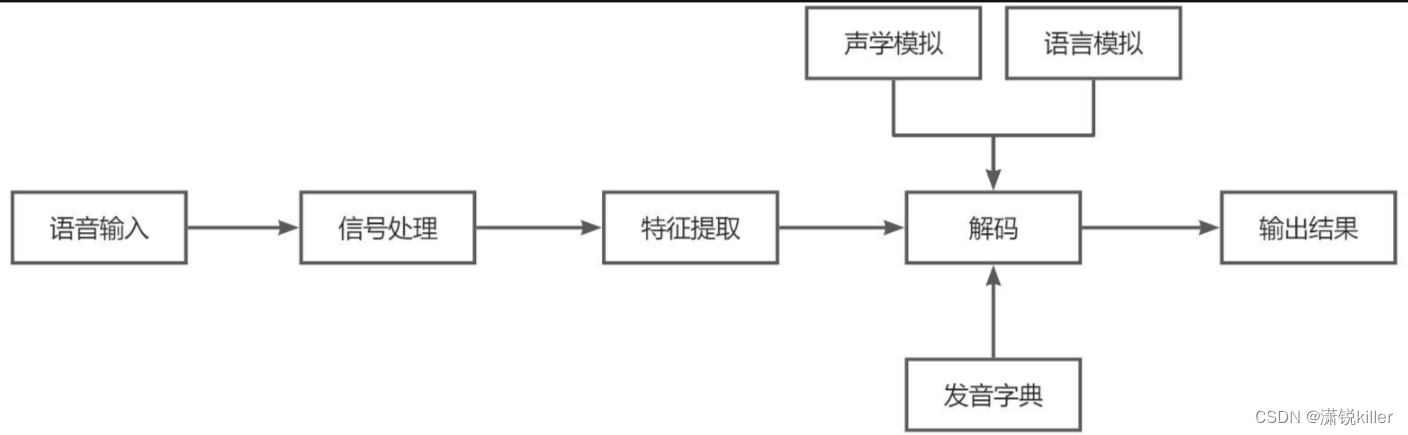
一个连续语音识别系统包含了特征提取、声学模型、语言模型和解码器这四个主要部分。
特征提取是指在除去语音信号中对于语音识别无用的信息后,保留能够反映语音本质特征的关键信息,对其进行处理,再用特定的形式表示出来,用于后续的进一步处理。
声学模型可以理解为是对声音进行建模,把语音输入转换为声学表示的输出。
语言模型是用来计算出一个句子出现概率的模型,简单来说,就是计算出这个句子在语法上是否正确的概率。
解码器就是指语音技术中的识别过程。
语音识别的本质就是一种模式识别的过程,将未知的语音模式与已知的语音模式进行对比,最佳匹配的参考模式就被视为识别结果。
实现基本原理图
整个语音识别的过程,先从本地获取音频,然后传到云端,最后识别出文本,就是一个声学信号转换成文本信息的过程。
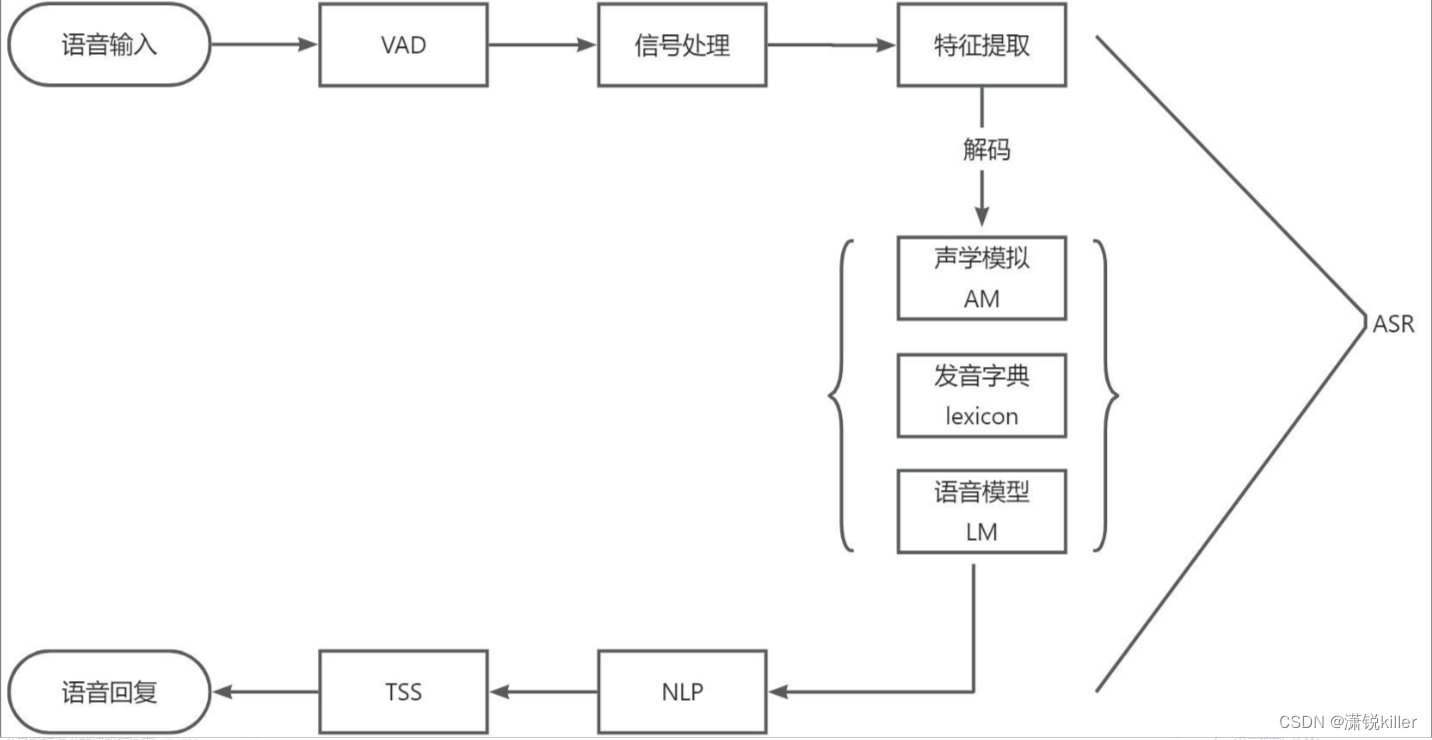
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成干扰,这个切除静音的操作一般称为VAD。
VAD(Voice Activity Detection),也叫语音激活检测,或者静音抑制,其目的是检测当前语音信号中是否包含话音信号存在,即对输入信号进行判断,将话音信号与各种背景噪声信号区分出来,分别对两种信号采用不同的处理方法。
算法方面,VAD算法主要用了2-3个模型来对语音建模,并且分成噪声类、语音类和静音类。目前大多数还是基于信噪比的算法,也有一些基于深度学习(DNN)的模型。
这里的信号处理一般指的是降噪,有些麦克风阵列本身的降噪算法受限于前端硬件的限制,会把一部分降噪的工作放在云端。
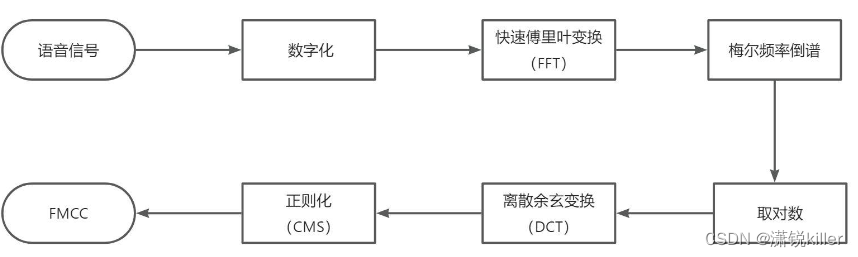
4、特征提取
特征提取是语音识别关键的一步,解压完音频文件后,就要先进行特征提取,提取出来的特征作为参数,为模型计算做准备。简单理解就是语音信息的数字化,然后再通过后面的模型对这些数字化信息进行计算。
特征提取首先要做的是采样,前面我们说过音频信息是以数据流的形式存在,是连续不断的,对连续时间进行离散化处理的过程就是采样率,单位是Hz。可以理解为从一条连续的曲线上面取点,取的点越密集,越能还原这条曲线的波动趋势,采样率也就越高。理论上越高越好,但是一般10kHz以下就够用了,所以大部分都会采取16kHz的采样率。
5、声学模型(AM)
把从声音中提取出来的特征,通过声学模型,计算出相应的音素。
6、语言模型(LM)
语言模型是将语法和字词的知识进行整合,计算文字在这句话下出现的概率。一般自然语言的统计单位是句子,所以也可以看做句子的概率模型。简单理解就是给你几个字词,然后计算这几个字词组成句子的概率。
7、词典
词典就是发音字典的意思,中文中就是拼音与汉字的对应,英文中就是音标与单词的对应,其目的是根据声学模型识别出来的音素,来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来。简单理解词典是连接声学模型和语言模型的月老。
二、Springboot + 百度短语音识别sdk 实践demo
1、在 百度智能云-登录
领取 语音识别的免费使用次数 (个人 15万)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









