



日期相关函数
格式化日期
DATE_FORMAT(stat_date,'%Y')
DATE_FORMAT(stat_date,'%Y-%m')
DATE_FORMAT(stat_date,'%Y-%m-%d')
DATE_FORMAT(startTime,'%Y-%m-%d %H:%i:%S')
日期加减计算
-- 日期加减固定时间
DATE_SUB(stat_date,INTERVAL 1 DAY)
DATE_SUB(stat_date,INTERVAL -1 DAY)
DATE_SUB(stat_date,INTERVAL 1 MONTH)
DATE_SUB(stat_date,INTERVAL 1 YEAR)
-- 日期差
DATEDIFF('2021-10-15', '2021-09-01')
-- 时间差(可选单位)
-- TIMESTAMPDIFF(unit,begin,end)
-- unit单位:MICROSECOND、SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR
select max(operate_time),min(operate_time),TIMESTAMPDIFF(SECOND,min(operate_time),max(operate_time)) from operate
获取日期或时间
select CURDATE()
select CURTIME()
四舍五入浮点型
ROUND((t1-t2),3)
json相关函数
-- 查字段
JSON_EXTRACT(recevie, '$.name')
-- 去双引号
JSON_UNQUOTE()
-- 删除字段
JSON_REMOVE(recevie,'$.name')
构造 JSON 对象
SELECT
JSON_OBJECT ( 'id', id, 'index', handle, 'type', type, 'value', name ) AS Json
FROM
idf_upload_data
构造 JSON 数组
SELECT
JSON_ARRAY (
JSON_OBJECT ( 'name', "姓名", 'index', 2000, 'type', "name", 'value', name ),
JSON_OBJECT ( 'name', "性别", 'index', 2001, 'type', "sex", 'value', sex )
) AS JsonArray
FROM
idf_upload_data
将列的值聚合成 JSON 数组
SELECT
JSON_ARRAYAGG ( JSON_OBJECT ( 'name', name ) ) AS JsonArray
FROM
test
SELECT
JSON_ARRAYAGG ( name ) AS JsonArray
FROM
test
修改字段值
UPDATE test SET data = json_set(data,'$.name',name)
根据json的key值查找对应的含义
SELECT
a.id, a.name
FROM
json2 a left join
(select json_keys ( json ) json from json ) b
on JSON_CONTAINS ( json_keys ( b.json ), JSON_ARRAY ( cast(a.id AS CHAR) )) = 1
查询json数组中的数据
SELECT
id,
json_UNQUOTE ( json_extract ( json, concat( "$[", ht.help_topic_id, "].twoIndex" ) ) ) AS twoIndex ,
json_UNQUOTE ( json_extract ( json, concat( "$[", ht.help_topic_id, "].observeTruth" ) ) ) AS observeTruth
FROM
test jt
INNER JOIN mysql.help_topic ht ON ht.help_topic_id < JSON_LENGTH ( jt.json )
字符串相关函数
字符串拼接
CONCAT(DATE_FORMAT(stat_date,'%Y'),'-01-01') as stat_year
字符截取
-- 这将从列的值中提取一个子字符串,从指定的起始位置开始,直到指定的长度。
SUBSTRING(column_name, start, length)
获取字符串varchar的前几位
-- 用于返回某个被请求的文本域的左侧部分,其中c代表被请求的文本域,number_of_cha代表需要取出的字符串位数。
-- 如“LEFT("zhidao.baidu.com", 6)”即可取得字符串"zhidao"。
LEFT(c, number_of_char)
求char型数据长度
#字节长度
length(string)
#字符长度(包含中文,中文1字符 = 2字节)
char_length(string)
字符替换
# 当字符中包含换行符\n时,字符串转json失败,需要将换行符特殊处理
REPLACE(content, '\n', ' ')
REPLACE(REPLACE(content.`desc`, '\n', ''), '"', '\\"')
字符大小写转换
UPPER(expression):这会将字符串表达式转换为大写。
LOWER(expression):这会将字符串表达式转换为小写。
字符串补齐
-- 将code显示为16位的字符串,不足16位的左侧补0
LPAD(code,16,0)
分组之后逗号分隔字段(竖转横)
-- GROUP_CONCAT( id )
SELECT
company_id,
GROUP_CONCAT( id )
FROM
user
GROUP BY
company_id
-- GROUP_CONCAT 也是可以控制排序去重的
GROUP_CONCAT(distinct id order by id)
逗号分隔,字符串拆分(横转竖)
SUBSTRING_INDEX('7654,7698,7782,7788',',',4)
详细内容参考MySQL 逗号分隔,字符串拆分(横转竖)_小心仔的博客-优快云博客
int和varchar互转
-- int 转 varchar
CAST(id AS CHAR)
-- varchar 转 int
"0" + 0
设置变量
set @EDATE=now();
select @EDATE;
合并结果集(横转竖)
--结果集返回的列数必须相同
union all -- 不判断重复,直接组合
Select 1,'a'
Union All Select 2,'b'
Union All Select 2,'c';
union -- 会将两个结果集中数据去重
Select 1,'a'
Union Select 2,'b'
Union Select 2,'c';
分组统计汇总
-- group by 后可以跟with rollup,表示在进行分组统计的基础上再次进行汇总统计
SELECT
sex,count(1)
from stu
GROUP BY
sex WITH ROLLUP
判断字段包含
FIND_IN_SET( v_auth_model.id, cids )
首先举个例子来说:有个文章表里面有个type字段,它存储的是文章类型,有 1头条、2推荐、3热点、4图文等等 。现在有篇文章他既是头条,又是热点,还是图文,type中以 1,3,4 的格式存储。那我们如何用sql查找所有type中有4的图文类型的文章呢??这就要我们的 find_in_set 出马的时候到了。
select * from article where FIND_IN_SET('4',type)locate(substr,str)
使用locate(substr,str)函数,如果包含,返回>0的数,否则返回0
SELECT * FROM article WHERE locate( '河北省',re)
求字符串被分割后的长度
-- 元素数量
select LENGTH('7654,7698,7782,7788') - LENGTH(REPLACE('7654,7698,7782,7788', ',', '')) + 1;
-- 逗号数量
select LENGTH('7654,7698,7782,7788') - LENGTH(REPLACE('7654,7698,7782,7788', ',', ''));
清空表数据
truncate table 表名
根据数据所属区间分组
elt(interval(score,0,60,70,80,90,100),"0-60","60-70","70-80","80-90","90-100")
生成随机数
0 < RAND() < 1
-- 生成50-100之间的随机整数
SELECT FLOOR(RAND() * 50)+50;
-- 生成随机的32位md5()字符串
SELECT MD5(RAND() * 10000)
MySQL varchar查询不区分大小写
当要求账号严格区分大小写时,发现数据库账号字段不区分大小写
-- 下面两条sql都能查询出lisi的账号信息
select * from user where account = "LISI";
select * from user where account = "lisi";
-- 使用binary可以区分大小写
select * from user where binary account = "LISI";
EXPLAIN函数
当您在需要执行的SQL语句前加上EXPLAIN,然后执行SQL时,您将会看到其具体的执行计划,以此分析耗时,进而修改SQL,达到优化的效果。
| 列名称 | 描述 |
|---|---|
| table | 显示该行数据所归属的表。 |
| type | 显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。 |
| possible_keys | 显示可能应用在该表中的索引。 |
| key | 实际使用的索引。如果为NULL,则没有使用索引。个别情况下,MySQL会选择优化不足的索引。在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MySQL忽略索引。 |
| key_len | 使用的索引的长度。在不损失精确性的情况下,长度越短越好。 |
| ref | 显示索引被使用的列,通常为一个常数。 |
| rows | MySQL用来返回请求数据的行数。 |
| Extra | 关于MySQL如何解析查询的额外信息。 |
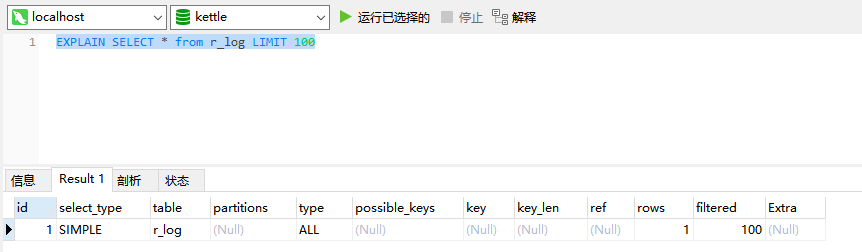
强制使用(忽略)索引
-- force index(idx_s_group)
SELECT `source`,count(1) number FROM `test` force index(idx_source_group) where `group` = 2 GROUP BY `source`
-- ignore index忽略索引
多列in的使用
SELECT * FROM `job` where (id,name) in (select id,name from job)
求比率
AVG(c.action = 'confirmed')
SUM(IF(c.action = 'confirmed',1,0)) / SUM(1)
这段代码相当于是 计算比率 = 请求被确认的数量 / 总请求数量,可以理解成 AVG 函数括号里面 是计算 请求被确认的数量,而 AVG 这个函数本身 就是最后要除以 总请求数量
正则表达式
select * from User where email REGEXP '^[a-zA-Z][a-zA-Z0-9_.-]*\\@leetcode\\.com$';
- 前缀 名称是一个字符串,可以包含字母(大写或小写),数字,下划线 ‘_’ ,点 ‘.’ 和/或破折号 ‘-’ 。前缀名称 必须 以字母开头
- 域 为 ‘@leetcode.com’
下面介绍几个常见的正则表达式模式:
^:匹配字符串的开始位置。例如,^hello会匹配以"hello"开头的字符串。
$:匹配字符串的结束位置。例如,world$会匹配以"world"结尾的字符串。
.:匹配除换行符以外的任意字符。例如,a.b会匹配"a+b"、"a@b"等。
*:匹配前面的模式零次或多次。例如,a*b会匹配"b"、"ab"、"aab"等。
+:匹配前面的模式一次或多次。例如,a+b会匹配"ab"、"aab"、"aaab"等。
?:匹配前面的模式零次或一次。例如,a?b会匹配"b"、"ab"。
[]:定义字符集合。例如,[abc]会匹配"a"、"b"、"c"中的任意一个字符。
[^]:否定字符集合。例如,[^abc]会匹配除了"a"、"b"、"c"之外的任意字符。
\d:匹配数字。等价于[0-9]。
\w:匹配字母、数字或下划线。等价于[A-Za-z0-9_]。
\s:匹配空白字符,包括空格、制表符、换行符等。
\b:匹配单词边界。例如,\btest\b会匹配单独的单词"test"。
按照中文拼音首字母排序
使用默认的order by函数无法对中文数据按照首字母进行排序
CONVERT ( name USING gbk )
修改字符集格式
-- 设置表
ALTER TABLE tbls CONVERT TO CHARACTER SET 'utf8';
-- 设置表字段
ALTER TABLE tbls modify COLUMN PARAM_VALUE mediumtext CHARACTER SET utf8;
count函数带条件
-- count只有在值为null时才不统计数据
-- 错误: count( alarm_num > 0) 统计alarm_num不是null的行数,和条件没关系
count( alarm_num > 0 or null)
重定义结束符
在导出的sql文件中有时会出现delimiter符号,多出现在创建函数的命令中,起到重定义结束符的作用,防止因为;半路结束sql的运行(注意delimiter后必须有空格)
delimiter ;; -- 将;;定义为结束符
CREATE FUNCTION `xxx`() RETURNS longtext CHARSET utf8mb4
BEGIN
select 1; -- 不是结束符,继续运行
select 2; -- 不是结束符,继续运行
select 3; -- 不是结束符,继续运行
END
;; -- 结束
delimiter ; -- 恢复;为结束符
自定义排序
顺序按照 其他值,210,180,190,260排序;
SELECT * FROM table ORDER BY FIELD(type,210,180,190,260);
此方式列举出的值虽然可以正常排序,但是不在列举的值的数据会排在所列出的值的数据之前; 一般应用中,通常希望其他结果的数据排在列举出的数据之后,则
SELECT * FROM table ORDER BY FIELD(type,260,190,180,210) DESC;
insert update
insert into test(`id`, `name`, `age`) VALUES (1, 'zhangsan', 21)
ON DUPLICATE KEY UPDATE `name` = 'zhangsan', `age` = 21;
insert into test(`id`, `name`, `age`) VALUES (1, 'zhangsan', 21)
ON DUPLICATE KEY UPDATE `name` = value(`name`), `age` = value(`age`);

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









