




文章目录
- 一、 Redis简介
- 二、 使用Redis作为缓存工具时流程(边路缓存思想中一部分)
- 三、 基于Docker安装Redis单机版
- 四、 Redis数据类型(面试问题)
- 五、 Redis持久化策略(面试问题)
- 六、Redis 的过期删除策略
- 七、Redis的内存淘汰策略
- 八、 Redis主从复制
- 八、 哨兵(Sentinel)
- 九、 Redis集群(Cluster)
- 十、Redis6的新特性
- 十一、 高并发下Redis可能存在的问题及解决方案
一、 Redis简介
1. NoSQL简介
目前市场主流数据存储都是使用关系型数据库。每次操作关系型数据库时都是I/O操作,I/O操作是主要影响程序执行性能原因之一,连接数据库关闭数据库都是消耗性能的过程。关系型数据库索引数据结构都是树状结构,当数据量特别大时,导致树深度比较深,当深度深时查询性能会大大降低。尽量减少对数据库的操作,能够明显的提升程序运行效率。
针对上面的问题,市场上就出现了各种NoSQL(Not Only SQL,不仅仅可以使用关系型数据库)数据库,它们的宣传口号:不是什么样的场景都必须使用关系型数据库,一些特定的场景使用NoSQL数据库更好。
常见NoSQL数据库:
- memcached :键值对,内存型数据库,所有数据都在内存中。
- Redis:和Memcached类似,还具备持久化能力。
- HBase:以列作为存储。
- MongoDB:以Document做存储。
2. Redis简介
Redis是以Key-Value形式进行存储的NoSQL数据库。 Redis是使用C语言进行编写的。
平时操作的数据都在内存中,效率特高,读的效率110000次/s,写81000次/s,所以多把Redis当做缓存工具使用(在一些框架中还把Redis当做临时数据存储工具)。缓存工具:把数据库中数据缓存到Redis中,由于Redis读写性能较好,访问Redis中数据,而不是频繁访问数据库中数据。
Redis以slot(槽)作为数据存储单元,每个槽中可以存储N多个键值对。Redis中固定具有16384个槽。理论上可以实现一个槽是一个Redis。每个向Redis存储数据的key都会进行crc16算法得出一个值后对16384取余就是这个key存放的solt位置。
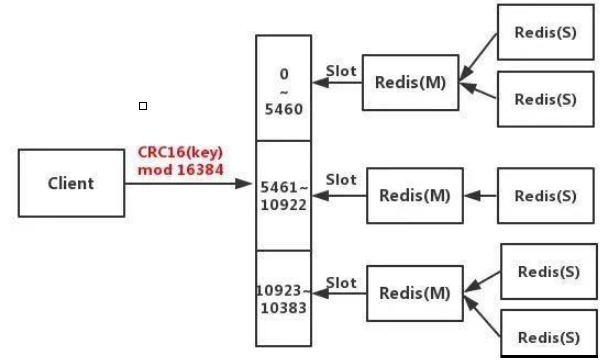
虽然槽的大小是不固定的,但是Redis一个键值对最大大小为512M(String 类型Value)同时通过Redis Sentinel(哨兵)提供高可用,通过Redis Cluster(集群)提供自动分区。
二、 使用Redis作为缓存工具时流程(边路缓存思想中一部分)
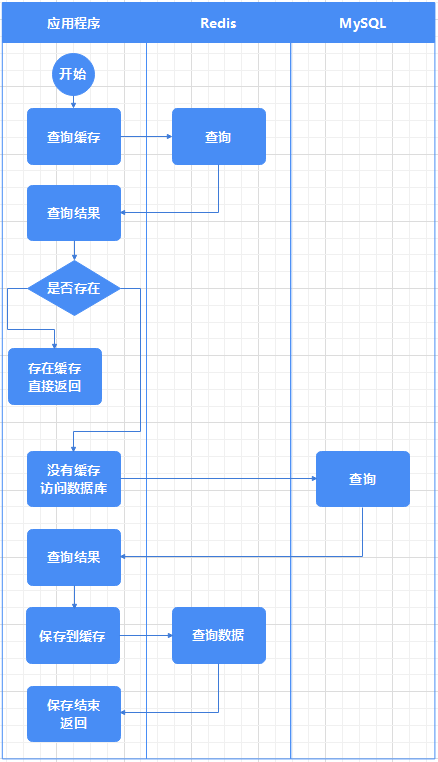
1.写代码时思路
-
应用程序向Redis查询数据
-
判断Key是否存在
-
是否存在
- 存在
- 把结果查询出来
- 返回数据给应用程序
- 不存在
- 从MySQL查询数据
- 把数据返回给应用程序
- 把结果缓存到Redis中
- 存在
三、 基于Docker安装Redis单机版
1. 拉取镜像
docker pull redis:6.2.6
2. 创建并启动容器
--restart always 表示启动Docker时自动启动此容器。
docker run -d --name redis -p 6379:6379 --restart always redis:6.2.6
3. 客户端测试
连接到容器:
docker exec -it redis bash
进入容器后。在任意目录在输入redis-cli 即可进入redis命令行。
也可以直接进入redis客户端工具:
docker exec -it redis redis-cli
四、 Redis数据类型(面试问题)
Redis中数据是key-value形式。不同类型Value是有不同的命令进行操作。
- String 字符串
- Hash 哈希表
- List 列表
- Set 集合
- Sorted Set 有序集合
- Stream类型(Redis5以后新版本类型)
Redis命令相关手册有很多,下面为其中比较好用的两个,Redis中命令有很多,抽取出部分进行讲解。
https://www.redis.net.cn/order/
http://doc.redisfans.com/
1. Key操作
1.1 exists
判断key是否存在。
语法:exists key
返回值:存在返回数字,不存在返回0
1.2 expire
设置key的过期时间,单位秒
语法:expire key 秒数
返回值:成功返回1,失败返回0
1.3 ttl
查看key的剩余过期时间
语法:ttl key
返回值:返回剩余时间,如果不过期返回-1
1.4 del
根据key删除键值对。
语法:del key
返回值:被删除key的数量
1.5 keys
命令: keys *
查看所有存在的key
1.6 scan
SCAN 命令是一种更安全的方法,它可以迭代地查找匹配的key,并且不会阻塞Redis服务器。SCAN 命令返回一个游标和匹配的key列表。你可以通过重复调用SCAN 命令直到游标为0来遍历所有的key。
SCAN cursor [MATCH pattern] [COUNT count]
cursor:初始时通常设置为 0MATCH:指定模式,用于匹配 keyCOUNT:每次迭代返回的大致 key 的数量
2. 字符串值(String)
2.1 set
设置指定key的值。如果key不存在是新增效果,如果key存在是修改效果。键值对是永久存在的。
语法:set key value
返回值:成功OK
2.2 get
获取指定key的值
语法:get key
返回值:key的值。不存在返回nil
2.3 setnx
当且仅当key不存在时才新增。恒新增,无修改功能。
语法:setnx key value
返回值:不存在时返回1,存在返回0
2.3.1 常见应用场景
利用setnx特性实现分布式锁效果。在编写代码时如果调用setnx能够成功新增,说明还没有新增过内容,认为没有人获得锁,可以继续执行自己的任务。直到删除该key认为释放了锁。
setnx();// 加锁
// 代码
del();//解锁。
如果在并发访问时第一个线程setnx()时发现没有指定key会正常向下运行。其他线程在执行setnx()时发现有这个key就会等待,等待第一个线程删除key时才会继续向下执行。
锁:在Java中可以通过锁,让多线程执行时某个代码块或方法甚至类是线程安全的。通俗点说:一个线程访问,别的线程需要等待。
线程锁:同一个应用。多线程访问时添加的锁。synchronized(自动释放)或Lock(手动释放)
进程锁:不同进程(一个进程就是一个应用)需要访问同一个资源时,可以通过添加进程锁进行实现。
分布式锁:在分布式项目中不同项目访问同一个资源时,可以通过添加分布式锁保证线程安全。常见的分布式锁有两种:Redis的分布式锁和Zookeeper的分布式锁(通过调用Zookeeper的API给Zookeeper集群添加一个节点。如果节点能添加继续向下执行,执行结束删除该节点。如果其他线程发现该节点已经添加,会阻塞等待该节点删除才继续向下执行。)。
2.4 setex
设置key的存活时间,无论是否存在指定key都能新增,如果存在key覆盖旧值。同时必须指定过期时间。
语法:setex key seconds value
返回值:OK
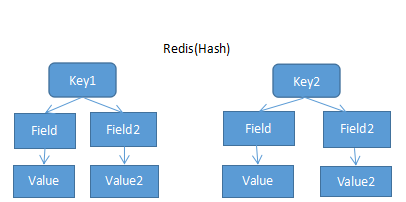
3. 哈希表(Hash)
Hash类型的值中包含多组field value。
3.1 hset
给key中field设置值。
语法:hset key field value /hset field key value
返回值:成功1,失败0
3.2 hget
获取key中某个field的值
语法:hget key field
返回值:返回field的内容
3.3 hmset
给key中多个filed设置值
语法:hmset key field value field value
返回值:成功OK
3.4 hmget
一次获取key中多个field的值
语法:hmget key field field
返回值:value列表
3.5 hvals
获取key中所有field的值
语法:hvals key
返回值:value列表
3.6 hgetall
获取所有field和value
语法:hgetall key
返回值:field和value交替显示列表
3.7 hdel
删除key中任意个field
语法:hdel key field field
返回值:成功删除field的数量
4. 列表(List)

key value1 value2 value3 value4
4.1 Rpush
向列表末尾中插入一个或多个值
语法;rpush key value1 value2
返回值:列表长度
4.2 lrange
返回列表中指定区间内的值。可以使用-1代表列表末尾
语法:lrange list 0 -1
返回值:查询到的值
4.3 lpush
将一个或多个值插入到列表前面
语法:lpush key value1 value2
返回值:列表长度
4.4 llen
获取列表长度
语法:llen key
返回值:列表长度
4.5 lrem
删除列表中元素。count为正数表示从左往右删除的数量。负数从右往左删除的数量。
语法:lrem key count value
返回值:删除数量。 注意这个value需要和删除元素value一致才可以删除
5. 集合(Set)
set和java中set集合类似。不允许重复值,如果插入重复值,后新增返回结果为0。
5.1 sadd
向集合中添加内容。不允许重复。
语法:sadd key value value value
返回值:集合长度
5.2 scard
返回集合元素数量
语法:scard key
返回值:集合长度
5.3 smembers
查看集合中元素内容
语法:smembers key
返回值:集合中元素
6. 有序集合(Sorted Set)
有序集合中每个value都有一个分数(score),根据分数进行排序。
6.1 zadd
向有序集合中添加数据
语法:zadd key score value score value
返回值:长度
6.2 zrange
返回区间内容,withscores表示带有分数
语法:zrange key 区间 [withscores]
返回值:值列表
7. 流类型(Stream)
Stream类型从Redis 5 出现的。
内容操作时命令都是以x开头的命令。详细可参考:https://redis.io/commands
7.1 xadd
语法: xadd key id field value [field value]
id可以使用固定值,也可以使用(自动生成)。新添加的ID值必须大于已经存在的ID值。
示例:
xadd sxt 1 name “sxt”
xadd sxt name “sxt” age 12
7.2 xrange
根据ID查询出内容。
语法:xrange key ID开始值 ID结束值。
- 代表最小值
- 代表最大值
ID的取值为大于零的整数。
示例:
xrange sxt 0 10 // 查询出id为0到10的
xrange sxt 0 + // 查询出ID从0到最大值
xrange sxt - + // 查询出所有
五、 Redis持久化策略(面试问题)
Redis不仅仅是一个内存型数据库,还具备持久化能力。
Redis每次启动时都会从硬盘存储文件中把数据读取到内存中。运行过程中操作的数据都是内存中的数据。
一共包含两种持久化策略:RDB 和 AOF
1. RDB(Redis DataBase)
rdb模式是默认模式,可以在指定的时间间隔内生成数据快照(snapshot),默认保存到dump.rdb文件中。当redis重启后会自动加载dump.rdb文件中内容到内存中。用户可以使用SAVE(同步)或BGSAVE(异步)手动保存数据。
可以设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令,可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。
例如:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行。计时单位是必须要执行的时间,save 900 1 ,每900秒检测一次。在并发量越高的项目中Redis的时间参数设置的值要越小。
服务器在900秒之内,对数据库进行了至少1次修改
服务器在300秒之内,对数据库进行了至少10次修改
服务器在 60秒之内,对数据库进行了至少10000次修改。
1.1 优点
rdb文件是一个紧凑文件,直接使用rdb文件就可以还原数据。
数据保存会由一个子进程进行保存,不影响父进程做其他事情。
恢复数据的效率要高于aof
1.2 缺点
每次保存点之间导致redis不可意料的关闭,可能会丢失数据。
由于每次保存数据都需要fork()子进程,在数据量比较大时可能会比较耗费性能。
2. AOF(AppendOnly File)
AOF默认是关闭的,需要在配置文件redis.conf中开启AOF。Redis支持AOF和RDB同时生效,如果同时存在,AOF优先级高于RDB(Redis重新启动时会使用AOF进行数据恢复)
AOF原理:监听执行的命令,如果发现执行了修改数据的操作,直接同步到数据库文件中,同时会把命令记录到日志中。即使突然出现问题,由于日志文件中已经记录命令,下一次启动时也可以按照日志进行恢复数据,由于内存数据和硬盘数据实时同步,即使出现意外情况也需要担心。
2.1 优点
相对RDB数据更加安全。
2.2 缺点
相同数据集AOF要大于RDB。
相对RDB可能会慢一些。
2.3 开启办法
修改redis.conf中。这个文件需要自己创建放到 /usr/local/redis目录下
appendonly yes 开启aof
appendfilename 设置aof数据文件,名称随意。
# 默认no
appendonly yes
# aof文件名
appendfilename "appendonly.aof"
六、Redis 的过期删除策略
Redis中的过期删除策略是指在键(key)上设置了过期时间后,Redis在某个条件触发时会自动删除过期的键。
Redis中有两种过期删除策略:
1.定期删除策略(定时任务方式):Redis会定期地(默认每秒钟检查10次)随机抽取一部分设置了过期时间的键,检查它们是否过期,如果过期删除。该策略可以通过配置文件中的hz参数进行调整。
2.惰性删除策略:当访问一个键时,Redis会先检查该键是否过期,如果过期则删除。这意味着过期键可能会在访问时会被删除,而不是在过期时立即删除。
七、Redis的内存淘汰策略
当 Redis(运行)内存被使用完时,也就是当Redis 的运行内存,已经超过Redis 设置的最大内存之后,Redis将采用内存淘汰机制来删除符合条件的键值对,以此来保障Redis的正常运行。
7.1 内存淘汰策略
早期版本的Redis有以下6种淘汰机制(也叫做内存淘汰策略):
- noevication:不淘汰任何数据,当内存不足时,新增操作会报错,Redis默认内存淘汰策略;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-random:随机淘汰任意键值;
- volatile-lru:淘汰所有设置了过期时间的键值中最久未使用的键值对;
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值
在Redis 4.0 版本中又新增了2种淘汰机制:
- vilation-lfu:淘汰所有设置了过期时间的键值中,最少使用的键值;
- allkeys-lfu:淘汰整个键值中最少使用的键值。
其中allkeys-xxx 表示从所有的键值中淘汰数据,而volatile-xxx 表示从设置了过期键的键值中淘汰数据。
所以,现在Redis的版本中有8种内存淘汰策略。
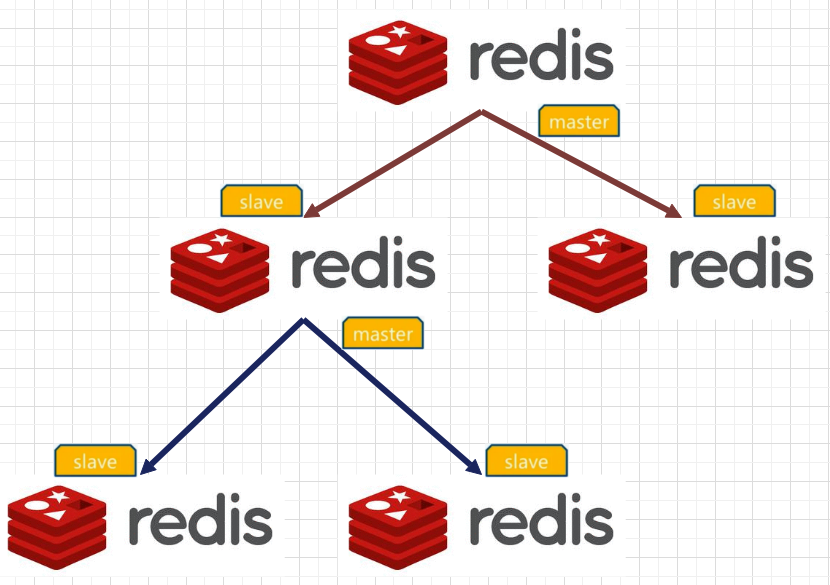
八、 Redis主从复制
Redis支持集群功能。为了保证单一节点可用性,redis支持主从复制功能。每个节点有N个复制品(replica),其中一个复制品是主(master),另外N-1个复制品是从(Slave),也就是说Redis支持一主多从。一个主可有多个从,而一个从又可以看成主,它还可以有多个从。
1. 主从优点
增加单一节点的健壮性,从而提升整个集群的稳定性。(Redis中当超过1/2节点不可用时,整个集群不可用)从节点可以对主节点数据备份,提升容灾能力。
读写分离。在redis主从中,主节点一般用作写(具备读的能力),从节点只能读,利用这个特性实现读写分离,写用主,读用从。
2. 基于Docker一主多从搭建
2.1 拉取redis镜像
docker pull redis:6.2.6
2.2 创建并运行三个Docker容器
先停止单机版Redis。单机版Redis端口6379
三个容器分别占用系统的6379、6380、6381端口
docker run --name redis1 -p 6379:6379 -v /opt/redis:/data -d redis:6.2.6
docker run --name redis2 -p 6380:6379 -v /opt/redis:/data -d redis:6.2.6
docker run --name redis3 -p 6381:6379 -v /opt/redis:/data -d redis:6.2.6
2.3 在从中指定主的ip和端口
进入redis2容器内部设置主的ip和端口
docker exec -it redis2 redis-cli
slaveof 192.168.8.128 6379
exit
进入redis3容器内部设置主的ip和端口
docker exec -it redis3 redis-cli
slaveof 192.168.108.128 6379
exit
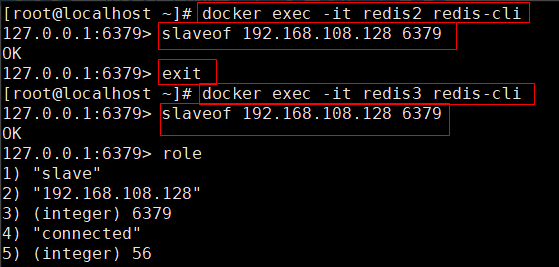
2.4 测试主从效果
进入redis1容器内部,新增key-value
docker exec -it redis1 redis-cli
set name "bjsxt"
exit
分别进入redis2和redis3容器,查看是否有name键
docker exec -it redis2 redis-cli
get name
exit
docker exec -it redis3 redis-cli
get name
exit
八、 哨兵(Sentinel)
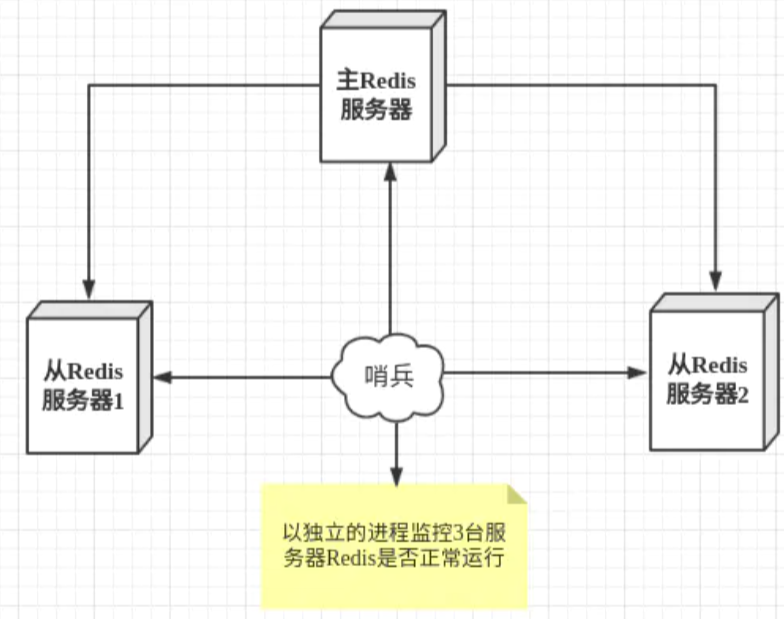
1. 概念介绍
在redis主从默认只有主具备写的能力,而从只能读。如果主宕机,整个节点不具备写能力。但是如果这是让一个从变成主,整个节点就可以继续工作。即使之前的主恢复过来也当做这个节点的从即可。Redis的哨兵就是帮助监控整个节点的,当节点主宕机等情况下,帮助重新选取主。Redis中哨兵支持单哨兵和多哨兵。单哨兵是只要这个哨兵发现master宕机了,就直接选取另一个master。而多哨兵是根据我们设定,达到一定数量哨兵认为master宕机后才会进行重新选取主。
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象c称为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这个过程对于客户端而言,一切都是透明的。
九、 Redis集群(Cluster)
1. 集群原理
- 集群搭建完成后由集群节点平分(不能平分时,前几个节点多一个槽)16384个槽。
- 客户端可以访问集群中任意节点。所以在写代码时都是需要把集群中所有节点都配置上。
- 当向集群中新增或查询一个键值对时,会对Key进行Crc16算法得出一个小于16384值,这个值就是放在哪个槽中,在判断槽在哪个节点上,然后就操作哪个节点。
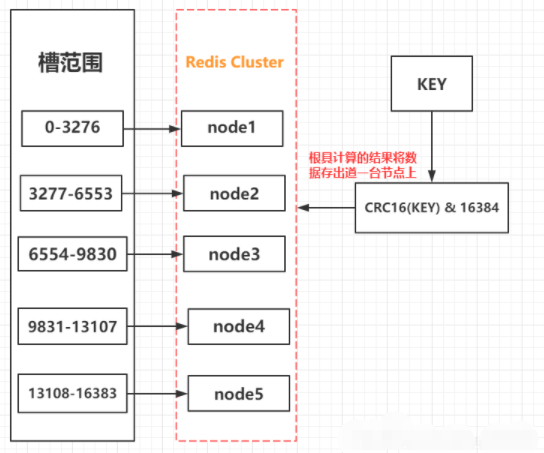
集群:集群中所有节点都安装在不同服务器上。
伪集群:所有节点都安装在一台服务器上,通过不同端口号进行区分不同节点。
当集群中超过或等于1/2节点不可用时,整个集群不可用。为了搭建稳定集群,都采用奇数节点。
Redis每个节点都支持一主多从。会有哨兵监控主的状态。如果出现(配置文件中配置当多少个哨兵认为主失败时)哨兵发现主不可用时会进行投票,投票选举一个从当作主,如果后期主恢复了,主当作从加入节点。在搭建redis集群时,内置哨兵策略。
演示时:创建3个节点,每个节点搭建一主一从。一共需要有6个redis。
2. Redis集群安装步骤
2.1 新建配置模板文件
cd /usr/local
mkdir redis-cluster
cd redis-cluster
vim redis-cluster.tmpl
下面IP部分需要修改为自己的IP
port ${PORT}
# 设置外部网络连接redis服务
protected-mode no
# 开启集群
cluster-enabled yes
# Redis群集节点每次发生更改时自动保留群集配置(基本上为状态)的文件
cluster-config-file nodes.conf
# 节点超时时间
cluster-node-timeout 5000
# 当前IP地址
cluster-announce-ip 192.168.8.128
cluster-announce-port ${PORT}
cluster-announce-bus-port 1${PORT}
# 持久化方式
appendonly yes
2.2 使用Shell脚本创建6个目录
for port in `seq 7000 7005`; do \
mkdir -p ./${port}/conf \
&& PORT=${port} envsubst < ./redis-cluster.tmpl > ./${port}/conf/redis.conf \
&& mkdir -p ./${port}/data; \
done
2.3 创建桥连网络
docker network create redis-net
查看网络是否创建成功
docker network ls

2.4 创建并启动6个容器
for port in `seq 7000 7005`; do \
docker run -d -ti -p ${port}:${port} -p 1${port}:1${port} \
-v /usr/local/redis-cluster/${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf \
-v /usr/local/redis-cluster/${port}/data:/data \
--name redis-${port} --net redis-net \
--sysctl net.core.somaxconn=1024 redis:6.2.6 redis-server /usr/local/etc/redis/redis.conf; \
done
2.5 查看6个容器ip及端口
docker inspect redis-7000 redis-7001 redis-7002 redis-7003 redis-7004 redis-7005 | grep IPAddress
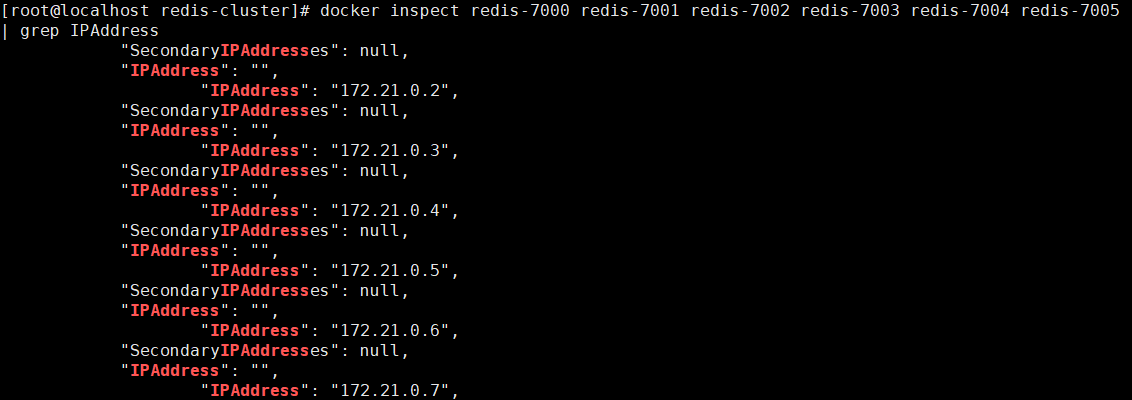
2.6 执行集群脚本
进入6个容器中任意一个。示例中以redis-7000举例
docker exec -it redis-7000 bash
执行创建脚本命令。 --cluster-relicas 1表示每个主有1个从,下面ip一定要和上面看见的ip一样。
redis-cli --cluster create \
172.18.0.2:7000 \
172.18.0.3:7001 \
172.18.0.4:7002 \
172.18.0.5:7003 \
172.18.0.6:7004 \
172.18.0.7:7005 \
--cluster-replicas 1
输入后给出集群信息,输入yes后创建集群
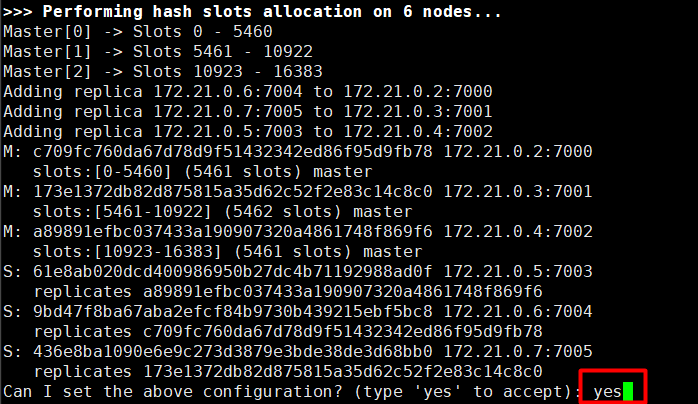
2.7 验证集群
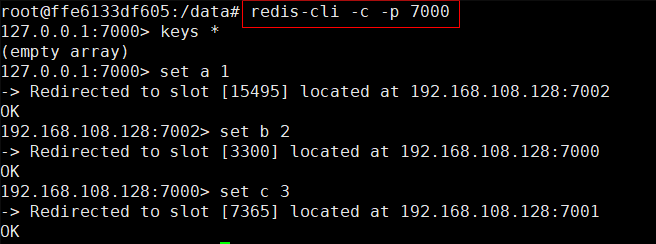
在任意Redis容器内部,进入Redis客户端工具。
示例中还是以Redis-7000举例。
redis-cli -c -p 7000
| 参数名 | 参数含义 |
|---|---|
| -c | 以集群方式进入。默认连接单机版Redis。 |
| -p | 指定端口。默认进入的是6379端口 |
十、Redis6的新特性
1. ACL权限控制
Redis ACL是Access Control List(访问控制列表)的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。
在Redis 5版本之前,Redis安全规则只有密码控制,还有通过rename 来调整高危命令比如 flushdb , KEYS * , shutdown 等。
Redis 6 则提供ACL的功能对用户进行更细粒度的权限控制 :
- 接入权限:用户名和密码
- 可以执行的命令
- 可以操作的 KEY
1.1 acl命令
使用acl list命令展现用户权限列表

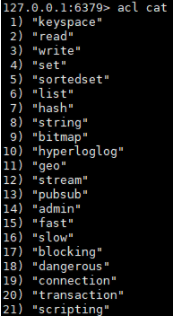
1.2 使用acl cat命令
查看添加权限指令类别
1.3 通过命令创建新用户默认权限
acl setuser user1
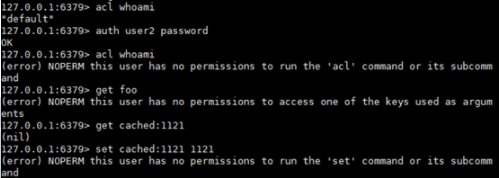
在上面的示例中,我根本没有指定任何规则。如果用户不存在,这将使用just created的默认属性来创建用户。如果用户已经存在,则上面的命令将不执行任何操作。
1.4 设置有用户名、密码、ACL权限、并启用的用户
acl setuser user2 on >password ~cached:* +get
1.5 切换用户,验证权限
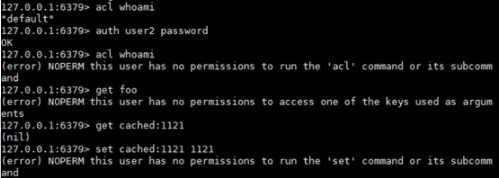
2.多线程IO
redis 6.0 提供了多线程的支持,redis 6 以前的版本,严格来说也是多线程,只不过执行用户命令的请求时单线程模型,还有一些线程用来执行后台任务, 比如 unlink 删除 key,rdb持久化等。
redis 6.0 提供了多线程的读写IO,但是最终执行用户命令的线程依然是单线程的,这样就没有多线程数据的竞争关系,依然很高效。
2.1代码演示:
redis 6.0 线程执行模式,可以通过如下参数配置多线程模型:
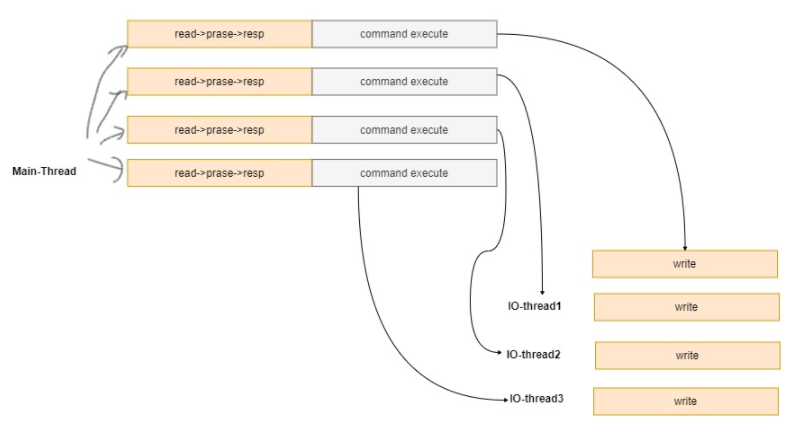
io-threads 4 // 这里说 有三个IO 线程,还有一个线程是main线程,main线程负责IO读写和命令执行操作
默认情况下,如上配置,有三个IO线程, 这三个IO线程只会执行 IO中的write 操作,也就是说,read 和 命令执行 都由main线程执行。最后多线程将数据写回到客户端。
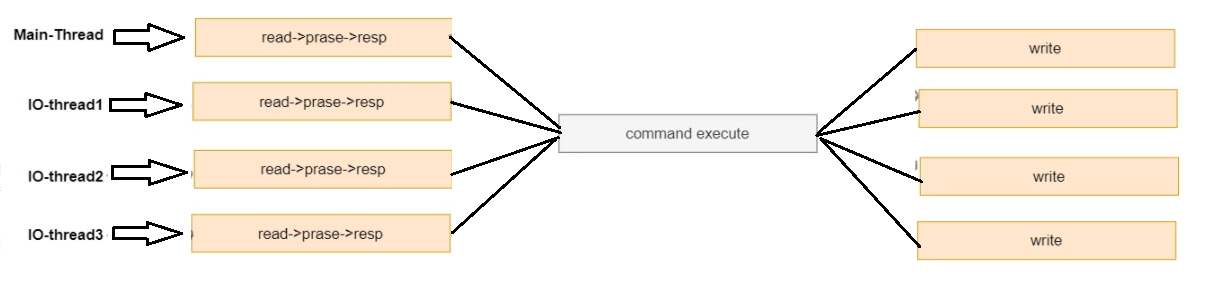
开启了如下参数:
io-threads-do-reads yes // 将支持IO线程执行 读写任务。
3.RESP3协议
RESP(Redis Serialization Protocol)是 Redis 服务端与客户端之间通信的协议。Redis 5 使用的是 RESP2,而 Redis 6 开始在兼容 RESP2 的基础上,开始支持 RESP3。
推出RESP3的目的:
- 一是因为希望能为客户端提供更多的语义化响应,以开发使用旧协议难以实现的功能;
- 另一个原因是实现 Client-side-caching(客户端缓存)功能。
4.支持SSL
连接支持SSL,更加安全。
5.提升了RDB日志加载速度
根据文件的实际组成(较大或较小的值),可以预期20/30%的改进。当有很多客户机连接时,信息也更快了,这是一个老问题,现在终于解决了。
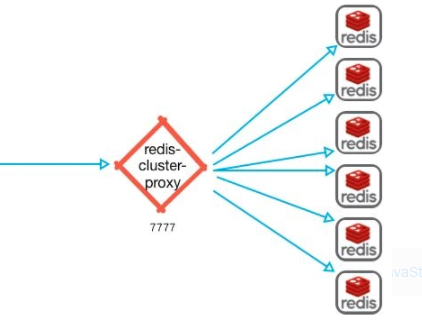
6.发布官方的Redis集群代理模块 Redis Cluster proxy
在 Redis 集群中,客户端会非常分散,现在为此引入了一个集群代理,可以为客户端抽象 Redis 群集,使其像正在与单个实例进行对话一样。同时在客户端仅使用简单命令和功能时执行多路复用。
7.提供了众多的新模块(modules)API
具体参考:https://redis.io/topics/modules-api-ref
十一、 高并发下Redis可能存在的问题及解决方案
1. 缓存穿透(面试问题)
在实际开发中,添加缓存工具的目的,减少对数据库的访问次数,提高访问效率。
肯定会出现Redis中不存在的缓存数据。例如:访问id=-1的数据。可能出现绕过redis依然频繁访问数据库的情况,称为缓存穿透,多出现在数据库查询为null的情况不被缓存时。
解决办法:
把查询出null的数据在Redis中仍然保存一份
布隆过滤器
1.1设置有效时间
如果查询出来为null数据,把null数据依然放入到redis缓存中,同时设置这个key的有效时间比正常有效时间更短一些。
if(list==null){
// key value 有效时间 时间单位
redisTemplate.opsForValue().set(navKey,null,10, TimeUnit.MINUTES);
}else{
redisTemplate.opsForValue().set(navKey,result,7,TimeUnit.DAYS);
}
1.2 布隆过滤器
布隆过滤器(Bloom Filter):是一种空间效率极高的概率型算法和数据结构,用于判断一个元素是否在集合中(类似Hashset)。它的核心一个很长的二进制向量和一系列hash函数,数组长度以及hash函数的个数都是动态确定的。其内部维护一个全为0的bit数组布隆过滤器由一个初值都为 0 的 bit 数组和 N 个哈希函数组成,可以用来快速判断某个数据是否存在。当我们想标记某个数据存在时(例如,数据已被写入数据库),布隆过滤器会通过三个操作完成标记:
-
首先,使用 N 个哈希函数,分别计算这个数据的哈希值,得到 N 个哈希值。
-
然后,我们把这 N 个哈希值对 bit 数组的长度取模,得到每个哈希值在数组中的对应位置。
-
最后,我们把对应位置的 bit 位设置为 1,这就完成了在布隆过滤器中标记数据的操作。
如果数据不存在(例如,数据库里没有写入数据),我们也就没有用布隆过滤器标记过数据,那么,bit 数组对应 bit 位的值仍然为 0。
当需要查询某个数据时,我们就执行刚刚说的计算过程,先得到这个数据在 bit 数组中对应的 N 个位置。紧接着,我们查看 bit 数组中这 N 个位置上的 bit 值。只要这 N 个 bit 值有一个不为 1,这就表明布隆过滤器没有对该数据做过标记,所以,查询的数据一定没有在数据库中保存。为了便于你理解,我画了一张图,你可以看下。
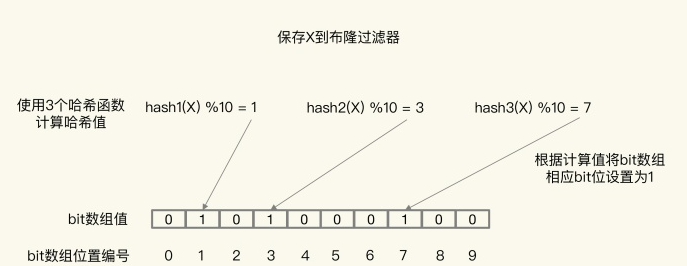
图中布隆过滤器是一个包含 10 个 bit 位的数组,使用了 3 个哈希函数,当在布隆过滤器中标记数据 X 时,X 会被计算 3 次哈希值,并对 10 取模,取模结果分别是 1、3、7。所以,bit 数组的第 1、3、7 位被设置为 1。当应用想要查询 X 时,只要查看数组的第 1、3、7 位是否为 1,只要有一个为 0,那么,X 就肯定不在数据库中。
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询 Redis 和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布隆过滤器可以使用 Redis 实现,本身就能承担较大的并发访问压力。
@Service
public class RedisSnowSlideServiceImpl implements RedisSnowSlideService {
private static final Logger logger = LoggerFactory.getLogger(RedisSnowSlideServiceImpl.class);
@Autowired
private UserMapper userMapper;
@Autowired
private RedisTemplate<Integer, String> redisTemplate;
private static Integer size = 1000000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
/**
* 布隆过滤器
*/
@Override
public UserInfo getUser(Integer id) {
//1 先从redis里面查数据
String userInfoStr = redisTemplate.opsForValue().get(id);
if (isEmpty(userInfoStr)) {
//校验是否在布隆过滤器中
if (bloomFilter.mightContain(id)){
return null;
}
synchronized (RedisSnowSlideServiceImpl.class){
//查询下缓存
userInfoStr = redisTemplate.opsForValue().get(id);
logger.info("1---【开始】查询数据库--------------");
// 查数据库
UserInfo userInfo = userMapper.findById(id);
if (Objects.isNull(userInfo)) {
// 将id对应的空值放入布隆过滤器
bloomFilter.put(id);
}
userInfoStr = JSON.toJSONString(userInfo);
logger.info("2---【结束】查询数据库--------------");
redisTemplate.opsForValue().set(id, userInfoStr);
}
}
return JSON.parseObject(userInfoStr, UserInfo.class);
}
2. 缓存击穿(面试问题)
实际开发中,考虑redis所在服务器中内存压力,都会设置key的有效时间。一定会出现键值对过期的情况。如果正好key过期了,此时出现大量并发访问,这些访问都会去访问数据库,这种情况称为缓存击穿。
解决办法:
永久数据。加锁。防止出现数据库的并发访问。
2.1 ReentrantLock(重入锁)
JDK对对于并发访问处理的内容都放入了java.util.concurrent中,ReentrantLock性能和synchronized没有区别的,但是API使用起来更加方便。
2.1.1 重入锁和非重入锁?
无论是重入还是非重入都是在一个线程中(直接体现一定出现一个方法(A)调用另外一个方法(B)。)当A方法获取锁后,调用的B方法是否能获取锁就是他们区别。如果B方法能获取到锁对象就叫重入锁。如果B方法无法获取锁对象就叫非重入锁。在Java JDK中提供的锁都是重入锁。
2.2 解决缓存击穿实例代码
只有在第一次访问时和Key过期时才会访问数据库。对于性能来说没有过大影响,因为平时都是直接访问redis。
private ReentrantLock lock = new ReentrantLock();
@Override
public Item selectByid(Integer id) {
lock.lock();
String key = "item:"+id;
if(redisTemplate.hasKey(key)){
lock.unlock();
return (Item) redisTemplate.opsForValue().get(key);
}
if(lock.isLocked()) {
Item item = itemDubboService.selectById(id);
// 由于设置了有效时间,就可能出现缓存击穿问题
redisTemplate.opsForValue().set(key, item, 7, TimeUnit.DAYS);
lock.unlock();
return item;
}
// 如果加锁失败,为了保护数据库,直接返回null
return null;
}
3. 缓存雪崩(面试问题)
在一段时间内容,出现大量缓存数据失效,这段时间内容数据库的访问频率骤增,这种情况称为缓存雪崩。
解决办法:
永久生效。
自定义算法,例如:随机有效时间。让所有key尽量避开同一时间段。
int seconds = random.nextInt(10000);
redisTemplate.opsForValue().set(key, item, 100+ seconds, TimeUnit.SECONDS);
4. 边路缓存(面试问题)
cache aside pattern 边路缓存问题。从数据存储区加载到缓存中的数据,这种模式可以提高性能,也有助于保持在缓存中的数据之间的一致性和底层数据存储的数据,其实是一种指导思想,思想中包含:
- 查询的时候应该先查询缓存,如果缓存不存在,在查询数据库
- 修改缓存数据时,应先修改数据库,后删除缓存。
4.1 为什么是删除缓存,不是更新缓存?
因为在复杂的缓存场景中,缓存不单单是数据库中直接取出来的值
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
4.2 最初级的缓存不一致问题及解决方案
问题:先更新缓存,再删除缓存,若缓存更新失败,会导致数据库是新数据,缓存中是旧数据,数据就出现不一致
解决:先删除缓存,在更新数据库,数据库更新失败,那数据库中的数据是旧数据,缓存中是空的,那么不会出现数据不一致
4.3 比较复杂的数据不一致问题及解决
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改
解决:更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个 jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
5. Redis脑裂(面试问题)
Redis脑裂主要是指因为一些网络原因导致Redis Master和Redis Slave和Sentinel集群处于不同的网络分区。Sentinel连接不上Master就会重新选择Master,此时就会出现两个不同Master,好像一个大脑分裂成两个一样。
Redis集群中不同节点存储不同的数据,脑裂会导致大量数据丢失。
5.1 方案一:解决Redis脑裂只需要在Redis配置文件中配置两个参数
min-slaves-to-write 3 # 连接到master的最小slave数量
min-slaves-max-lag 10 # slave连接到master的最大延迟时间
5.2 方案二:
在不同机房中部署多个Sentinel,配置时配置数量大一些,必须绝大多数哨兵都认为Master宕掉后才选择主。这样会在一定程度上避免脑裂现象。
5.3 方案三:
如果不希望配置很多哨兵,可以吧哨兵和客户端项目部署到同一个机房(主要是为了让哨兵和客户端项目走同一个网络),项目访问主从和哨兵的架构时,必须链接哨兵,由哨兵返回主的信息,所以即使出现脑裂现象,客户端项目和哨兵要不就都能访问某个主,要不就都不能访问某个主,不会影响项目的正常运行。
6. Redis 缓存淘汰策略/当内存不足时如何回收数据/保证Redis中数据出现内存溢出情况(面试题)
6.1 何时淘汰数据
-
惰性删除(passive way):在读取数据时先判断是否过期,如果过期删除他。例如:get、hget、hmget等
-
定期删除(active way):周期性判断是否有失效内容,如果有就删除。
-
主动删除:当超过阈值时会删除。
在Redis中每次新增数据都会判断是否超过阈值。如果超过了,就会按照淘汰策略删除一些key。
6.2 淘汰策略
Redis中数据都放入到内存中。如果没有淘汰策略将会导致内存中数据越来越多,最终导致内存溢出。在Redis5中内置了缓存淘汰策略。在配置文件中有如下配置
# maxmemory-policy noeviction 默认策略noevication
# maxmemory <bytes> 缓存最大阈值
# volatile-lru -> 在设置过期key集中选择使用数最小的。
# allkeys-lru -> 在所有key中选择使用最小的。
# volatile-lfu -> 在设置过期时间key集中采用lfu算法。
# allkeys-lfu -> 在所有key中采用lfu算法。
# volatile-random -> 在设置过期key集中随机删除。
# allkeys-random -> 在所有key中随机删除。
# volatile-ttl -> 在设置了过期时间key中删除最早过期时间的。
# noeviction -> 不删除key,超过时报错。
6.2.1 LRU
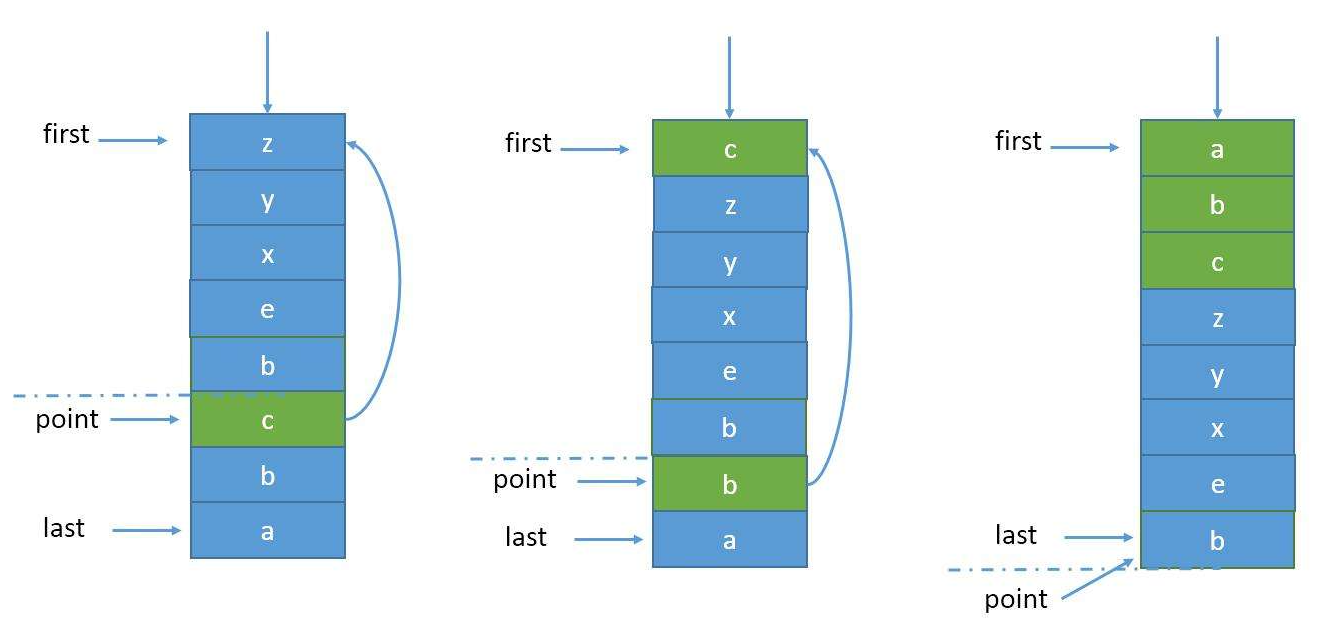
LRU (Least recently used) 最近最少使用,如果数据最近被访问过,那么将来被访问的几率也更高。LRU算法实现简单,运行时性能也良好,被广泛的使用在缓存/内存淘汰中。
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃
6.2.2 LFU
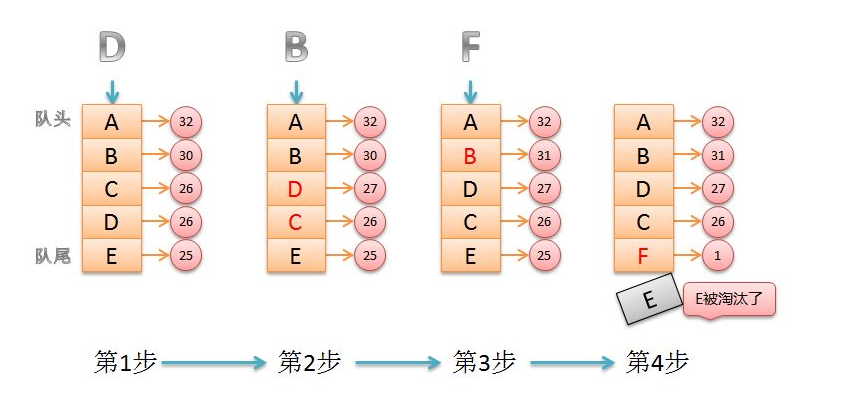
Least Frequently Used(最近最不经常使用)如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
6.2.3 FIFO
FIFO按照“先进先出(First In,First Out)”的原理淘汰数据,正好符合队列的特性,数据结构上使用队列Queue来实现
实现:
- 新访问的数据插入FIFO队列尾部,数据在FIFO队列中顺序移动;
- 淘汰FIFO队列头部的数据;
特点:
- 命中率 命中率很低,因为命中率太低,实际应用中基本上不会采用。
- 简单 实现代价很小
6.2.4 LRU和LFU的区别
-
LRU淘汰时淘汰的是链表最末尾的数据。而LFU是一段时间内访问次数最少的。
-
LRU是最近最少使用页面置换算法(Least Recently Used),也就是首先淘汰最长时间未被使用的页面!
-
LFU是最近最不常用页面置换算法(Least Frequently Used),也就是淘汰一定时期内被访问次数最少的页!
比如,第二种方法的时期T为10分钟,如果每分钟进行一次调页,主存块为3,若所需页面走向为2 1 2 1 2 3 4
注意,当调页面4时会发生缺页中断
若按LRU算法,应换页面1(1页面最久未被使用) 但按LFU算法应换页面3(十分钟内,页面3只使用了一次)
可见LRU关键是看页面最后一次被使用到发生调度的时间长短,
而LFU关键是看一定时间段内页面被使用的频率!
6.3 每次删除多少
淘汰数量量和新增数据量进行判断。

















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









