




 本文介绍索引的数据结构,对比B-TREE和B+TREE。B-TREE是多路平衡查找树,节点保存关键字和数据信息;B+TREE是加强版,非叶节点只存关键字和子节点引用,数据在叶子节点。还说明了MySQL选用B+TREE的原因,如扫库能力强、磁盘读写优、排序好、查询稳定。
本文介绍索引的数据结构,对比B-TREE和B+TREE。B-TREE是多路平衡查找树,节点保存关键字和数据信息;B+TREE是加强版,非叶节点只存关键字和子节点引用,数据在叶子节点。还说明了MySQL选用B+TREE的原因,如扫库能力强、磁盘读写优、排序好、查询稳定。
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构。实现这种数据结构方式有多种,这里只介绍B-TREE和B+TREE,并简单做个对比,最后说明MySQL数据库采用B+TREE作为索引数据结构的原因。
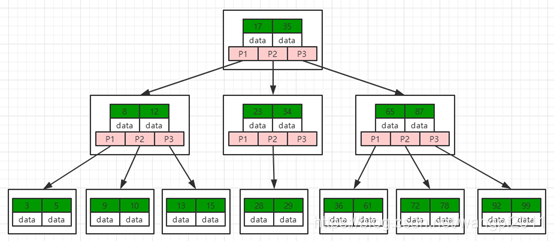
B-TREE
B-TREE也称多路平衡查找树,如果有一M路平衡查找树,那么每个节点至多可以拥有M个子节点,并且该节点关键字个数最多为M-1个,同时每个节点保存关键字对应的数据相关信息。
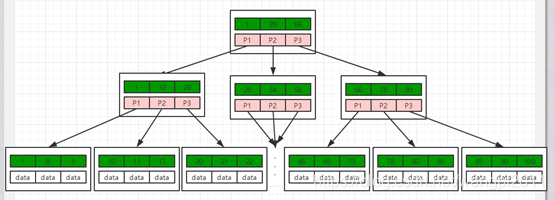
B+TREE
B+TREE是加强版多路平衡查找树,和B-TREE相比,B+TREE具有以下特点:B+TREE节点关键字搜索采用闭合区间;B+TREE非叶节点不保存数据相关信息,只保存关键字和子节点的引用;B+TREE关键字对应的数据保存在叶子节点中;B+TREE叶子节点是顺序排列的,并且相邻节点具有顺序引用的关系。
为什么选用B+TREE
1、B+TREE是B-TREE的变种(PLUS 版)多路绝对平衡查找树,他拥有B-TREE的优势。
2、B+TREE扫库/表能力更强
B-TREE由于数据是存放在每个节点上的,所有B-TREE扫库/表需要遍历每个节点,B+TREE只需要扫描叶子节点即可,并且叶子节点是顺序排列的。
3、B+TREE的磁盘读写能力更强
由于B+TREE非叶子节点中只存放关键字和指针,所以每个节点可以存放更多关键字,进而磁盘I/O更少,所以说磁盘读写能力更强。
4、B+TREE的排序能力更强
B+TREE的存储结构具有天然的排序性,所有的叶子节点是顺序排列的。
5、B+TREE的查询效率更加稳定

















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









