




 本文介绍了如何解析CASIA在线手写体数据集OLHWDB,详细讲解了与HIT-OR3C数据集的不同之处,并提供了一段完整的Python解析代码,该代码基于POTView的C++源码思路,能处理样本中笔画的采样点,自动生成样本的长宽。
本文介绍了如何解析CASIA在线手写体数据集OLHWDB,详细讲解了与HIT-OR3C数据集的不同之处,并提供了一段完整的Python解析代码,该代码基于POTView的C++源码思路,能处理样本中笔画的采样点,自动生成样本的长宽。
上一篇记录了HIT-OR3C联机数据的解析代码,由于OLHWDB不同于HIT-OR3C,其在采集联机手写体数据时就没有按照固定size去采集(HIT-OR3C保存的坐标是转换后相对128*128大小画布的相对坐标),而是一个绝对坐标(解析的第一个sample的y就有6000多,以为搞错了就扔一边了)
这周重新打开仔细研究了下官方POTView的C++源码,终于是把CASIA的OLHWDB数据解析出来了!
由于OLHWDB记录的是sample各个笔画的采样点,所以并没有记录sample的长宽,需要自己去初始化一个画布,然后把采样点描回去,所以借鉴了POTView的trajDisp的思路写了个Python版的解析代码(修改了一个点是计算xmin, ymin, xmax, ymax部分,按照源码的逻辑出现了bug)
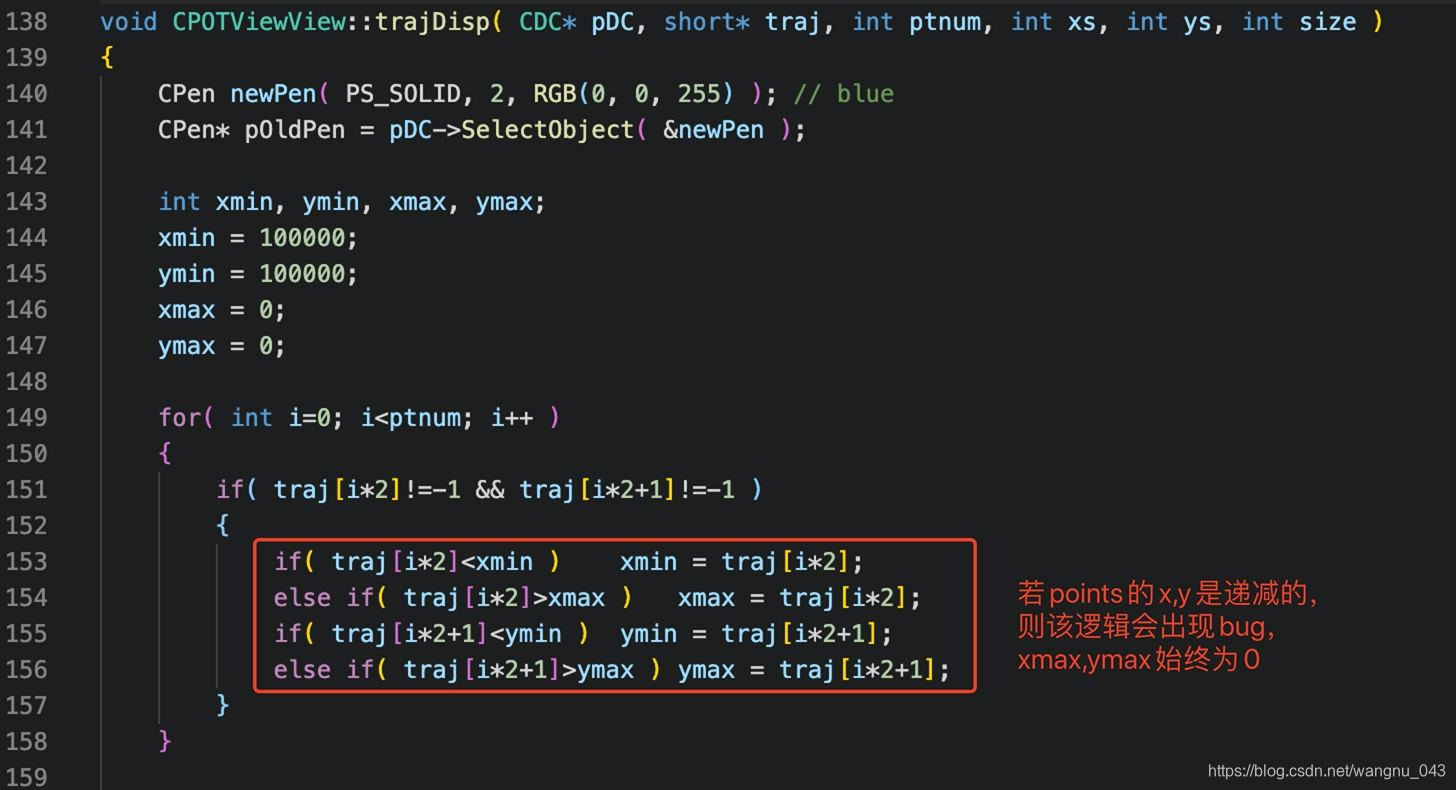
Python版解析完整代码:
import os
import os.path as osp
import numpy as np
import cv2
from PIL import Image
import struct
from tqdm import tqdm
import pickle
dataset_name = 'OLHWDB1.0'
root = osp.join('/Users/wangnu/Documents/dataset/CASIA/', dataset_name)
train_dir = osp.join(root, dataset_name+'trn_pot')
test_dir = osp.join(root, dataset_name+'tst_pot')
train_dataset = os.listdir(train_dir)
test_dataset = os.listdi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









