




 本文探讨了在不确定环境中智能体学习的挑战,如模型误差导致的次优策略。规划过程中的“试探”和“开发”是两个关键概念,前者用于发现环境变化,后者追求当前模型的最优解。预演算法和蒙特卡洛树搜索(MCTS)是两种解决策略,通过模拟和回溯更新来平衡探索和开发。MCTS通过不断模拟和聚焦于高价值路径来优化决策,其核心步骤包括选择、扩展、模拟和回溯。这些方法在动态环境中帮助智能体逐步改进策略,尽管存在权衡,但能有效应对未知和变化的环境。
本文探讨了在不确定环境中智能体学习的挑战,如模型误差导致的次优策略。规划过程中的“试探”和“开发”是两个关键概念,前者用于发现环境变化,后者追求当前模型的最优解。预演算法和蒙特卡洛树搜索(MCTS)是两种解决策略,通过模拟和回溯更新来平衡探索和开发。MCTS通过不断模拟和聚焦于高价值路径来优化决策,其核心步骤包括选择、扩展、模拟和回溯。这些方法在动态环境中帮助智能体逐步改进策略,尽管存在权衡,但能有效应对未知和变化的环境。
在随机环境中只有数量有限的样本会被观察到,或者模型通过泛化能力较差的函数来近似的,又或者仅仅因为环境发生改变且新的动态特性尚未被观察到,模型都可能不正确,从而导致规划过程中得到次优的策略。某些情况下,规划计算出的次优策略会使我们很快发现并修正模型错误。这种情况往往比较“乐观”,模型就会倾向于预测出比真实可能情况更大的收益或更好的状态转移,规划得出的策略会尝试开发这些机会,这样智能体就很快发现这些机会根本不存在,于是感知到模型的错误,继而修正错误。
阐述探索和开发之间的矛盾。
在“规划”语境中,“试探”意味着尝试那些改变模型的动作,而“开发”则意味着以当前模型的最优方式来执行动作。我们希望智能体通过试探发现环境的变化,但又不希望试探太多使得平均性能大大降低。可能并不存在既完美又实用的解决方案,但简单的启发式方法常常很有效。
优先遍历算法:
在确定性环境下的优先级遍历算法:
对所有的状态,
,初始化
和
,并初始化
为空
无限循环:
(a)当前(非终止)状态
(b)policy(S,Q)
(c)采取动作A;观察产生的收益R,以及状态S’
(d)
(e)
(f) 如果P>,那么将S,A以优先级P插入PQueue中
(g)循环n次,同时PQueue非空:
对所有的预测可以达到S的,
进行循环:
对于
,
,S预测的收益
如果P>,那么将
,
以优先级P插入PQueue中
启发式搜索:
状态空间规划方法就是决策时规划,统称为启发式搜索。在启发式搜索中,对于遇到的每个状态,我们建立一个树结构,该结构包括了后面各种可能的延续,将近似价值函数应用于叶子节点,然后以根状态向当前状态回溯更新,回溯更新在当前状态的状态动作节点处停止,计算这些节点的更新值后,选择其中最好的值作为当前的动作,舍弃所有更新值。贪心策略和UCB动作选择方法与启发式搜索并没有什么不同。可以将启发式搜索视为单步贪心策略的某种扩展。启发式搜索中算力聚焦的最明显方式:关注当前状态。
可以以聚焦于当前状态及其可能的后继状态来改变更新的算力分配。极端情况下,我们可以使用启发式搜索的方法来构建搜索树,然后从下到上执行单步回溯更新。如果以这种方式对回溯更新进行排序并使用表格型表示,那么我们将得到与深度优先的启发式搜索完全相同的回溯更新方式。
预演算法(rollout):
rollout算法是一种基于蒙特卡洛控制的决策时规划算法,这里的蒙特卡洛控制应用于以当前环境状态为起点的采样模拟轨迹。rollout算法通过平均许多起始于每一个可能的动作并遵循给定的策略的模拟轨迹的回报来估计动作价值。当动作价值的估计被认为足够准确时,对应最高估计值的动作(或多个动作中的一个)会被执行,之后这个过程再从得到的后继状态继续进行。但是预演(rollout)算法的目标不是估计一个最优动作价值函数,或对于给定策略的完整的动作价值函数。相反,它们仅仅对每一个当前状态以及一个给定的被称为预演策略的策略做出动作价值的蒙特卡洛估计。预演算法只是即时地利用这些动作价值的估计值,之后就丢弃了。预演算法的目的是为了改进预演策略的性能,而不是找到最优的策略。基础预演策略越好,价值估计越准确,预演算法得到的策略就越可能更好。但是好的预演策略需要花更多的时间,可以通过一些方法缓解,由于蒙特卡洛实验之间是相互独立的,因此可以在多个独立的处理器上并行的进行多次实验。另一个办法是在尚未完成时就截断模拟轨迹,利用预存的评估函数来更正截断的回报值。还有一种可行方法是监控蒙特卡洛模拟过程并对不太可能是最优的,或者最优值很接近的动作进行剪枝。
蒙特卡洛搜索树:
MCTS的核心思想是从当前状态出发的多个模拟轨迹不断地聚焦和选择,这是通过扩展模拟轨迹中获得较高评估值的初始片段来实现的,而这些评估值则是根据更早的模拟样本计算的。MCTS不需要保存近似价值函数或每次动作选择的策略。不过在很多实现中还是会保存选中的动作价值,在下一次的执行中很可能会有用。在计算过程中,我们只维护部分的蒙特卡洛估计值,这些估计值对应于会在几步内到达的“状态-动作”二元组所形成的子集,这就形成了一颗以当前状态为根节点的树。MCTS会增量式的逐步增加节点来进行树扩展,这些节点代表了从模拟轨迹的结果上看前景更为光明的状态。任何模拟轨迹都会沿着这棵树运行,最后从某个叶子节点离开。在树的外部利用预演策略选择动作,在树的内部,对于内部状态至少对部分动作有价值估计,所以我们可以用一个知晓这些信息的策略来选取,这个策略称为树策略,它能够平衡试探和开发,树策略有贪心策略或UCB选择规则来选择动作。
基本版的MCTS的每次循环包括下面四个步骤(流程如下图所示):
1、选择。从根节点开始,使用基于树边缘的动作价值的树策略遍历这棵树来挑选一个叶子节点
2、扩展。在某些循环中,针对选定的叶子节点找到采取非试探性动作可以达到的节点,将一个或多个这样的节点加为该叶子节点的子节点,以此来实现树的扩展。
3、模拟。从选定的节点,或其中一个它新增的子节点(如果存在)出发,根据预演策略选择动作进行整个轨迹模拟,动作首先由树策略选取,而到了树外则由预演策略选取。
4、回溯。模拟整个轨迹得到的回报值向上回传,对此次循环中,树策略所遍历的树边缘上的动作价值进行更新或初始化。预演策略在树外部访问到的状态和动作的任何值都不会 被保存下来。
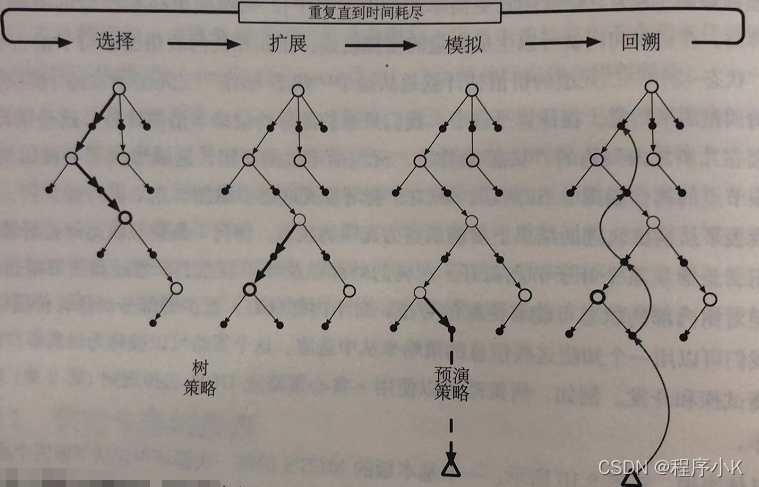
图蒙特卡洛树搜索,当环境转移到一个新的状态树,MCTS会在动作被选择前执行尽可能多次迭代,逐渐构建一个以根为当前状态的树,每一次迭代又包括四步:选择,扩展,模拟,回溯。


















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











