






 本文介绍如何使用Python编写脚本,通过PyMySQL库连接MySQL数据库,批量插入数据并确保ID递增。脚本详细展示了连接配置、数据构造和错误处理的过程,最终实现向表中添加10条数据并收集所有ID。
本文介绍如何使用Python编写脚本,通过PyMySQL库连接MySQL数据库,批量插入数据并确保ID递增。脚本详细展示了连接配置、数据构造和错误处理的过程,最终实现向表中添加10条数据并收集所有ID。
目录
1、前言
针对在数据库里进行批量造数据,之前有发过一篇文章 MySQL大批量造数据,是使用存储过程的方法进行批量造数据的。
本篇将采用 Python 脚本的方式进行批量造数据。
2、脚本批量造数据
为了使 Python 可以连上数据库(MySQL),并且可以与数据库交互(增删改查等操作),则需要安装 MySQL 客户端操作库,Python2 中使用 MySQLdb,Python3 中使用 PyMySQL。
作者使用环境为 Python3.8,则安装 PyMySQL 即可。
命令行安装命令:
pip install pymysql1、首先要脚本需求的定义:
连接数据库,往指定的表里批量造数据,要求 id 为递增,数据造完后,将所有的 id 收集在一起,为后续使用。
2、接下来开始进行脚本的编写:
(1)先要进行数据库的连接设置(用户名、密码、数据库服务地址、数据库库名)。
(2)接下来定义一个变量 my_id_total,为字符串类型,用于对所有的 id 汇总。之后就是一个 for 循环体,所有的操作都在这里。range(10) 为设置循环10次;try 语句里为执行的 SQL 语句;变量 my_id 每次迭代会递增一次;最后加了一段 time.sleep(0.1) 是怕脚本执行的太快,可能会导致脚本报错而加的。
(3)最后关闭数据库即可。
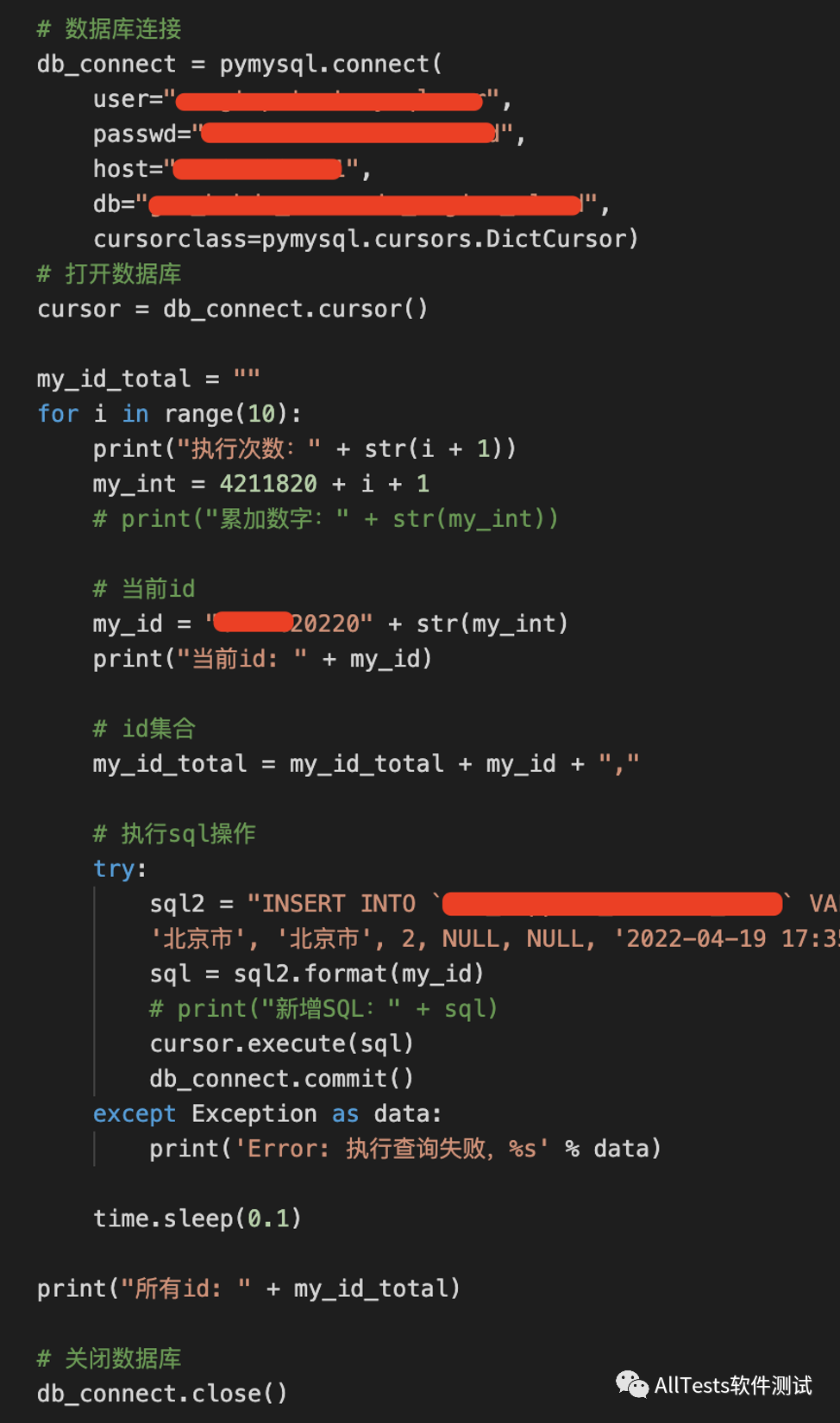
3、运行结果:
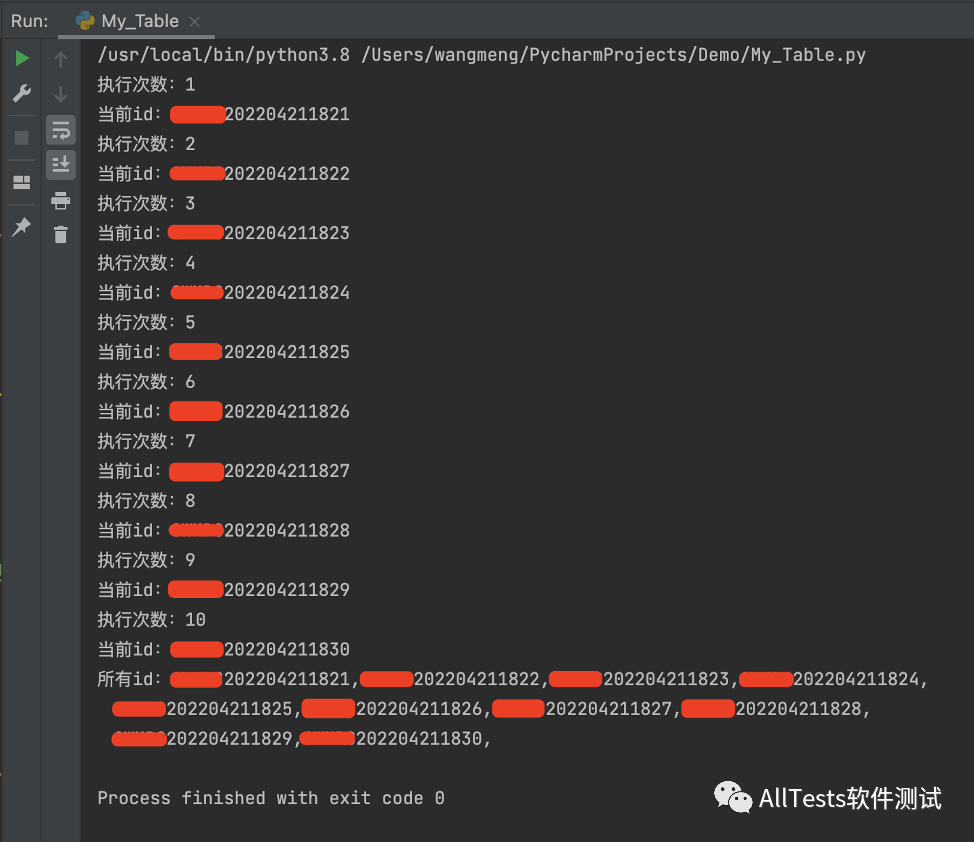
查看数据库,可以看到新增了10条数据。
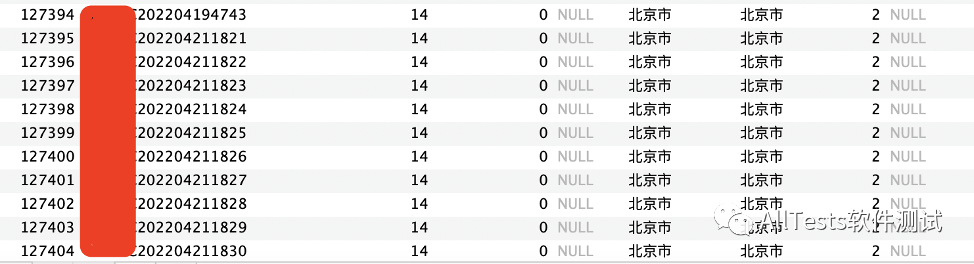
4、脚本模板:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 公众号:AllTests软件测试
import pymysql
import time
# 批量新增数据
def insert_data():
# 数据库连接
db_connect = pymysql.connect(
user="xxxxxx",
passwd="xxxxxx",
host="xxxxxx",
db="xxxxxx",
cursorclass=pymysql.cursors.DictCursor)
# 打开数据库
cursor = db_connect.cursor()
my_id_total = ""
for i in range(10):
print("执行次数:" + str(i + 1))
my_int = 4211820 + i + 1
# print("累加数字:" + str(my_int))
# 当前id
my_id = "xxxxxx20220" + str(my_int)
print("当前id: " + my_id)
# id集合
my_id_total = my_id_total + my_id + ","
# 执行sql操作
try:
sql2 = "INSERT INTO `xxxxxx` VALUES (NULL, '{}', 14, 0, NULL, '北京市', '北京市', 2, NULL, NULL, '2022-04-19 17:35:59', '2022-04-19 17:35:59');"
sql = sql2.format(my_id)
# print("新增SQL:" + sql)
cursor.execute(sql)
db_connect.commit()
except Exception as data:
print('Error: 执行查询失败,%s' % data)
time.sleep(0.1)
print("所有id: " + my_id_total)
# 关闭数据库
db_connect.close()
if __name__ == '__main__':
insert_data()精彩推荐




















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











