










背景:当下载一个很大的文件时,如果下载到一半暂停,如果继续下载呢?断点下载就是解决这个问题的。
什么是断点下载?
所谓断点下载就是可以一部分一部分的下载,不用一次性把文件数据全部拿到。
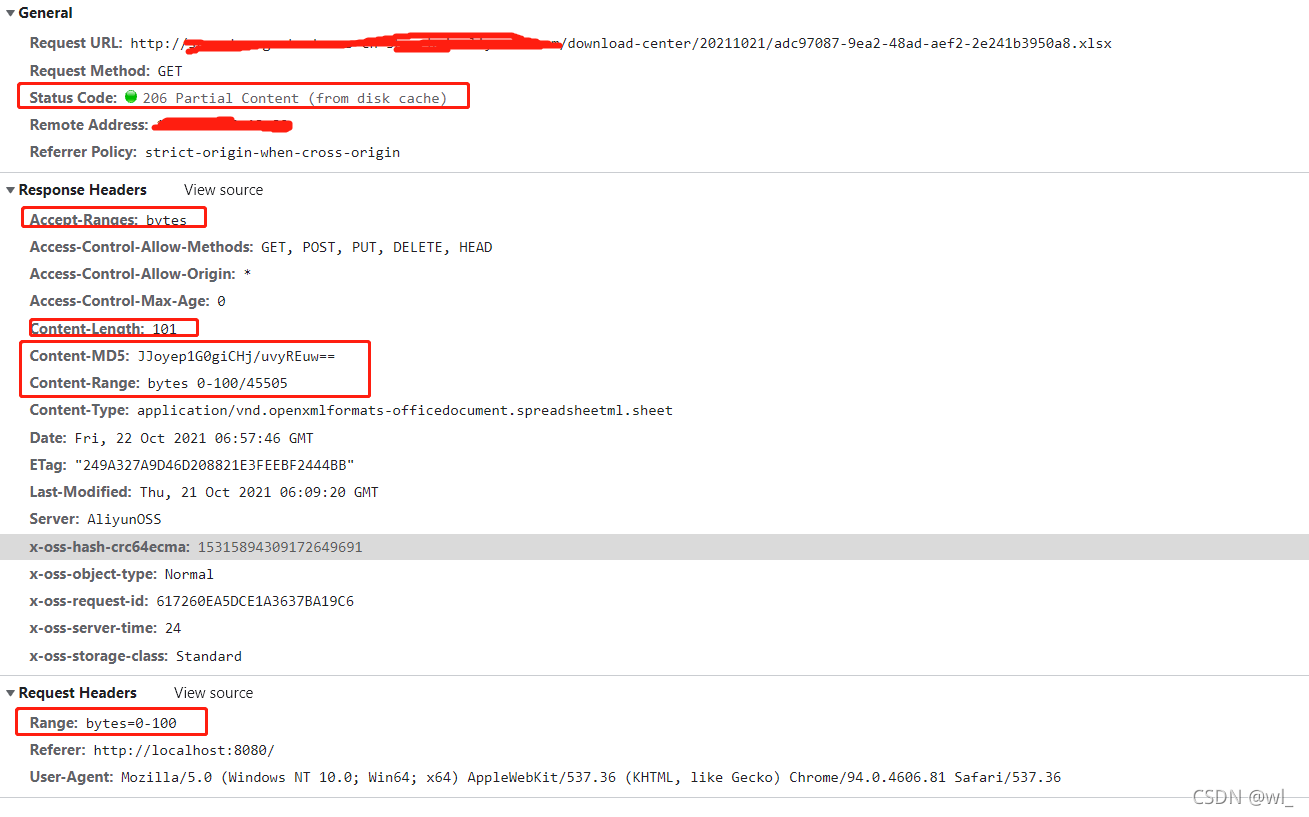
涉及到的主要HTTP消息头
| 通用首部 | 请求头 | 响应头 | 实体头 |
|---|---|---|---|
| Status Code | Range:请求数据范围 | Accept-Ranges:标识自身支持范围请求 Content-Range:一个数据片段在整个文件中的位置。 ETag:资源特定版本标识符 Last-Modified:资源修改日期时间 | Content-MD5 //实体编码摘要 |
其他可能用到的消息头:
If-Range 请求头字段用来使得 Range 头字段在一定条件下起作用
If-None-Match:如果ETag不匹配
If-Match:如果ETag匹配
HTTP HEAD方法(因为安全策略,浏览器中通过XMLHttpRequest只能获取部分头部信息)
请求资源的头部信息, 并且这些头部与 HTTP GET 方法请求时返回的一致。 该请求方法的一个使用场景是在下载一个大文件前先获取其大小再决定是否要下载, 以此可以节约带宽资源。
代码实现
1、服务端要支持范围请求,响应信息中的Accept-Ranges: bytes,表示接收以字节为单位的范围请求
2、在发送的请求信息中要加上范围请求信息,Range: bytes=0-100请求头信息,表示请求0-100字节的数据
3、通过HEAD方法来获取文件的大小
getContentLength(url) {
return new Promise(resolve => {
const xhr = new XMLHttpRequest()
xhr.open('HEAD', url)
xhr.onload = function () {
resolve(xhr.getResponseHeader('content-length') || 0)
}
xhr.send()
})
}4、将文件按照一定的大小分块请求
import { saveAs } from 'file-saver/FileSaver' //安装依赖包,用于保存文件
function partDownload(url, start, end, contentLength, partLength = 1000) {
let xhr = new XMLHttpRequest()
xhr.open('GET', url)
xhr.responseType = 'arraybuffer'
// arraybuffer blob,指定arraybuffer类型便于进行数据处理,具体看使用情况
xhr.setRequestHeader('Range', `bytes=${start}-${end}`)
xhr.onload = function () {
if (xhr.status === 200) {
//将arraybuffer转成blob
saveAs(new Blob([xhr.response]), '文件名.xlsx')
}
if (xhr.status === 206) {
let endLength = end + partLength
if (endLength > contentLength) {
endLength = contentLength
}
partDownload(url, end + 1, endLength, contentLength)
}
if (xhr.status === 416) {
console.log('416', xhr.response)
}
}
xhr.onerror = function () {}
xhr.send({})
}5、完整代码
getContentLength(url).then(length => {
partDownload(url, 0, 100, length)
})

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











