






 本文深入解析了浏览器处理用户导航到网站时的内部机制,涉及Browser进程、UI线程、Network线程和渲染进程间的交互。从用户在地址栏输入URL开始,包括解析输入、发起网络请求、处理重定向、读取响应、查找渲染进程、提交导航等步骤。同时讨论了ServiceWorker的角色、导航预加载优化以及安全检查如CORB。最后,简述了浏览器如何根据响应头Content-type决定如何处理不同类型的资源。
本文深入解析了浏览器处理用户导航到网站时的内部机制,涉及Browser进程、UI线程、Network线程和渲染进程间的交互。从用户在地址栏输入URL开始,包括解析输入、发起网络请求、处理重定向、读取响应、查找渲染进程、提交导航等步骤。同时讨论了ServiceWorker的角色、导航预加载优化以及安全检查如CORB。最后,简述了浏览器如何根据响应头Content-type决定如何处理不同类型的资源。
原文:https://developers.google.com/web/updates/2018/09/inside-browser-part2,针对原文有部分的删改。
导航的时候发生了什么
本文将深入挖掘为了显示网站内容,每一个进程和线程之间是怎么通信的。
让我们从一个简单的网页浏览用例开始:你在浏览器中输入了一个URL地址,然后浏览器从互联网上获取数据并显示一个页面。本文将重点介绍用户访问网站以及浏览器准备渲染页面的部分,可以称为导航。
从Browser进程开始
正如在上一篇文章描述的,选项卡之外的内容都由Browser进程处理。Browser进程有UI线程(负责绘制浏览器的按钮、输入框)、network线程(处理网络栈以接收网络中的数据)、storage线程(控制的对文件的访问等)。当你在地址栏中输入URL时,你的输入由Browser进程的UI线程处理。
一个简单的导航
第一步:处理输入
当用户在地址栏中输入内容时,UI线程会判断是搜索的内容还是一个URL地址。
在Chrome浏览器中,地址栏同时也是一个搜索输入框,所以UI线程需要解析用户输入的内容,来判断是将内容发送到搜索引擎还是当作站点请求。
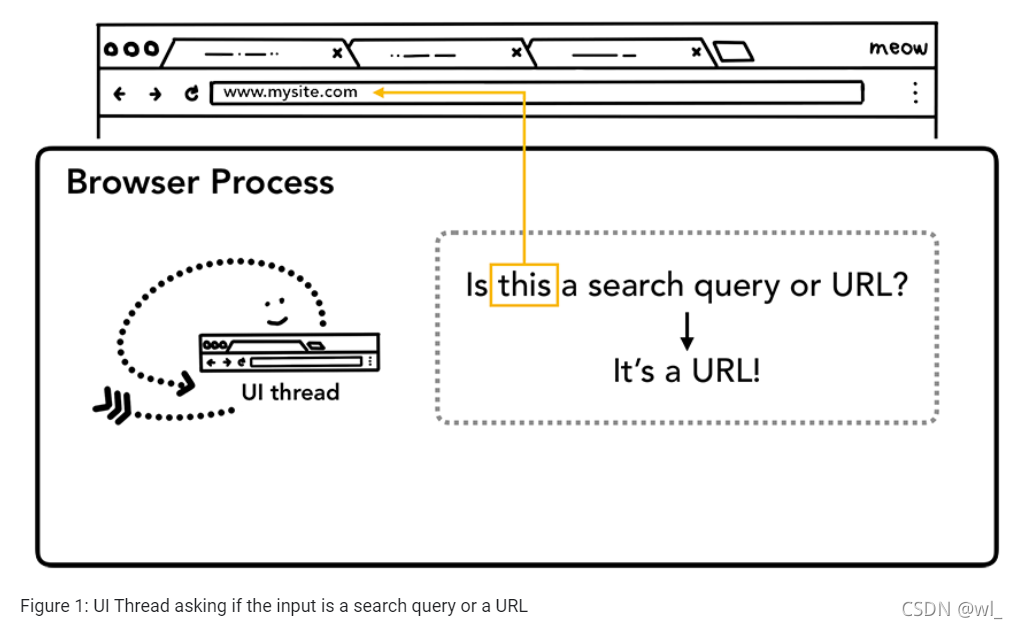
第二步:开始导航
当用户输入内容,按下Enter键时,UI线程发起网络调用以获取网站内容。加载spinner显示在选项卡的角落,同时network线程进行域名解析(DNS)和为请求建立连接(TLS)。
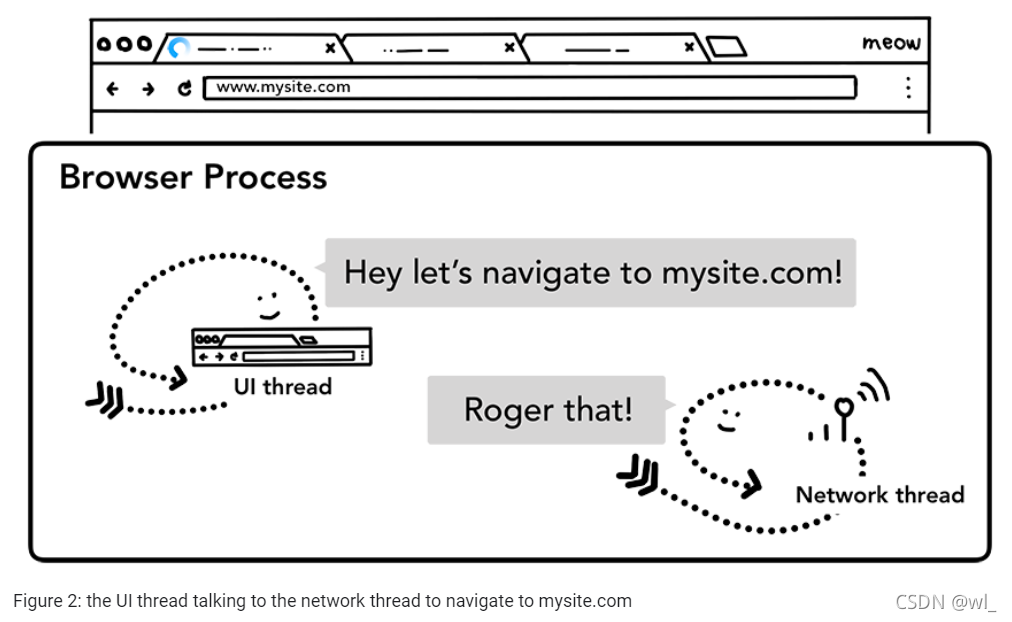
在这里,network线程可能接收到服务端的重定向头部301。在这种情况下,network线程会与UI线程进行通信,让UI线程发起另一个URL请求。
第三步:读取响应
一旦接收响应主体,如有必要,network线程会查看前几个字节流。响应头Content-type表明了返回的是什么数据类型,但是它可能丢失或错误。可以通过查阅MIME的相关标准资料进行查错。正如chromium源码注释中描述的那样,这是一项复杂的工作。你可以通过阅读源码中的注释去了解各个浏览器如何解析不同的Content-type和响应类型的数据的。
源码地址:
https://source.chromium.org/chromium/chromium/src/+/master:net/base/mime_sniffer.cc;l=5
// Detecting mime types is a tricky business because we need to balance
// compatibility concerns with security issues. Here is a survey of how other
// browsers behave and then a description of how we intend to behave.
//
// HTML payload, no Content-Type header:
// * IE 7: Render as HTML
// * Firefox 2: Render as HTML
// * Safari 3: Render as HTML
// * Opera 9: Render as HTML
//
// Here the choice seems clear:
// => Chrome: Render as HTML
//
// HTML payload, Content-Type: "text/plain":
// * IE 7: Render as HTML
// * Firefox 2: Render as text
// * Safari 3: Render as text (Note: Safari will Render as HTML if the URL
// has an HTML extension)
// * Opera 9: Render as text
//
// Here we choose to follow the majority (and break some compatibility with IE).
// Many folks dislike IE's behavior here.
// => Chrome: Render as text
// We generalize this as follows. If the Content-Type header is text/plain
// we won't detect dangerous mime types (those that can execute script).
//
// HTML payload, Content-Type: "application/octet-stream":
// * IE 7: Render as HTML
// * Firefox 2: Download as application/octet-stream
// * Safari 3: Render as HTML
// * Opera 9: Render as HTML
//
// We follow Firefox.
// => Chrome: Download as application/octet-stream
// One factor in this decision is that IIS 4 and 5 will send
// application/octet-stream for .xhtml files (because they don't recognize
// the extension). We did some experiments and it looks like this doesn't occur
// very often on the web. We choose the more secure option.
//
// GIF payload, no Content-Type header:
// * IE 7: Render as GIF
// * Firefox 2: Render as GIF
// * Safari 3: Download as Unknown (Note: Safari will Render as GIF if the
// URL has an GIF extension)
// * Opera 9: Render as GIF
//
// The choice is clear.
// => Chrome: Render as GIF
// Once we decide to render HTML without a Content-Type header, there isn't much
// reason not to render GIFs.
//
// GIF payload, Content-Type: "text/plain":
// * IE 7: Render as GIF
// * Firefox 2: Download as application/octet-stream (Note: Firefox will
// Download as GIF if the URL has an GIF extension)
// * Safari 3: Download as Unknown (Note: Safari will Render as GIF if the
// URL has an GIF extension)
// * Opera 9: Render as GIF
//
// Displaying as text/plain makes little sense as the content will look like
// gibberish. Here, we could change our minds and download.
// => Chrome: Render as GIF
//
// GIF payload, Content-Type: "application/octet-stream":
// * IE 7: Render as GIF
// * Firefox 2: Download as application/octet-stream (Note: Firefox will
// Download as GIF if the URL has an GIF extension)
// * Safari 3: Download as Unknown (Note: Safari will Render as GIF if the
// URL has an GIF extension)
// * Opera 9: Render as GIF
//
// We used to render as GIF here, but the problem is that some sites want to
// trigger downloads by sending application/octet-stream (even though they
// should be sending Content-Disposition: attachment). Although it is safe
// to render as GIF from a security perspective, we actually get better
// compatibility if we don't sniff from application/octet stream at all.
// => Chrome: Download as application/octet-stream
//
// Note that our definition of HTML payload is much stricter than IE's
// definition and roughly the same as Firefox's definition.

如果响应内容是一个HTML文件,下一步会将数据传给渲染进程(renderer process),但是如果它是一个zip文件或者其他文件,那将意味着这是一个下载请求,这时会将数据传给下载管理器(download manager)。
这也是安全检查发生的地方,如果域名和响应数据看起来似乎与已知的恶意网站匹配,那么network线程会显示一个告警页面。此外, Cross Origin Read Blocking (CORB)检测,防止敏感的跨站数据不会进入渲染器。
CORB的介绍可以参考:
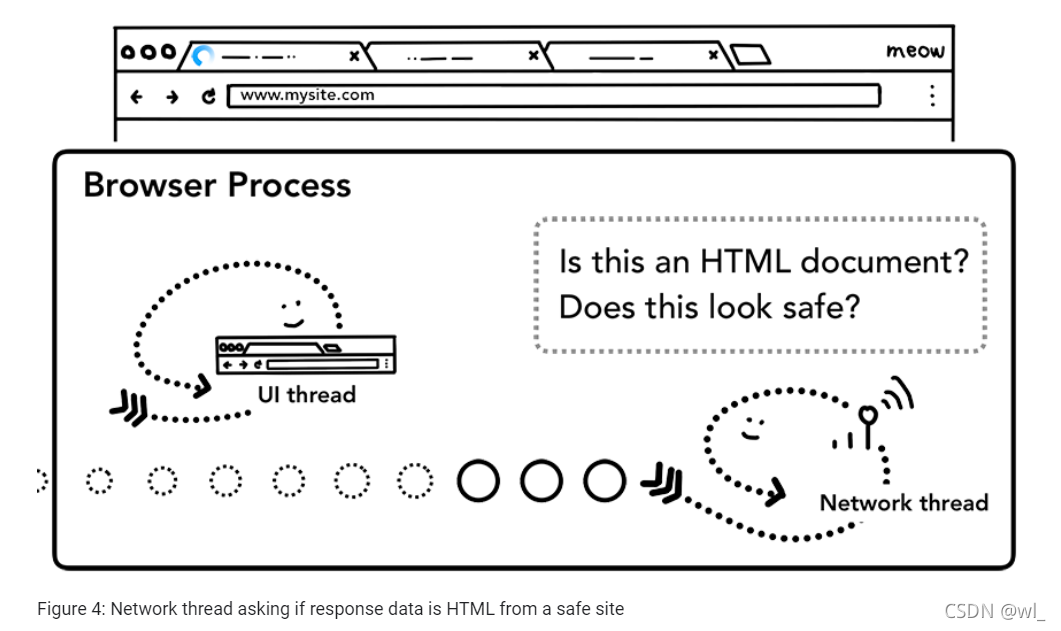
第四步:查找渲染进程
一旦所以检查做完,network线程就确信浏览器应该导航到请求的站点,network线程就会通知UI线程数据已经准备就绪。然后,UI线程找到一个渲染进程来进行页面渲染。
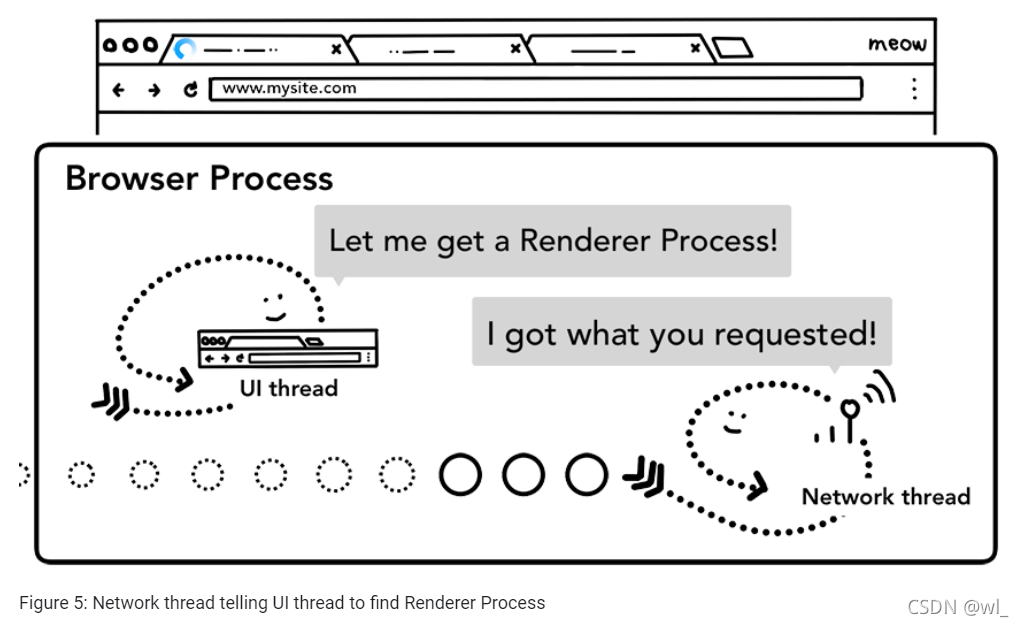
因为网络请求可能需要数百毫秒才能获得响应,因此一个用于加速此过程的优化得以应用。当UI线程发送URL请求给network线程时(第二步中),它已经知道会导航到什么站点。UI线程会尝试与网络请求并行地进行查找或启动renderer进程。这样,如果一切按预期进行,当network线程接收到数据时,renderer进程已经处于备用状态。如果收到重定向跨站点的响应,此备用进程可能不会用到,在这种情况下,可能需要不同的进程。
第五步:提交导航(Commit navigation)
现在,数据和渲染进程(renderer process)都已就绪,提交导航的IPC信号也从browser进程发往renderer进程。它还传递数据流,让渲染进程(renderer process)可以继续接收HTML数据。一旦browser进程监听到renderer进程提交的确认信息,那么导航就完成了,文档加载阶段就开始了。
此时,地址栏被更新,安全指示和站点设置UI反映新页面的站点信息。选项卡的会话历史将更新,那么后退/前进按钮将可以逐步浏览访问过的站点。当你执行关闭选项卡或窗口时,为了便于恢复选项卡/会话,会话历史会被存储在磁盘上。
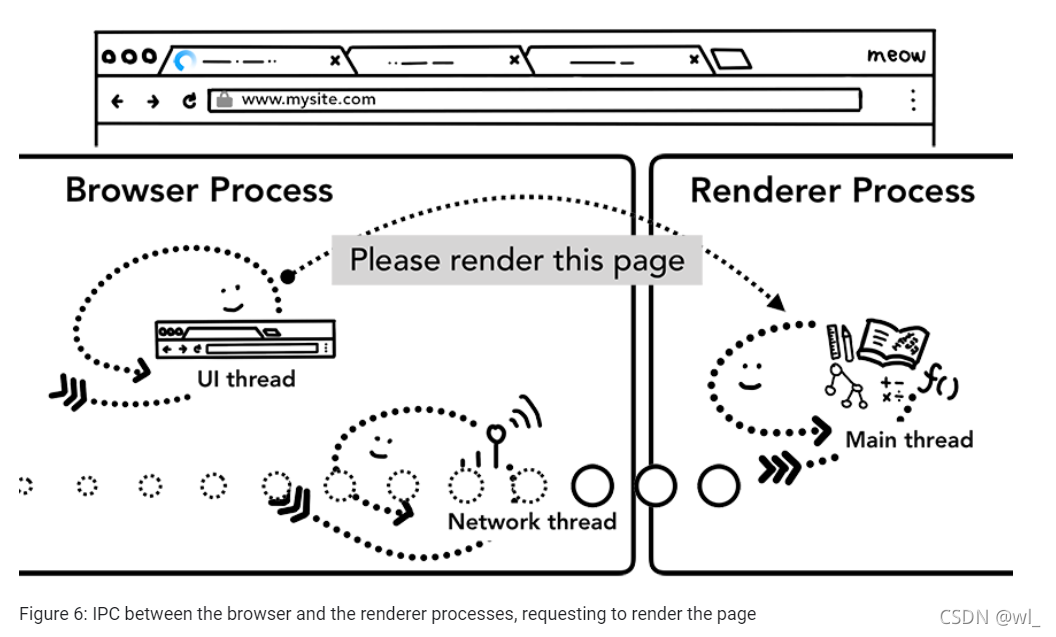
额外步骤:初始化加载完成
一旦导航被提交,渲染进程就进行加载资源和渲染页面。我们将在下一章详细描述在这一阶段发生的事情。一旦渲染进程”完成(finishes)“渲染,它会发送一个IPC信号给browser进程(这是发生在当页面中所有框【frames】的onload事件都触发并执行完成之后)。这时,UI线程停止在选项卡上显示loading spinner。这里用"finishes"而不是"finished",是因为在这之后,客户端的js可能仍然在加载额外的资源和渲染新的视图。
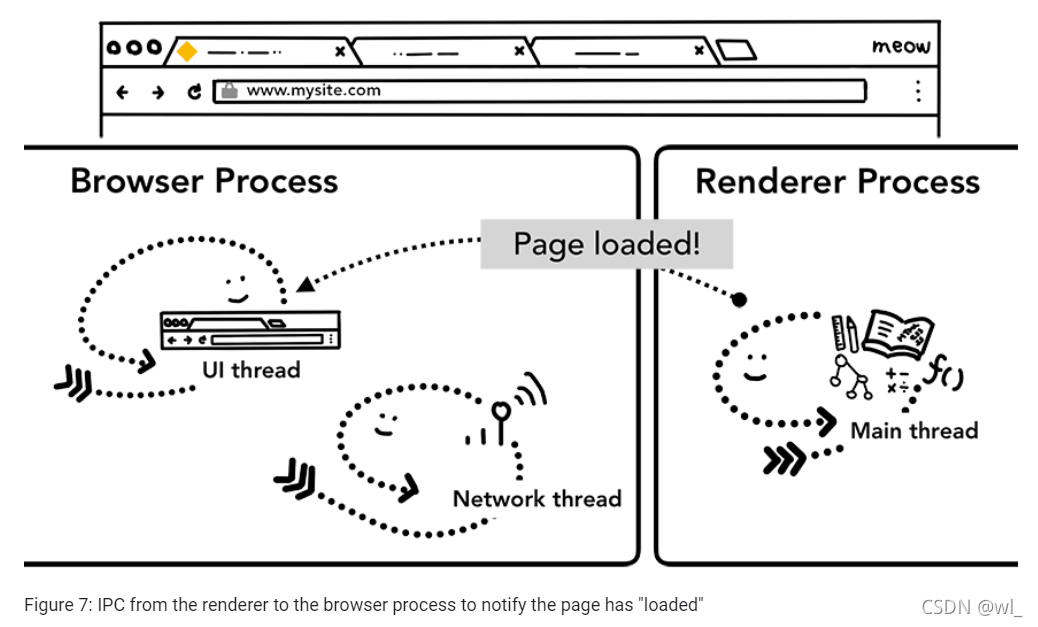
导航到其他站点
如上,一个简单的导航就这样完成了!但是当用户再次输入一个不同的URL地址会发生什么呢?其实,browser进程会经过相同的步骤导航到不同的站点。但在此之前,它需要去检测当前站点是否关心beforeunload事件。
当你尝试离开或者关闭选项卡时,beforeunload会创建“离开此站点?”的警告。选项卡内的所有内容(包括您的 JavaScript 代码)都由渲染器进程处理,因此当新的导航请求传入时,browser进程必须检查当前的渲染器进程。
注意:不要添加无条件的beforeunload事件处理程序,它会产生更多的延迟,因为在导航开始之前这些程序需要被执行。这个事件处理程序仅当需要时才添加,比如:警告用户离开页面可能会丢失页面中输入的数据。
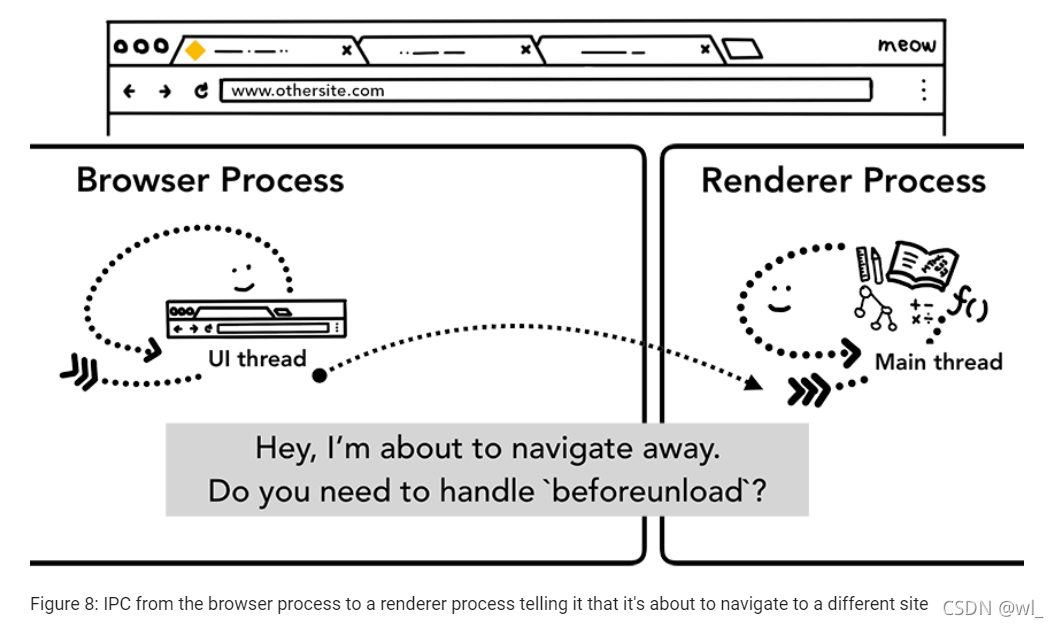
如果导航是从renderer进程启动的(比如点击链接、执行window.location = "https://newsite.com"),
renderer进程首先检查beforeunload处理程序。然后它经历与browser进程启动导航相同的过程,唯一的区别是导航请求是从renderer进程启动到browser进程。
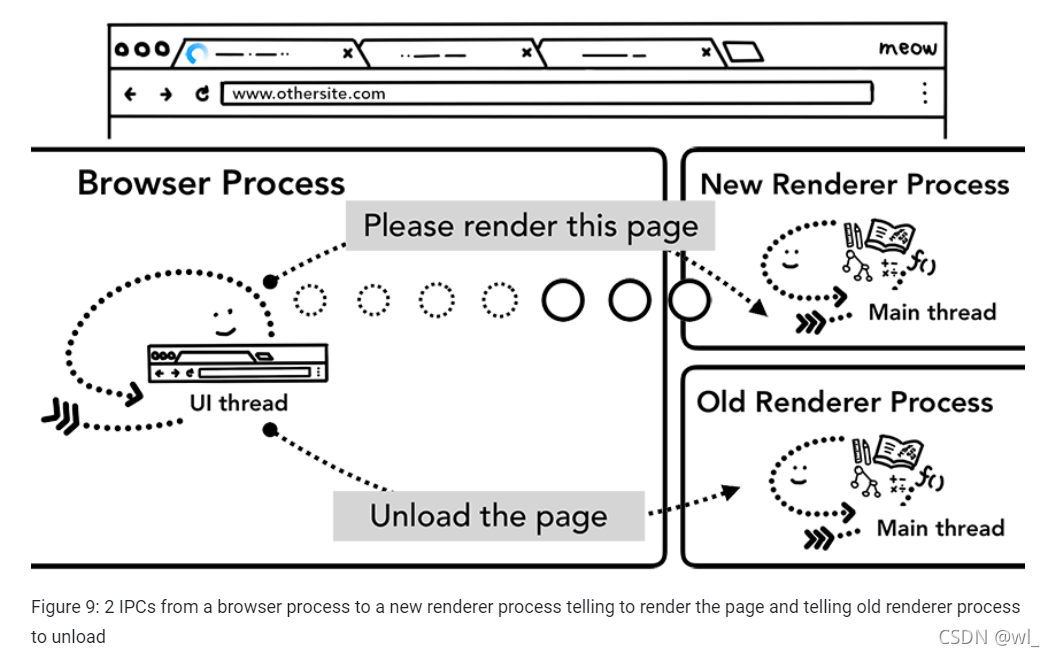
当导航到与当前不同的站点时,一个单独的renderer进程会被调用来处理新的导航,而当前的renderer进程则用来处理诸如unload这样的事件。更多信息可以查看an overview of page lifecycle states ,同时可以使用 the Page Lifecycle API来参与到页面的生命周期中。
关于Service Worker
Service Worker 是浏览器在后台独立于网页运行的脚本,它打开了通向不需要网页或用户交互的功能的大门。
最近对该导航过程的一项更改是引入了 Service Worker。 Service Worker 是一种在应用程序代码中编写网络代理的方法; 允许Web开发人员更好地控制数据的缓存和网络中新数据的获取。 如果 Service Worker 设置为从缓存加载页面,则无需从网络请求数据。
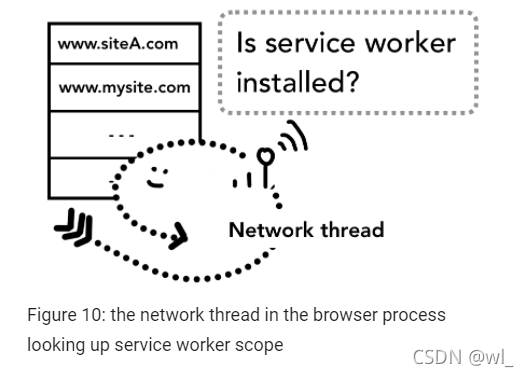
要记住的重要部分是 Service Worker 是在渲染器进程(renderer进程)中运行的 JavaScript 代码。 但是当导航请求进来时,browser进程如何知道该站点有Service Worker?
当service worker 被注册时,service worker作用域会保留它的引用
(可以阅读https://developers.google.com/web/fundamentals/primers/service-workers/lifecycle
这篇文章了解更多信息),当导航发生时,network线程通过域名在注册过service worker的作用域中查找,如果找到与URL匹配的service worker,UI线程则找一个renderer进程来执行它。Service Worker 可能会从缓存中加载数据,从而无需从网络请求数据,要么它可能会从网络请求的新资源。
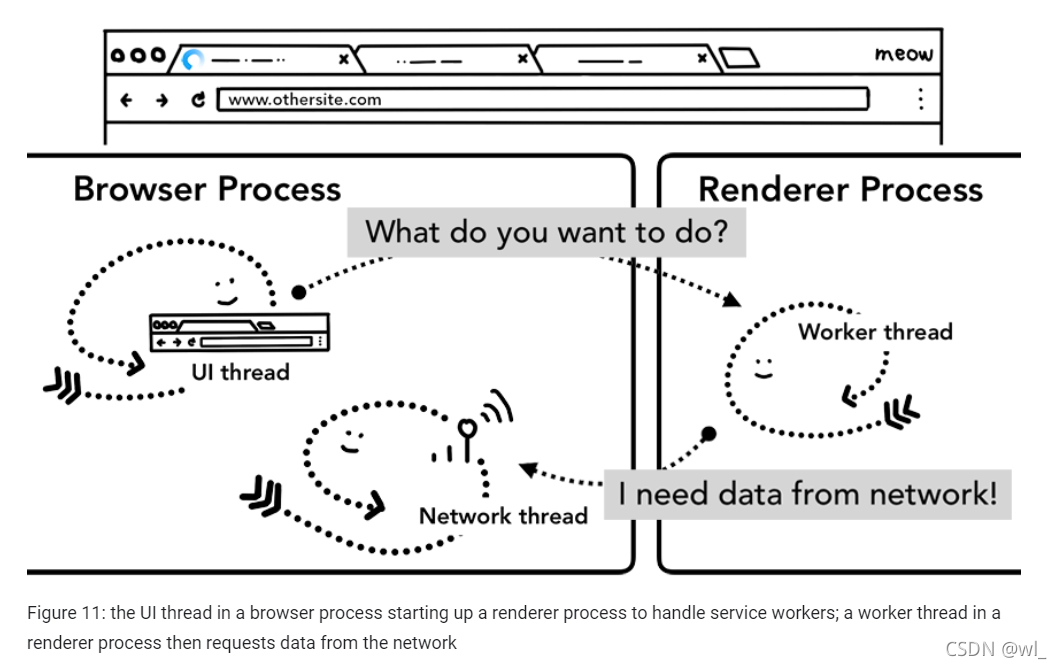
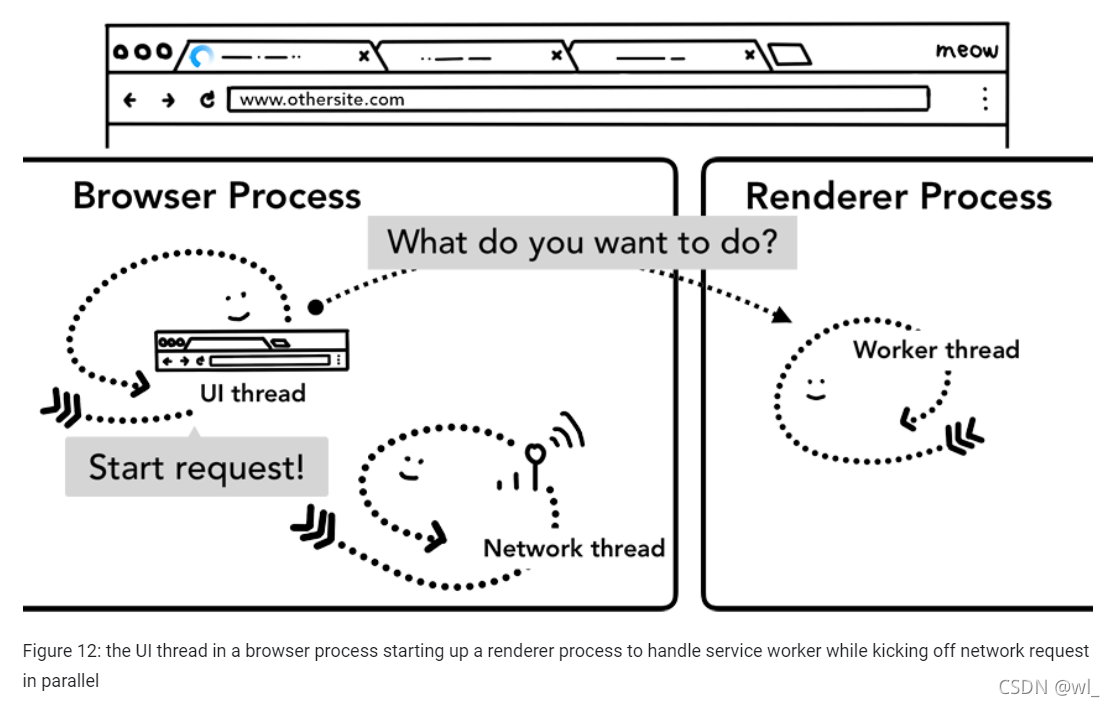
导航预加载
你可以看到,如果 Service Worker 最终决定从网络请求数据,浏览器进程和渲染器进程之间的这种往返可能会导致时延。而导航预加载是通过在启动Service Worker的时,并行要求network线程进行网络请求来加速这一过程的一种机制。它通过使用请求头部来标记这些请求,让服务器来决定这对这些请求返回什么内容;比如:仅返回更新的数据而不是整个文档。更多详情见:https://developers.google.com/web/updates/2017/02/navigation-preload
小结
在这篇文章中,我们看到了在导航的过程中,你的应用代码例如响应头和客户端代码怎么和浏览器进行交互的。同时了解了浏览器获取网络数据的步骤,让更容易理解为什么会有预加载相关的API。在下一篇文章中,我们将深入到浏览器如何使用HTML/CSS/JavaScript来渲染页面的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









