




 本文深入探讨了进程的概念,包括进程的基本语法、并发与并行的区别、进程间的数据隔离及通信方式,以及如何使用Python的multiprocessing模块创建和管理子进程。此外,还介绍了进程的三种状态:就绪、执行和阻塞,以及守护进程的作用和实现方法。
本文深入探讨了进程的概念,包括进程的基本语法、并发与并行的区别、进程间的数据隔离及通信方式,以及如何使用Python的multiprocessing模块创建和管理子进程。此外,还介绍了进程的三种状态:就绪、执行和阻塞,以及守护进程的作用和实现方法。
文章目录
进程
进程就是正在运行的程序,它是操作系统中,资源分配的最小单位.
资源分配 : 分配的是cpu和内存等物理资源
进程号是进程的唯一标识
ps -aux 查看进程 ps -aux | grep pycharm 获取pycharm的进程号
同一个程序执行两次之后是两个进程
进程和进程之间的关系: 数据彼此隔离,通过socket通信
import os,time
from multiprocessing import Process
# 获取子进程[当前进程]的id号
res1 = os.getpid()
print(res1)
# 获取父进程的id号
res2 = os.getppid()
print(res2)
# linux Process 底层利用的是fork来创建进程的,而fork在windows里并不支持.
-
并行和并发
并发:一个cpu同一时间不停执行多个程序
并行:多个cpu同一时间不停执行多个程序 -
cpu的进程调度方法
先来先服务fcfs(first come first server):先来的先执行
短作业优先算法:分配的cpu多,先把短的算完
时间片轮转算法:每一个任务就执行一个时间片的时间.然后就执行其他的.
多级反馈队列算法越是时间长的,cpu分配的资源越短,优先级靠后
越是时间短的,cpu分配的资源越多 -
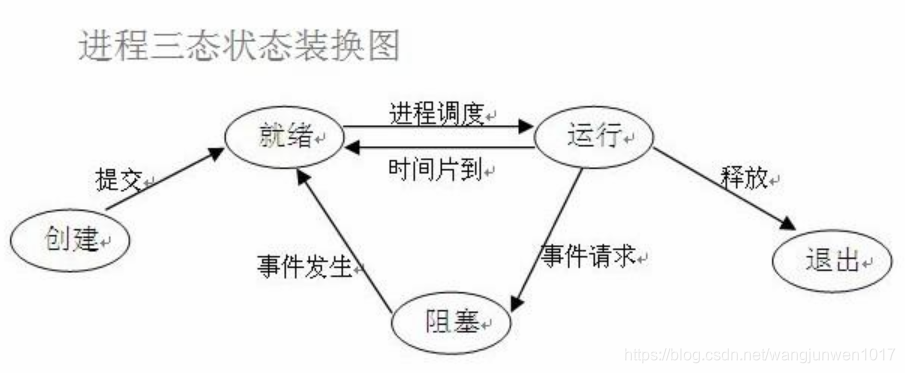
进程三状态图
- 就绪(Ready)状态
只剩下CPU需要执行外,其他所有资源都已分配完毕 称为就绪状态。 - 执行(Running)状态
cpu开始执行该进程时称为执行状态。 - 阻塞(Blocked)状态
由于等待某个事件发生而无法执行时,便是阻塞状态,cpu执行其他进程.例如,等待I/O完成input、申请缓冲区不能满足等等。
- 就绪(Ready)状态
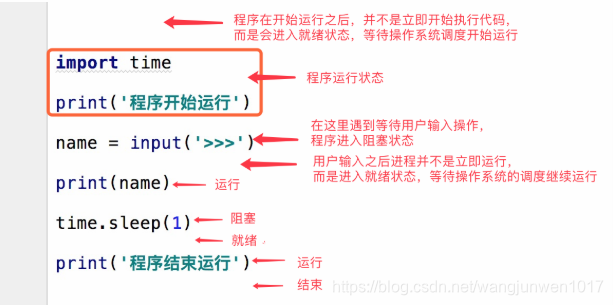
进程的基本语法
def func():
print("1.子进程id>>>%s,父进程id>>>%s" % (os.getpid(),os.getppid()))
if __name__ == "__main__":
print("2.子进程id>>>%s,父进程id>>>%s"% (os.getpid(),os.getppid()))
# 创建子进程,返回一个进程对象. target是指定要完成的任务,后面接的是函数
p = Process(target=func)
# 调用子进程.
p.start()
函数中带有参数.
进程的并发要依靠cpu
cpu先执行谁后执行谁,要依靠cpu调度策略
- 无参函数
def func():
for i in range(1,6):
print("2.子进程id>>>%s,父进程id>>>%s" % (os.getpid(),os.getppid()))
if __name__ == "__main__":
print("1.子进程id>>>%s,父进程id>>>%s"% (os.getpid(),os.getppid()))
# 创建子进程
p =Process(target= func)
# 调用子进程
p.start()
n = 5
for i in range(1,n+1):
print("*" * i)
- 有参函数
def func(n):
for i in range(1,n+1):
time.sleep(0.5)
print("2.子进程id>>>%s,父进程id>>>%s" % (os.getpid(),os.getppid()))
if __name__ == "__main__":
print("1.子进程id>>>%s,父进程id>>>%s"% (os.getpid(),os.getppid()))
n = 5
'''
# 创建子进程 返回进程对象 如果有参数用args关键字参数指定,
# 对应的值是元组,参数塞到元组中,按照次序排列
'''
p = Process(target=func,args=(n,))
p.start()
for i in range(1,n+1):
time.sleep(0.3)
print("*" * i)
进程之间的数据彼此是隔离的
count = 99
def func():
global count
count += 1
print("我是子进程,count=",count)
if __name__ == "__main__":
p = Process(target=func)
p.start()
time.sleep(1)
print("我是主进程,count=",count)
'''
我是子进程,count= 100
我是主进程,count= 99
'''
多个进程的并发
# 在程序并发时,因为cpu的调度策略问题,不一定谁先执行,谁后执行.
def func(args):
print("args=%s,子进程id号>>>%s,父进程id号>>>%s" % (args,os.getpid(),os.getppid()))
if __name__ == "__main__":
for i in range(10):
Process(target=func,args=(i,)).start()
子进程和父进程之间的关系
通常情况下,父进程会比子进程速度稍快,但是不绝对.
在父进程执行所有代码完毕之后,会默认等待所有子进程执行完毕
然后在彻底的终止程序.为了方便进程的管理.
如果不等待,子进程会变成僵尸程序,在后台不停地占用内存和cpu资源
但是本身由于进程太多,并不容易发现.
def func(args):
print("args=%s,子进程id号>>>%s,父进程id号>>>%s" % (args,os.getpid(),os.getppid()))
time.sleep(1)
print("args=%s,end" % (args))
if __name__ == "__main__":
for i in range(10):
Process(target=func,args=(i,)).start()
"""
Process(target=func,args=(i,)).start()
Process(target=func,args=(i,)).start()
Process(target=func,args=(i,)).start()
Process(target=func,args=(i,)).start()
Process(target=func,args=(i,)).start()
Process(target=func,args=(i,)).start()
....
"""
print("*******父进程*******")
join
等待所有子进程执行完毕之后,主进程在向下执行.
join基本用法
from multiprocessing import Process
import time,os
def func():
print("发送第一封邮件..")
if __name__ == "__main__":
p = Process(target=func)
p.start()
# time.sleep(1)
# 等待p对象的这个子进程执行完毕之后,在向下执行代码
# join实际上是加了阻塞.
p.join()
print("发送第十封邮件")
多个子进程通过join 加阻塞,进行同步的控制
def func(index):
time.sleep(0.3)
print("第%s封邮件已经发送..." % (index))
if __name__ == "__main__":
lst = []
for i in range(10):
p = Process(target=func,args=(i,))
p.start()
lst.append(p)
# 把列表里面的每一个进程对象都去执行join()
# 必须等我子进程执行完毕之后了,在向下执行,控制父子进程的同步性.
for i in lst:
i.join()
# 等前9个邮件发送之后了,在发第十个
print("发送第十封邮件")
使用第二种方法创建进程
基本语法
可以使用自定义类的方式创建子进程,
但是必须继承父类Process
而且所有的逻辑都必须写在run方法里面.
class MyProcess(Process):
# 必须使用叫做run的方法
def run(self):
# 写自定义的逻辑
print("子进程id>>>%s,父进程的id>>>%s" % (os.getpid(),os.getppid()))
if __name__ == "__main__":
p = MyProcess()
p.start()
print("主进程:{}".format(os.getpid()))
带参数的子进程函数
class MyProcess(Process):
def __init__(self,arg):
# 必须调用一下父类的初始化构造方法.
super().__init__()
self.arg = arg
# 必须使用叫做run的方法
def run(self):
# 在这里就得获取到参数
print("子进程id>>>%s,父进程的id>>>%s" % (os.getpid(),os.getppid()))
print(self.arg)
if __name__ == "__main__":
lst = []
for i in range(10):
p = MyProcess("参数:%s" % (i) )
p.start()
lst.append(p)
for i in lst:
i.join()
print("最后执行主进程的这句话...",os.getpid())
守护进程
正常情况下,主进程默认等待子进程调用结束之后在结束
守护进程在主进程所有代码执行完毕之后,自动终止.
kill -9 进程号杀死进程.
守护进程的语法:
进程对象.daemon = True
设置该进程为守护进程.
必须要写在**start()**方法之前赋值
为主进程守护,主进程如果代码执行结束了,该守护进程自动结束
基本语法
from multiprocessing import Process
import time
def func():
print("子进程start")
time.sleep(1)
print("子进程end")
if __name__ == "__main__":
p = Process(target=func)
p.daemon = True
p.start()
print("主进程执行结束")
多个子进程的情况
当多个子进程并发执行时,默认主进程等待子进程
如果标记该子进程是守护进程.
当主进程执行完毕所有代码之后,守护进程立刻终止
主进程的代码执行到最后一行,就意味着函数代码执行完毕,就应该杀掉守护进程
其他非守护进行继续正常执行,主进程仍然等待直到结束
最后主进程在真正的释放结束.
def func1():
count = 1
while True:
print("*" * count)
time.sleep(0.5)
count += 1
def func2():
print("func2 start")
time.sleep(3)
print("func2 end")
if __name__ == "__main__":
p1 = Process(target=func1)
p1.daemon = True
p1.start()
p2 = Process(target=func2)
p2.start()
print("主进程代码执行结束...")
守护进程的实际作用: 监控报活
def alive():
# 服务器向另外一个服务器发送消息.
# 给最大的统筹服务器发送报活消息
# 如果总的服务器没有收到报活消息,就判定1号主机异常.
while True:
print("1号服务主机... i am ok")
time.sleep(0.8)
def func():
print("用来统计当前主机的服务器日志,打包变成文件")
time.sleep(3)
if __name__ == "__main__":
p1 = Process(target=alive)
p1.daemon = True
p1.start()
p2 = Process(target=func)
p2.start()
# 模拟好比这个程序结束了,那么服务器挂掉,
p2.join()
print(" ... ... ...")

















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









