




一、什么是进程地址空间
1. 引入进程地址空间
先来运行如下代码:
#include <unistd.h> #include <sys/types.h> int main() { int a = 100; pid_t id = fork(); if(id == 0) { //子进程 int cnt = 5; while(1) { printf("i am child, pid : %d, ppid : %d, a : %d, &a : %p\n", getpid(), getppid(), a, &a); sleep(1); if(cnt) { cnt--; } else { a = 200; printf("子进程change a : 100->200\n"); cnt--; } } } else { //父进程 while(1) { printf("i am parent, pid : %d, ppid : %d, a : %d, &a : %p\n", getpid(), getppid(), a, &a); sleep(1); } } return 0; }
问题:为什么父子进程,同一个地址,但变量内容不一样?
- 地址值是一样的,说明,该地址绝对不是物理地址!
- 这种地址叫做虚拟地址或线性地址
- 我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理
引入进程地址空间:每一个进程都有自己的进程地址空间(是OS帮我们创建的),我们用户看到的都是这个进程地址空间里的地址,虚拟地址!
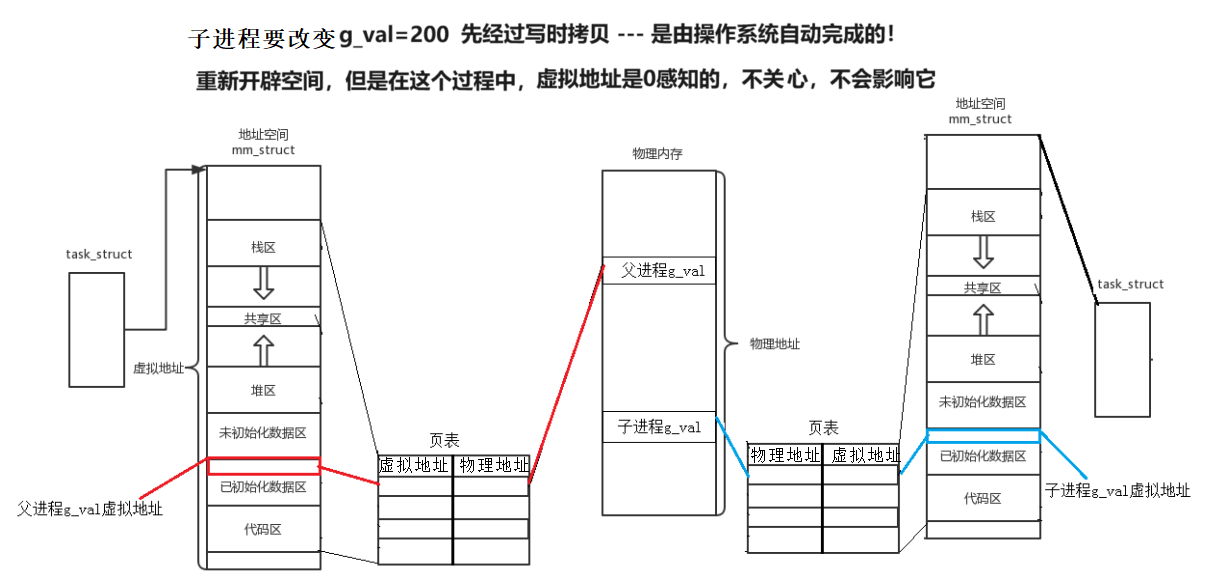
如上图,可知:
- 因为子进程是以父进程为模版创建的,所以进程地址空间一样,所以我们看到父子进程同一个变量的虚拟地址一样
- 父子进程代码共享,数据不共享,所以当子进程改变数据时,会发生写时拷贝——重新开辟空间
- OS通过页表,将虚拟地址映射到物理地址,所以数据改变,发生写时拷贝重新开辟空间时,左侧的虚拟地址是0感知的,不关心,不会影响它
- 总结:因为进程地址空间和页表,所以我们可以看到父子进程同一个地址打印不同内容

2. 进程地址空间
问题:什么是进程地址空间?
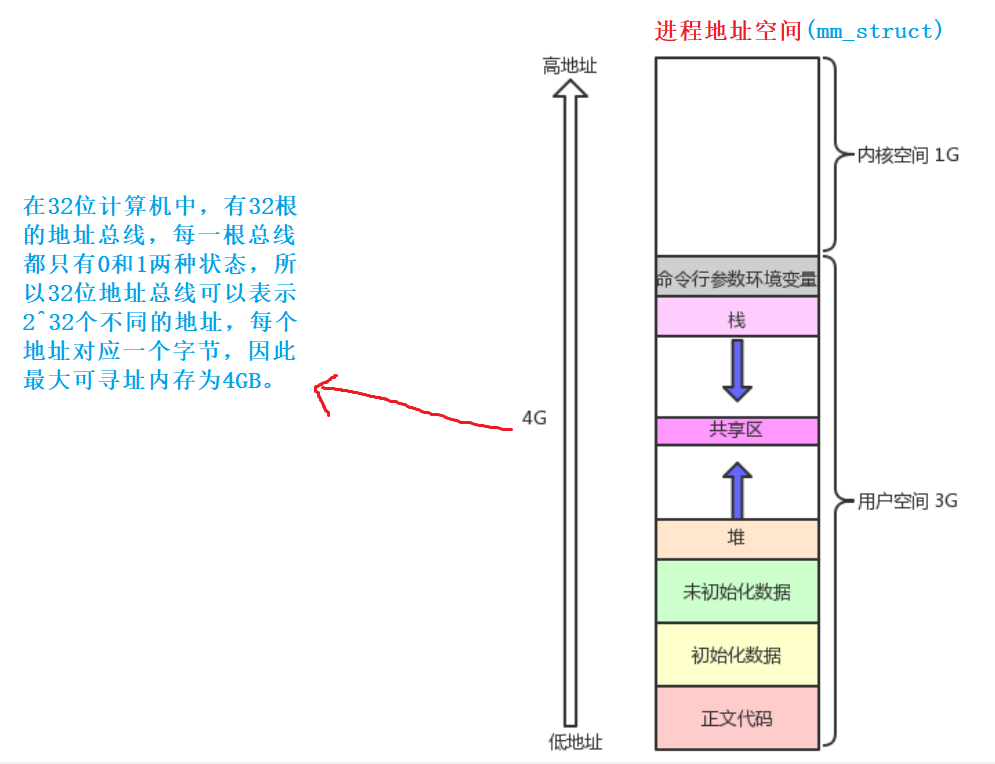
- 进程地址空间本质是一个描述进程可视虚拟地址范围大小,即进程所看到的地址是虚拟的,不是直接看到物理地址
- 每一个进程都要有自己对应的进程地址空间,地址空间也要被操作系统管理:先描述,再组织。
- 地址空间就是内核为进程创建的一个数据结构对象(mm_struct)
- 进程地址空间一定要存在各种区域划分,这是为了更好地管理内存、提高安全性和支持程序的模块化执行。
问题:为什么地址空间可视范围为4GB?
- 地址空间就是地址总线排列组合形成的地址范围[0, 2^32]
- 在32位计算机中,有32根的地址总线,每一根总线都只有0和1两种状态,32根,有2^32种。
问题:地址空间怎么区域划分?
- 对线性地址进行start和end,即可区域划分
struct mm_struct //默认划分的区域是4GB { //代码区 long code_start, code_end; //初始化全局变量 long init_start, init_end; //未初始化全局变量 long uninit_start, uninit_end; //堆区 long heap_start, heap_end; //栈区 long stack_start, stack_end; …… }
- 我们不仅仅要知道地址空间被划分的每一个区域范围,还要知道在区域范围内,连续的空间中,每一个最小单元都可以有地址,这个地址可以被该区域直接使用!
- 举一个例子帮助我们理解区域划分:我们有一张100cm的桌子,一开始小胖和小花共同使用,但是由于小胖非常调皮,一个人就占用了80cm的桌子,小花给小胖说了,小胖就是不改,终于小花忍无可忍,就在桌子的中间划了一条三八线,小胖超过三八线就会被小花打。这一条三八线本质就是区域划分,“三八线”在计算机中通过定义一个开始和结束来描述。
- 所谓的空间区域变大或变小,用计算机描述就是改start和end。
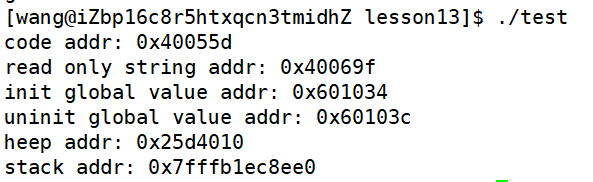
验证:进程地址空间的区域划分#include<stdio.h> #include<stdlib.h> int g_val_1; int g_val_2 = 100; int main() { //正文代码:代码区 printf("code addr: %p\n", main); //字符常量区 const char *str = "hello"; printf("read only string addr: %p\n", str); //已初始化全局变量 printf("init global value addr: %p\n", &g_val_2); //未初始化全局变量 printf("uninit global value addr: %p\n", &g_val_1); //堆区 char *mem = (char*)malloc(100); printf("heep addr: %p\n", mem); //栈区 printf("stack addr: %p\n", &str); return 0; }
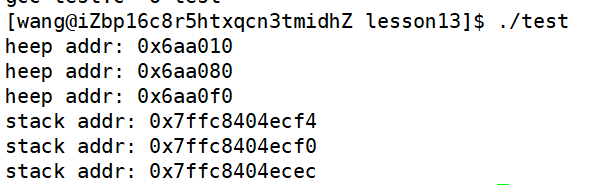
验证:堆栈相对增长int main() { //堆栈:相对增长 //堆区:向高地址增长 char *mem1 = (char*)malloc(100); char *mem2 = (char*)malloc(100); char *mem3 = (char*)malloc(100); printf("heep addr: %p\n", mem1); printf("heep addr: %p\n", mem2); printf("heep addr: %p\n", mem3); //栈区:向低地址增长——>因为他要入栈,先定义的变量先入栈 int a; int b; int c; printf("stack addr: %p\n", &a); printf("stack addr: %p\n", &b); printf("stack addr: %p\n", &c); return 0; }
为什么static修饰的局部变量,生命周期与程序一样?——》static修饰的局部变量,编译的时候已经被编译到全局数据区了!int g_val_1; int g_val_2 = 100; int main() { //字符常量区 const char *str = "hello"; printf("read only string addr: %p\n", str); //已初始化全局变量 printf("init global value addr: %p\n", &g_val_2); //未初始化全局变量 printf("uninit global value addr: %p\n", &g_val_1); //为什么static修饰的局部变量,生命周期与程序一样 //编译的时候,已经被编译到(已初始化)全局数据区 static int a = 0; printf("static a stack addr: %p\n", &a); static int b; printf("static b stack addr: %p\n", &b); return 0; }
二、为什么要有进程地址空间
- 让进程以统一的视角看待内存(每个进程拥有独立的虚拟地址空间,进程无需关心物理内存的实际布局,只需通过虚拟地址访问内存。)
- 增加进程虚拟地址空间可以让我们访问内存的时候,增加一个转换的过程,在这个转换的过程中,可以对我们寻址请求进行审查,所以一旦异常访问,直接拦截该请求,不会到达物理内存,保护物理内存
- 因为有地址空间和页表的存在,将进程管理模块和内存管理模块进行解耦合!
- 传统耦合问题:若进程直接操作物理内存,进程创建/销毁、调度等操作需频繁与内存管理交互,导致代码复杂且难以维护。
- 解耦设计:
- 进程管理:只需分配和切换虚拟地址空间(如通过页表基址寄存器CR3),无需关心物理内存细节。
- 内存管理:负责物理内存分配、页表维护、换页策略等,与进程生命周期解绑。
三、重新理解什么是进程
1. 什么是进程
在之前的学习中我们说,进程 = 内核数据结构(task_struct)+ 程序的代码和数据
现在我们知道进程的内核数据结构不光只有task_struct,进程 = 内核数据结构(task_struct && mm_struct && 页表)+ 程序的代码和数据
- task_struct:
- 定义:task_struct 是 Linux 内核中用来描述一个进程(或线程)的核心数据结构,也称为进程控制块(PCB, Process Control Block)。
- 作用:它包含了进程的所有状态信息,比如:进程 ID(PID)、进程状态(运行、就绪、阻塞等)、父进程和子进程关系 、进程的优先级、CPU 寄存器的上下文(用于进程切换时的保存与恢复)、打开的文件描述符、信号处理信息等等。
- 简单来说,task_struct 是操作系统“认识”一个进程的关键,它让内核知道这个进程是谁、它在做什么、它需要什么资源。
- mm_struct:
- 定义:进程地址空间——描述进程可视虚拟地址范围大小
- mm_struct 是进程“看到”的虚拟内存空间的抽象,它与物理内存之间通过页表进行映射。
- 页表:
- 定义:页表是操作系统用于实现虚拟内存管理的关键机制,它将进程的虚拟地址映射到物理地址。
- 作用:实现虚拟内存与物理内存的分离;支持内存保护(不同进程不能访问彼此的内存);支持内存的延迟加载(按需分页);支持内存共享(比如多个进程共享同一个动态库);页表是连接进程的虚拟地址空间与物理内存的桥梁,是实现现代操作系统内存管理的基础。
2. 页表
进程看到的虚拟地址,那OS必须负责将 虚拟地址 转化成 物理地址 。
页表是连接进程的虚拟地址空间与物理内存的桥梁,将进程的虚拟地址映射到物理地址。
每一个进程都有属于自己的页表数据结构。
问题:进程如何找到自己的页表?
- 在CPU调度该进程的时候,会读取进程的上下文
- 页表结构的地址属于进程的上下文,所以在进程调度的时候,页表地址会被CPU读取,这样通过页表地址进程就可以找到自己的页表了
- CPU中有一个cr3寄存器,会保存当前被调度进程的页表地址
问题:在进程地址空间中代码段、字符常量区是只读,为什么?
- 页表除了可以将虚拟地址映射到物理地址,还有一个权限标记位
- 在权限标记位,标记该地址的读写权限。
- 物理内存没有权限的概念
问题:进程是可以挂起的,你怎么知道你的进程的代码和数据,在不在内存?
- 首先我们先要有一个共识:现代OS,几乎不做任何浪费空间和时间的事情
- 所以我们加载程序到内存是一种惰性加载的方式,即程序的代码和数据不会在程序启动时全部加载到内存,而是在真正需要访问的时候才加载。
- 每个页表项中通常还包含一个存在位(Present/Valid Bit):
- Present = 1:表示该虚拟页当前映射到物理内存中,可以直接访问。
- Present = 0:表示该虚拟页当前不在物理内存中,可能已经被换出到磁盘。此时若访问该页,会触发缺页中断(Page Fault),操作系统会负责将该页从磁盘重新加载到内存。
- 因此,通过检查页表中的存在位,操作系统可以准确知道某个虚拟页是否在内存中。
问题:进程在被创建的时候,是先创建内核数据结构还是先加载对应的可执行程序呢?
- 先创建内核中的进程控制块(PCB)等内核数据结构,然后再加载对应的可执行程序


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









