




 本文深入探讨Java容器类的框架,讲解Collection、Set、Queue、Map等类的特性和使用方法,对比不同实现的优劣,并介绍散列、快速失败机制及引用类型。
本文深入探讨Java容器类的框架,讲解Collection、Set、Queue、Map等类的特性和使用方法,对比不同实现的优劣,并介绍散列、快速失败机制及引用类型。
目录
前言:
本系列是我本人阅读java编程思想这本书的读书笔记,主要阅读第五章到第十七章以及第二十一章的内容,今天的笔记是第十七章
第十一章我们已经了解到了java容器类的基本概念和基本功能,这一章我们来更深入的探索一下这个重要的类库
1. 完整的容器分类法
先上一张java容器类的完整框架图
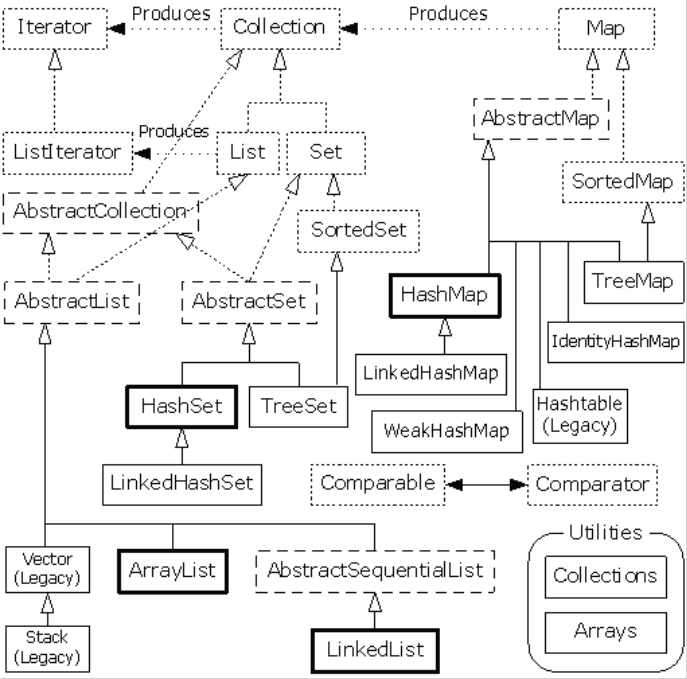
图中虚线部分都是抽象类,可以看出有不少的累都是抽象类,他们只是部分实现了特定接口的工具,但实际上容器类库包含了足够多的功能,完全可以忽略这些Abstart开头的类。
2. collection功能方法
| boolean add(T) | 确保容器持有具有泛型类型T的参数。如果没有将此参数添加进容器,则返回false |
| boolean addAll(Collection<? extends T>) | 添加参数中的所有元素。只要添加了任意元素就返回true |
| void clear() | 移除容器中的所有元素 |
| boolean contains(T) | 如果容器已经持有具有泛型类型T的参数,则返回true |
| boolean containsAll(Colleciton <?>) | 如果容器已经持有此参数中的所有元素,则返回true |
| boolean isEmpty() | 容器中没有元素是返回true |
| Iterator<T> iterator | 返回一个Iterator<T>,可以用来遍历容器中的元素 |
| boolean remove(Object) | 如果参数在容器中,则移除此元素的一个实例。如果做了移除动作,则返回true |
| boolean removeAll(Collection<?>) | 移除参数中的所有元素。只要有移除动作发生就返回true |
| boolean retainAll(Collection<?>) | 只保存参数中的元素(交集的概念)。只要Collection发生了改变就返回true |
| int size() | 返回容器中元素的数目 |
| Object[]toArray() | 返回一个数组,该数组包含容器中的所有元素 |
| <T>T[]toArray(T[]A) | 返回一个数组,该数组包含容器中所有的元素。返回结果的运行时类型与参数数组a的类型相同,而不是单纯的Object |
需要特别注意的是,这行公共方法中不包括随机访问元素的get()方法,因为Collection包括Set,而Set中的元素顺序是内部自己维护的,所以也有不存在随机访问元素一说。如果想要访问Collection中的元素,请使用Iterator迭代器。
3. Set和存储顺序
我们都知道,Set中是不允许重复元素而且是排序的,存储顺序如何维护,在Set的不同实现之间有所不同。
| Set | 存入Set的每个元素都必须是唯一的,因为Set不保存重复元素。加入Set的元素必须定义equals()方法以确保对象的一致性。Set与Collection有完全一样的接口。Set接口不保证维护元素的次序 |
| HashSet* | 为快速查找而设计的Set。存入HashSet的元素必须定义hashCode()方法 |
| TreeSet | 保持次序的Set,底层为树结构。使用它可以从Set中提取有序的序列。元素必须实现Comparable接口 |
| LinkedHashSet | 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序),于是在使用迭代器遍历Set时,结果会按元素插入的次序显示,元素也必须定义hashCode()方法 |
HashSet后面跟着的星号表示如果没有其他的限制,它就应该是默认的选择,因为它对速度进行了优化。
4. 队列
java中除了并发应用,Queue就只有LinkedHashMap和PriorityQueue两个实现,他们的差异在于排序行为而不是性能。优先级队列必须要实现Compatable接口来控制排序顺序。
5.Map
Map的基本思想是利用键-值对来关联对象,使得可以使用键来查找值。性能是Map中一个非常重要的问题,HashMap使用散列码来提高搜索效率。下面列举基本的Map实现
| HashMap* | Map基于散列表的实现(它取代了HashTable)。插入和查询键值对的开销是固定的。可以通过构造器设置容量和负载因子,以调整容器的性能 |
| LinkedHashMap | 类似HashMap,但是迭代遍历它时,取得键值对的顺序是插入顺序,或者是最近最少使用(LRU)的顺序。只比HashMap慢一点,但是在遍历的时候更快,因为它使用链表维护内部顺序 |
| TreeMap | 基于红黑树实现,查看键或者键值对时,他们会被排序(次序由Comparable或Comparator决定)。TreeMap的特点在于,得到的结果一定是排序过的。TreeMap是唯一的带有subMap的Map,它可以返回一个子树。 |
| WeakHashMap | 弱键映射,允许释放映射所指的对象;这是为解决某类特殊问题涉及的,如果映射之外没有引用指向某个键,则此键可以被垃圾回收器回收。 |
| ConcurrentHashMap | 一种线程安全的Map,它不涉及同步锁。 |
| IdentifyHashMap | 使用==代替equals()对键进行比较的散列映射。专为解决特殊问题设计 |
HashMap后面跟着的星号表示如果没有其他的限制,它就应该是默认的选择,因为它对速度进行了优化。
5. 散列与散列码
关于hashCode()和equals()的问题,相信大家都被碰到过,正确equals()方法满足5个条件
- 自反性。任意x,x.equals(x)一定返回true
- 对称性。任意x和y,只要y.equals(x)返回true,那么x.equals(y)一定也返回true
- 传递性。任意x,y,z,如果x.equals(y)返回true,y.equals(z)返回true,那么x.equals(z)也返回true
- 一致性。任意x和y,如果对象中用于比较的信息没有改变,那么无论调用多少次x.equals(y),结果都不会改变
- 对任何不是null的x,x.equals(null)一定返回false
hashCode()和equals()方法都是Object中的方法,hashCode()使用对象的地址生成散列码,而hashCode()方法也使用equals()方法判断当前的键是否与哈希表中的键相同。经常有人会说为什么重写hashCode()就必须要重写equals(),因为Object中的equals()比较的是两个对象是否是同一个引用,而自己实现的类要判断内容要判断是否相等一般是要判断值是否相同。而重写了equals()方法就必须要重写hashCode方法,因为java有规定是这么说
- 如果两个对象相等,则hashCode一定相同
- 两个对象相等,对两个方法分别调用equals()的结果都返回true
- 两个对象有相同的hashCode,它们也不一定是相等的(因为会有hash碰撞,这里就不展开讲了,可以百度一下hash碰撞),所以要比较两个对象内容是否相同必须先比较他们的hashCode
- hashCode的默认行为是使用对象的地址生成散列码,如果没有重写hashCode的话,那这个类的两个对象无论如何都不会相等,即使两个对象指向相同的数据
因为有以上的先决条件,使得重写hashCode()就必须重写equals()。当然,hashCode()只在散列表中才有用。
散列的存在是为了解决速度,散列使得查询得以快速运行,散列将键的信息保存在数组中,因为数组具有最快的随机访问速度,所以查起来很快,由于数组的大小是固定的,所以我们键的数量被数组限制了要怎么办呢,所以,数组中不保存键的本身,通过hashCode()方法得的散列码,作为数组的下标。
6. 容器类的快速失败(fail-fast)机制
java的容器类有一种保护机制,可以防止多个进程同时修改同一容器的内容。这就是快速失败(fail-fast)机制,它会探查容器上任何除了你的进程进行的操作以外的所有变化,一旦发现其他进程修改了容器,就会立刻抛出ConcurrentModifacationException异常。
7. 持有引用
对象是可获得的,这代表了你可以在栈中有一个引用,这个引用会指向这个对象。如果对象是可获得的,那么垃圾回收器将不会回收它,如果想持有某个对象的引用,也希望可以允许垃圾回收器可以清理释放它,那么就要用到Reference对象。这样你就可以继续使用该队该对象,在内存要消耗殆尽的时候又允许释放该对象。
从Jdk1.2开始,在java.lang.ref包下就提供了三个类:SoftReference(软引用),PhantomReference(虚引用),WeakReference(弱引用),它们分别代表了系统对对象的中的三种引用方式:软引用,虚引用以及弱引用。软引用用以实现内存敏感的高速缓存,弱引用为实现“规范映射”而设计的,它不妨碍垃圾回收器回收映射的键或值。弱引用用来调度回收前的清理工作。
容器类中有一种特殊的Map,那就是WeakHashMap,它用来存放WeakReference。它使得规范映射更容易使用。WeakHashMap允许垃圾回收器自动清理键和值,所以它显得十分便利。
总结
本章我们对java的容器类有了更深层次的探究,我们知道了完整的容器类框架,学习了collections的通用方法,比较了各种Map,了解了散列和散列码和容器类的快速失败机制,最后我们还学到了java的三种Reference类,到此,本章就结束了。

















 2147
2147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









