



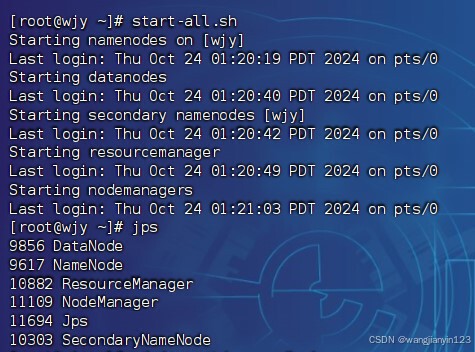
1.启动HDFS服务和YARN服务
start-all.sh
2.输入jps查看进程,是否启动成功
3.进入网页:http://wjy:9870(wjy为主机名)
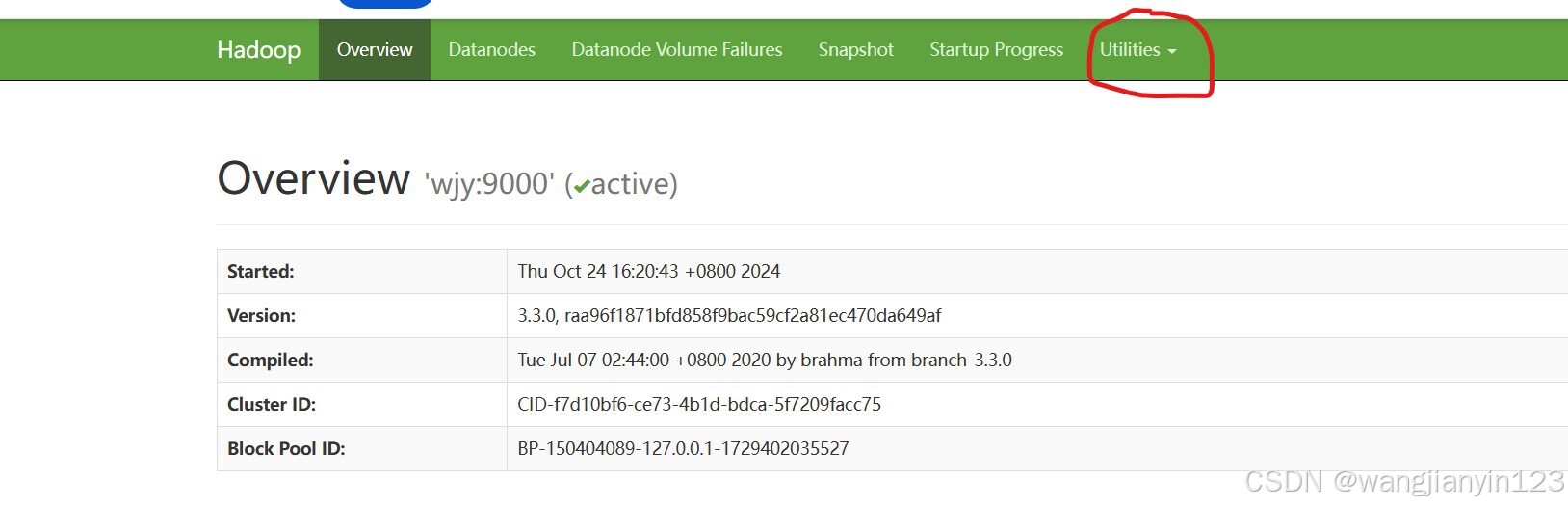
4.点击Utilities下的Browse the file system,进入后并没有什么

5.输入命令
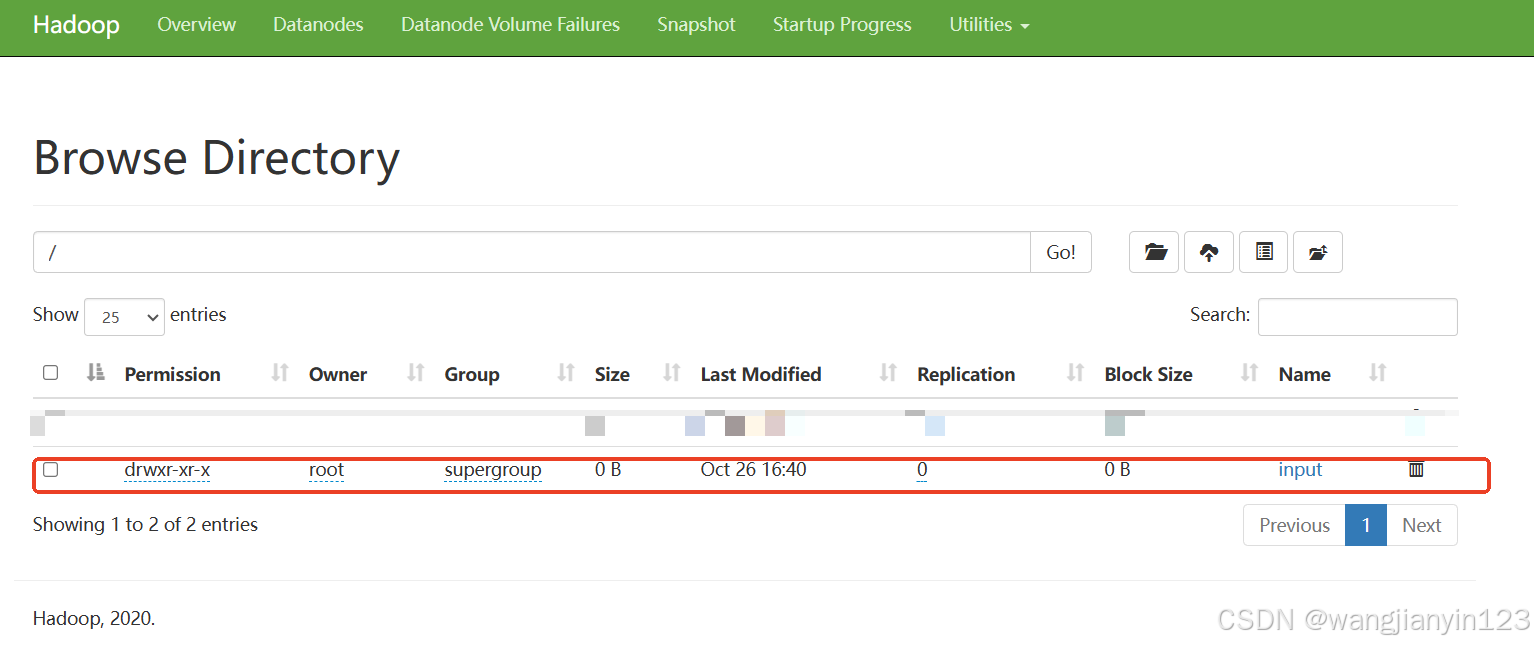
hadoop fs -mkdir -p /input (在HDFS文件系统上创建一个文件夹)

然后刷新网页会出现如图:
6.再输入命令
vim 1.txt

进入到1.txt,编辑输入如下内容(内容随意):

7.退出编辑后输入命令
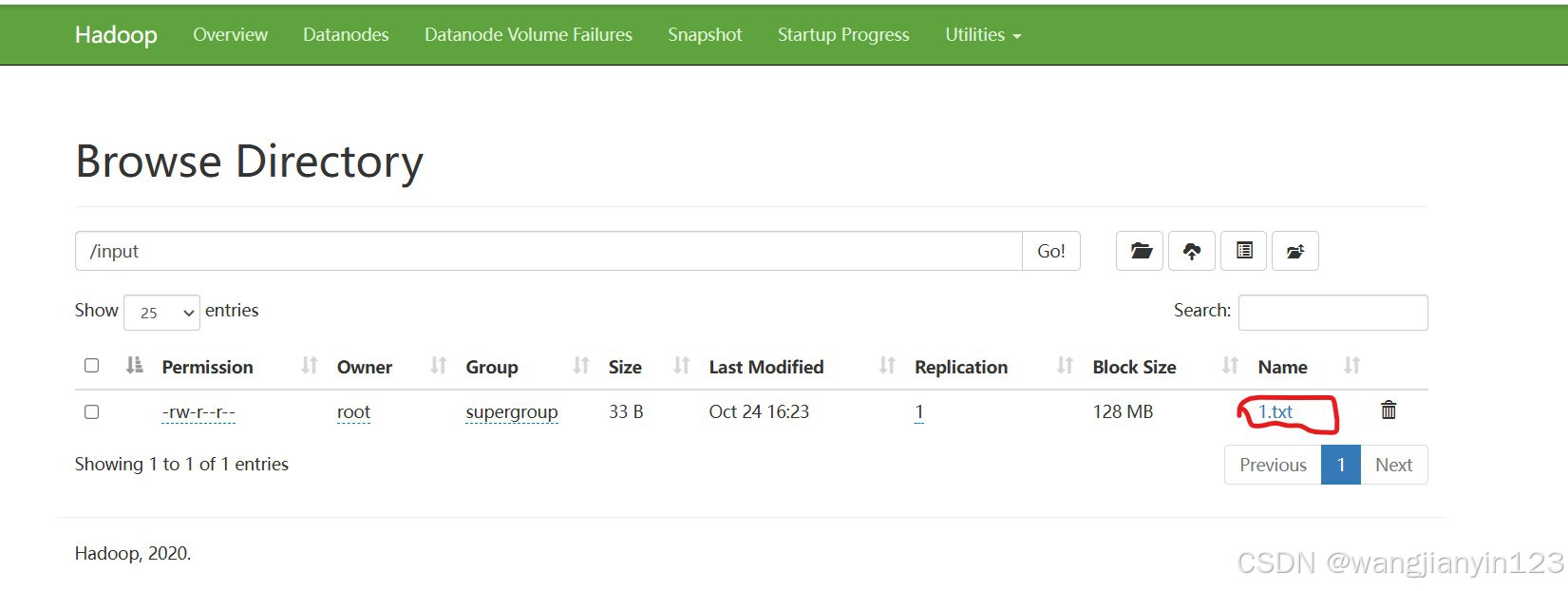
hadoop fs -put 1.txt /input (从本地上传一个测试文件)

8.然后到网页界面刷新input路径下就会出现此界面
9.然后输入命令进入hadoop根目录下
cd /export/server/hadoop
![]()
再输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input/1.txt /output

10.再回到网页界面刷新后就会看到有一个output
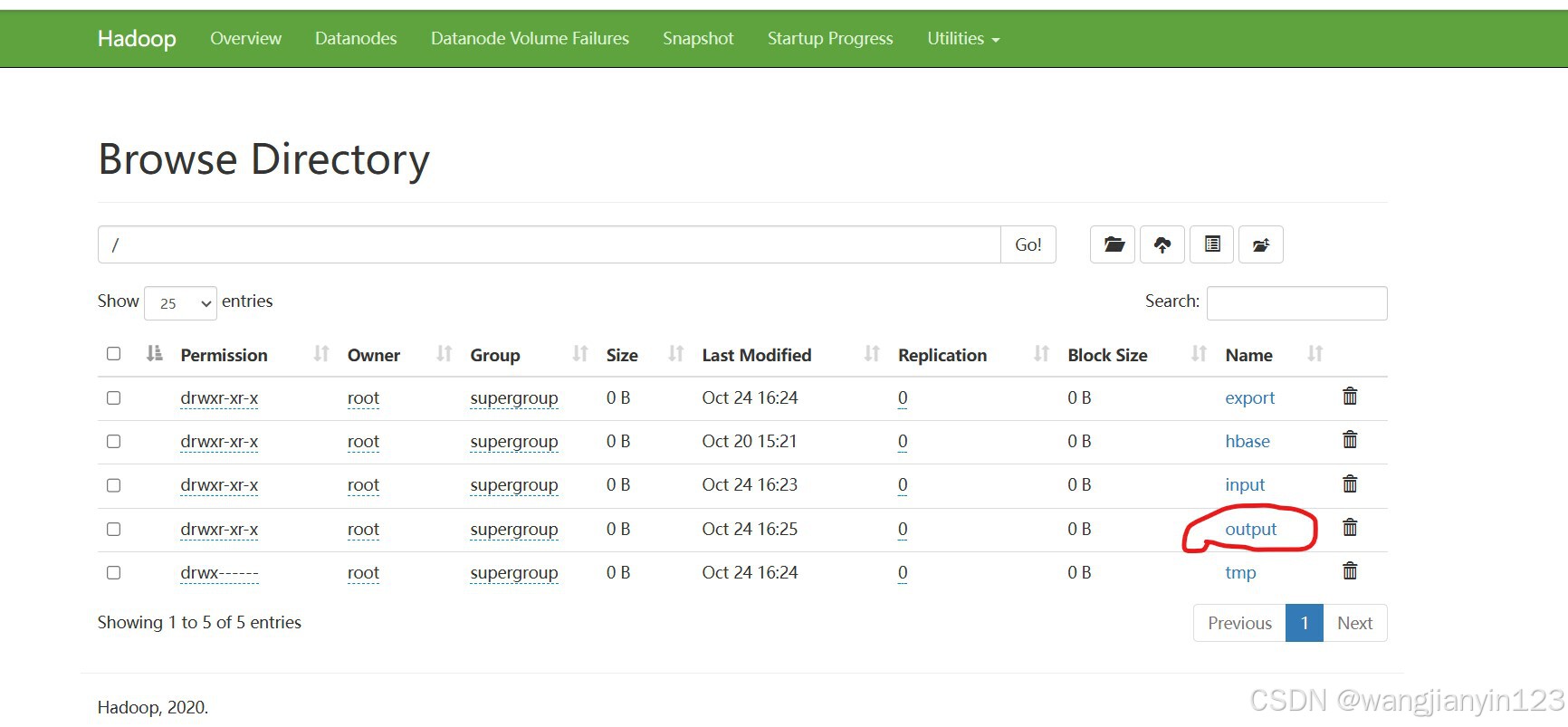
11.点击进入
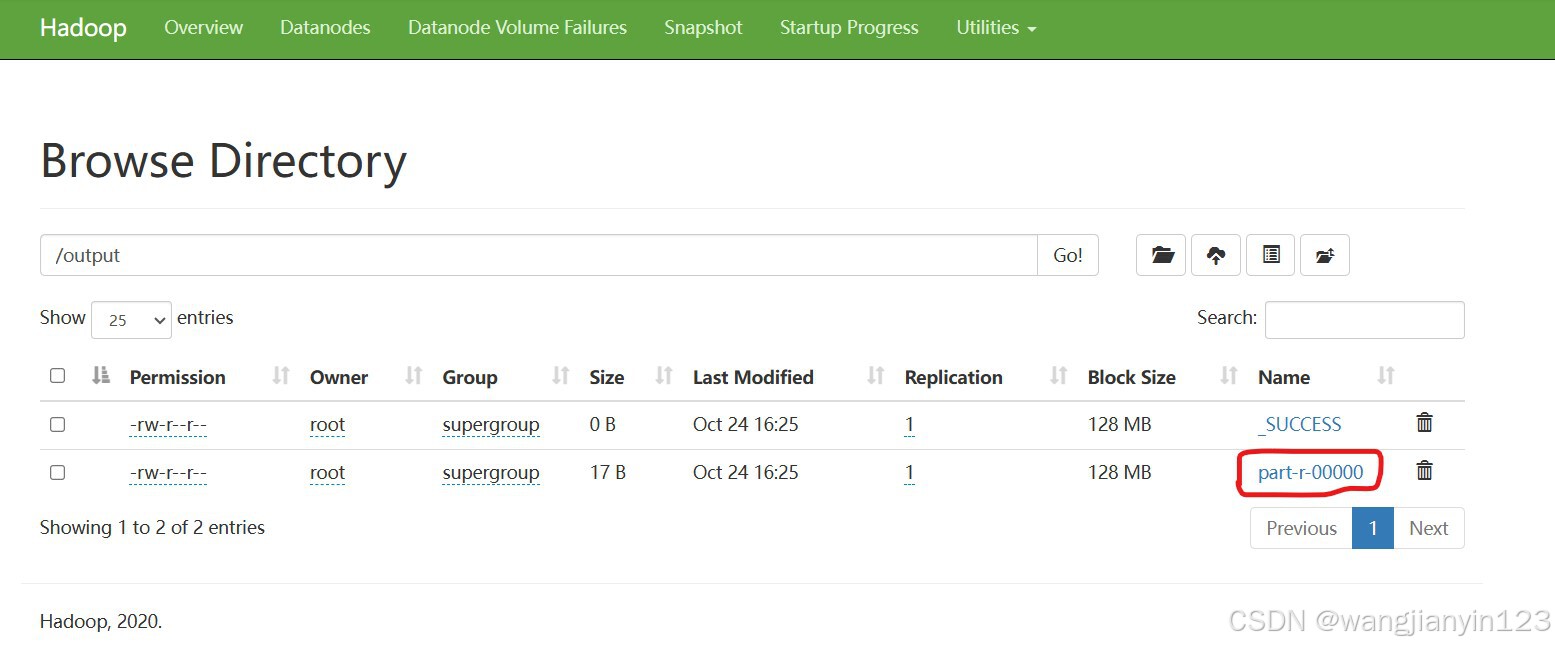
12.再点击如上红色圈住的文件后,点击下载
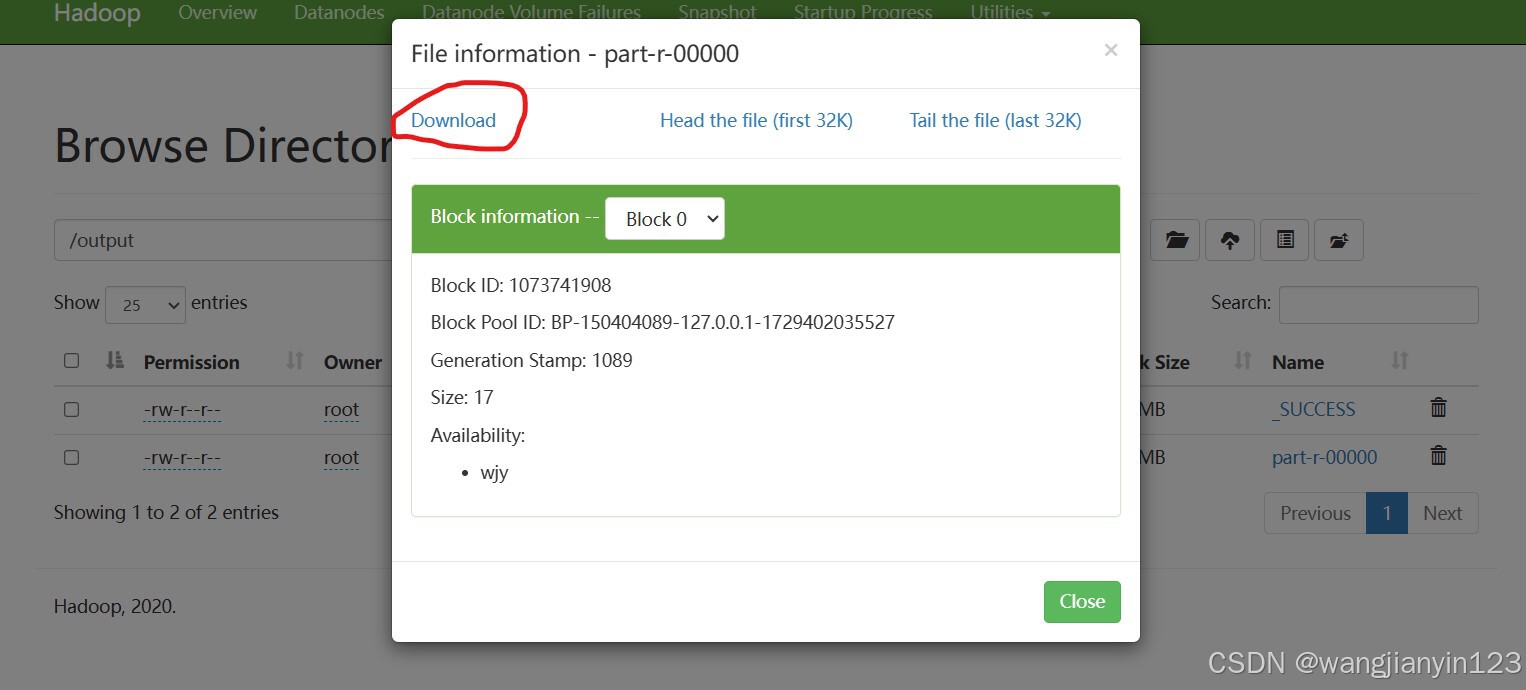
13.下载好之后,使用记事本打开
14.打开之后就会看见,之前编辑输入的内容

15.或者在第10步输入命令后就在输入命令
hadoop fs -cat /output/*
就会看到之前输入的内容


















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









