




Streamlit
Streamlit开发文档
官方文档:https://docs.streamlit.io/
中文文档:https://blog.youkuaiyun.com/weixin_44458771/article/details/135495928
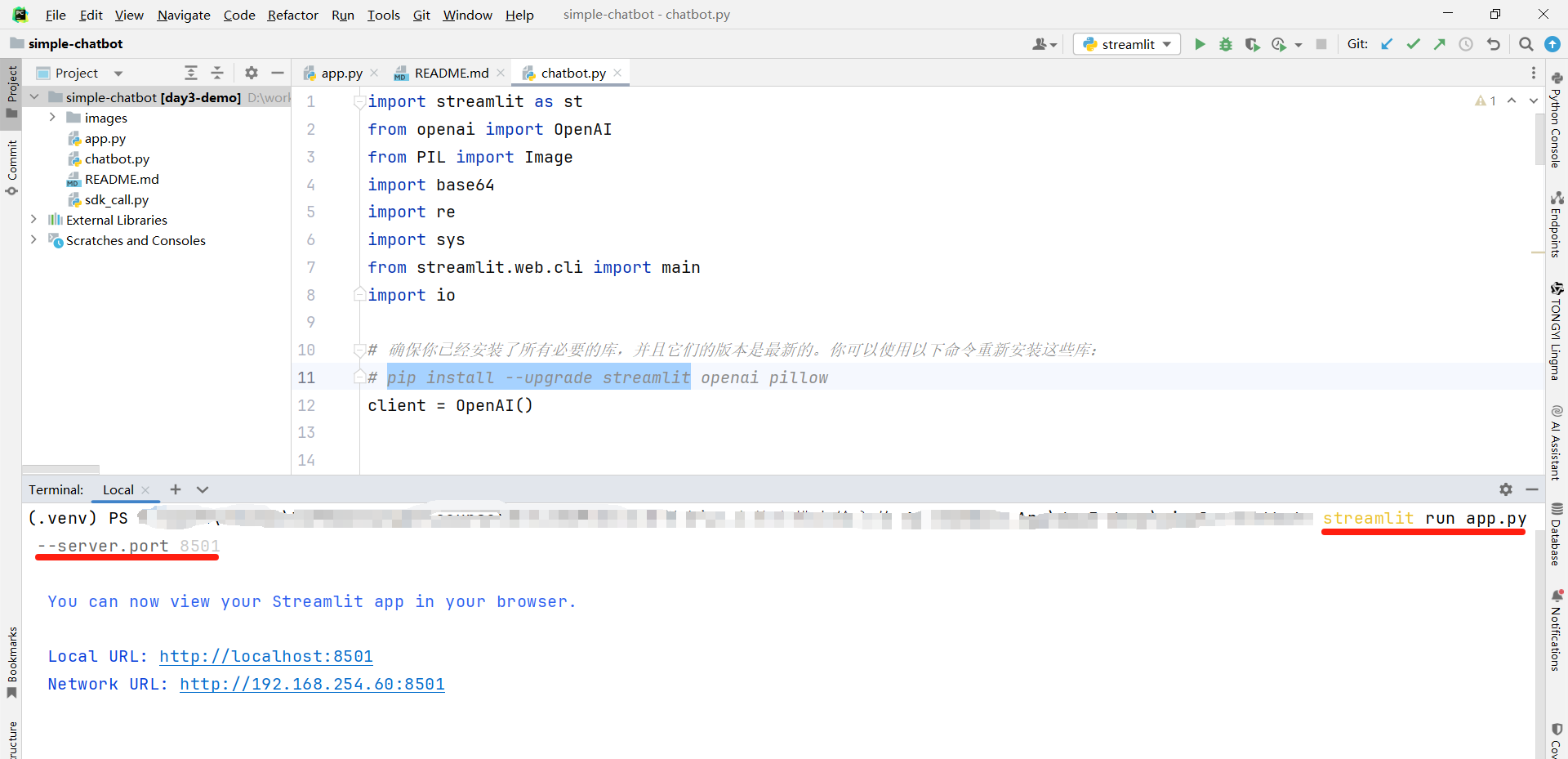
Streamlit命令行启动
pip install streamlit
streamlit run app.py --server.port 8501
配置Pycharm调试Streamlit应用
开发环境
PyCharm Community Edition 2024
Win10/11
Streamlit 1.39.0
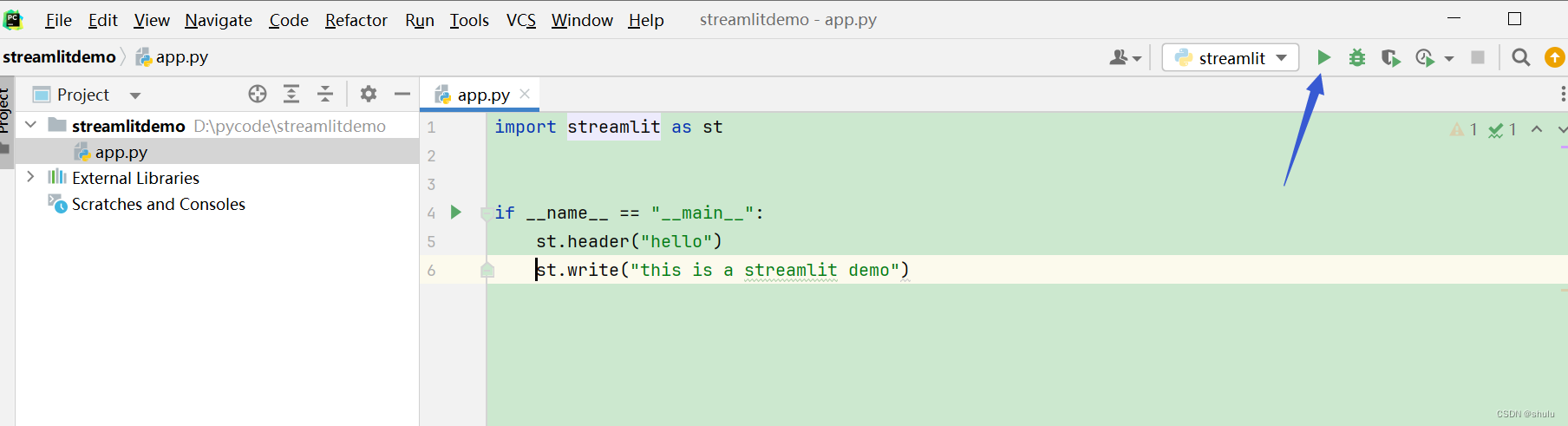
创建应用
app.py
import streamlit as st
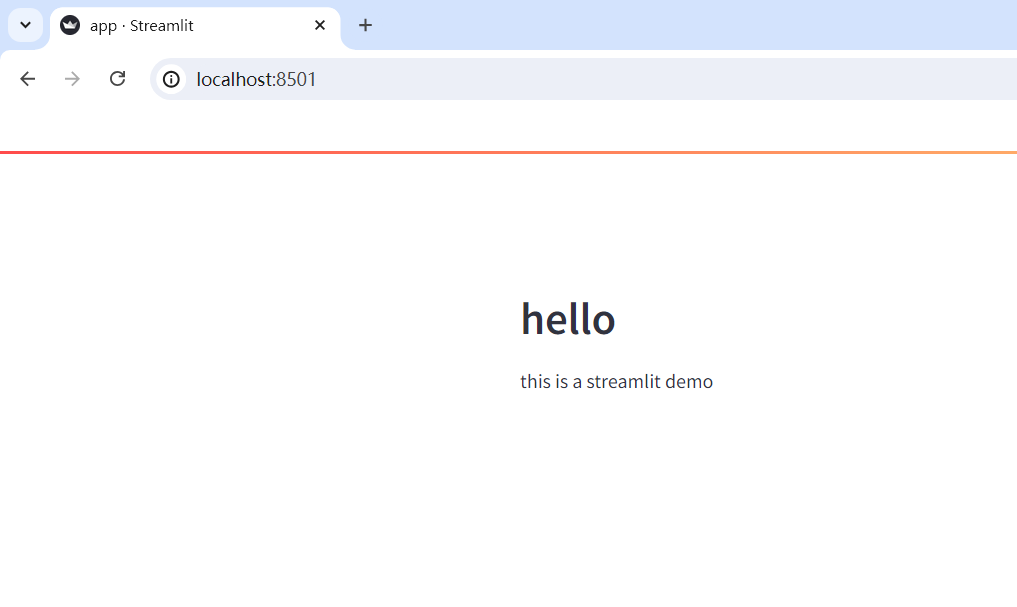
st.header("hello")
st.write("this is a streamlit demo")
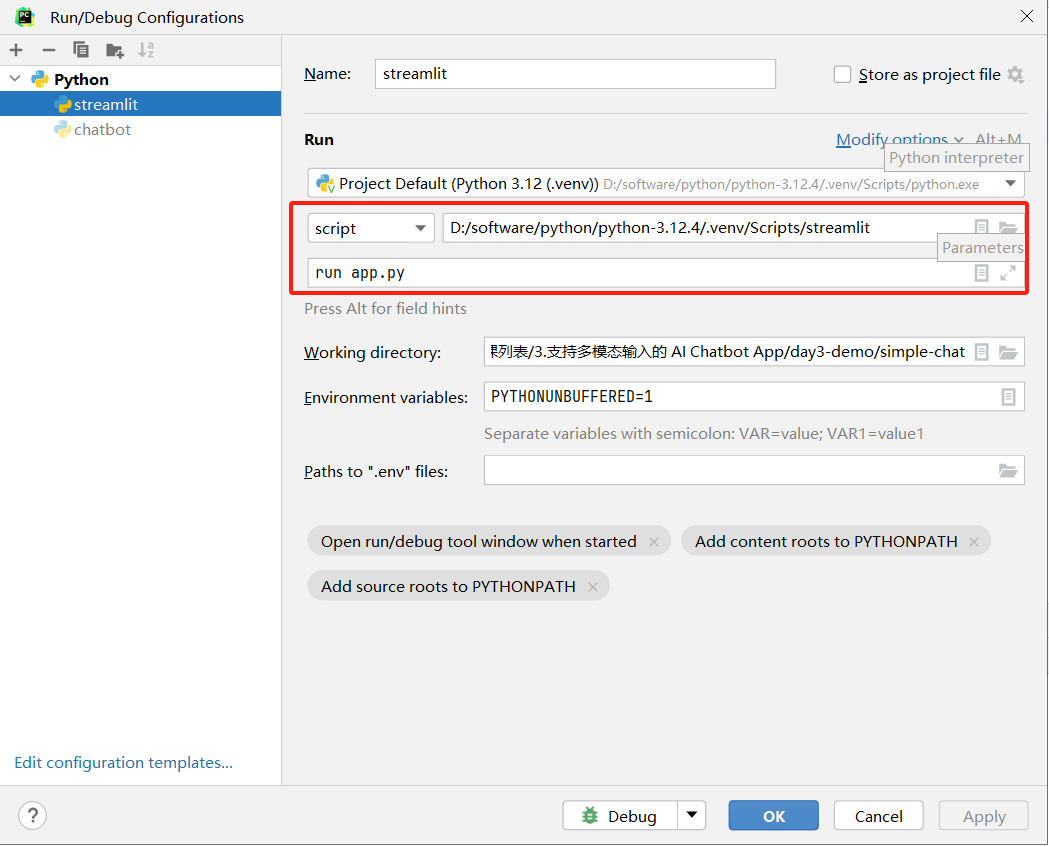
启动应用
设置参数:
script:D:/software/python/python-3.12.4/.venv/Scripts/streamlit
script parameters:run app.py
调试应用
点击调试按钮会报错。
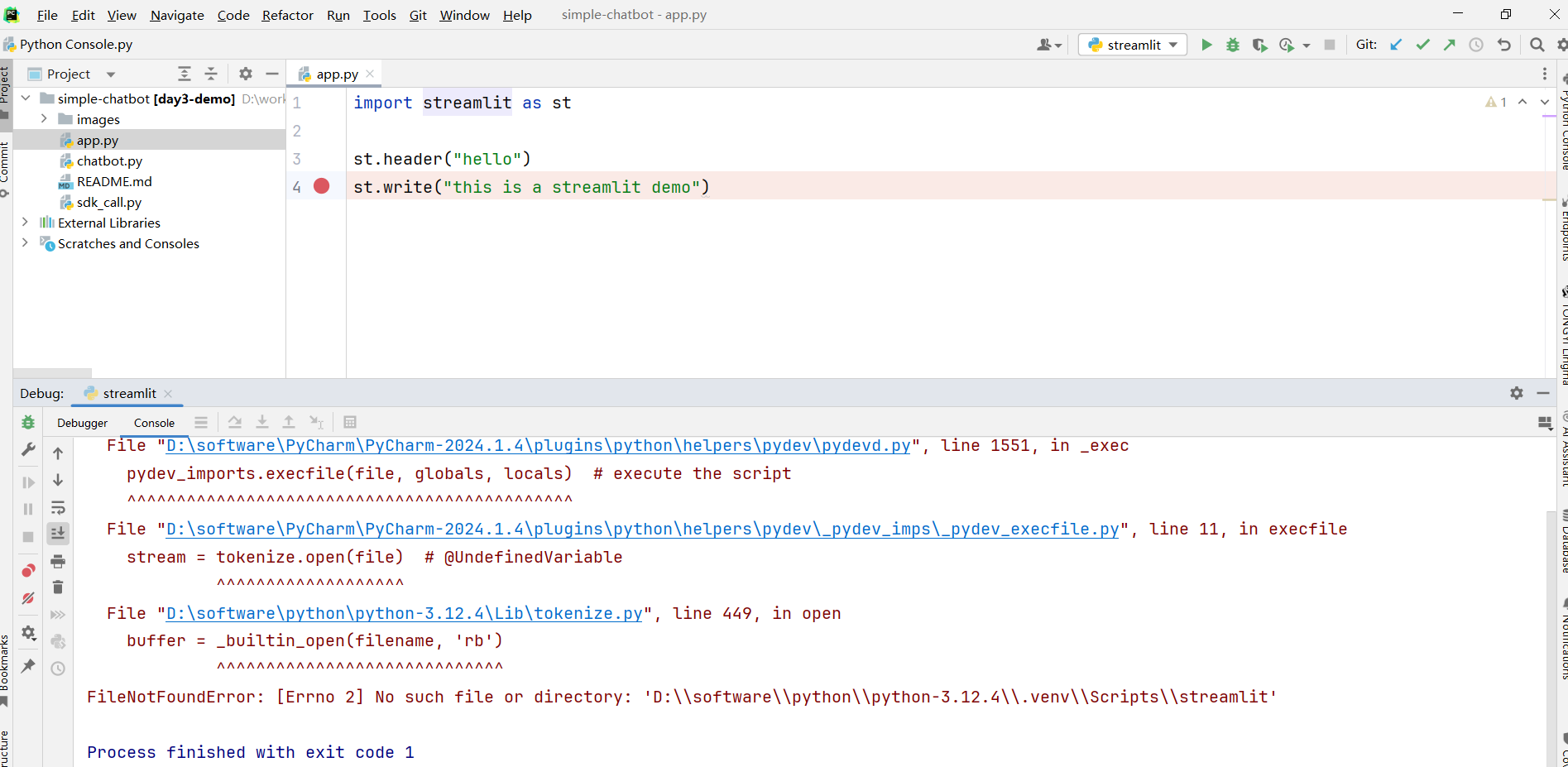
经过分析,是因为选择的<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">script</font>, 文件名为
<font style="color:rgb(51, 51, 51);">D:/software/python/python-3.12.4/.venv/Scripts/</font><font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">streamlit.exe</font>
streamlit.exe 是一个二进制文件,导致字符集解析出错。在这里把 linux 环境下的 streamlit 复制过来。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import re
import sys
from streamlit.web.cli import main
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
sys.exit(main())
复制到 D:/software/python/python-3.12.4/.venv/Scripts/
再次启动 debug 按钮,报错如下
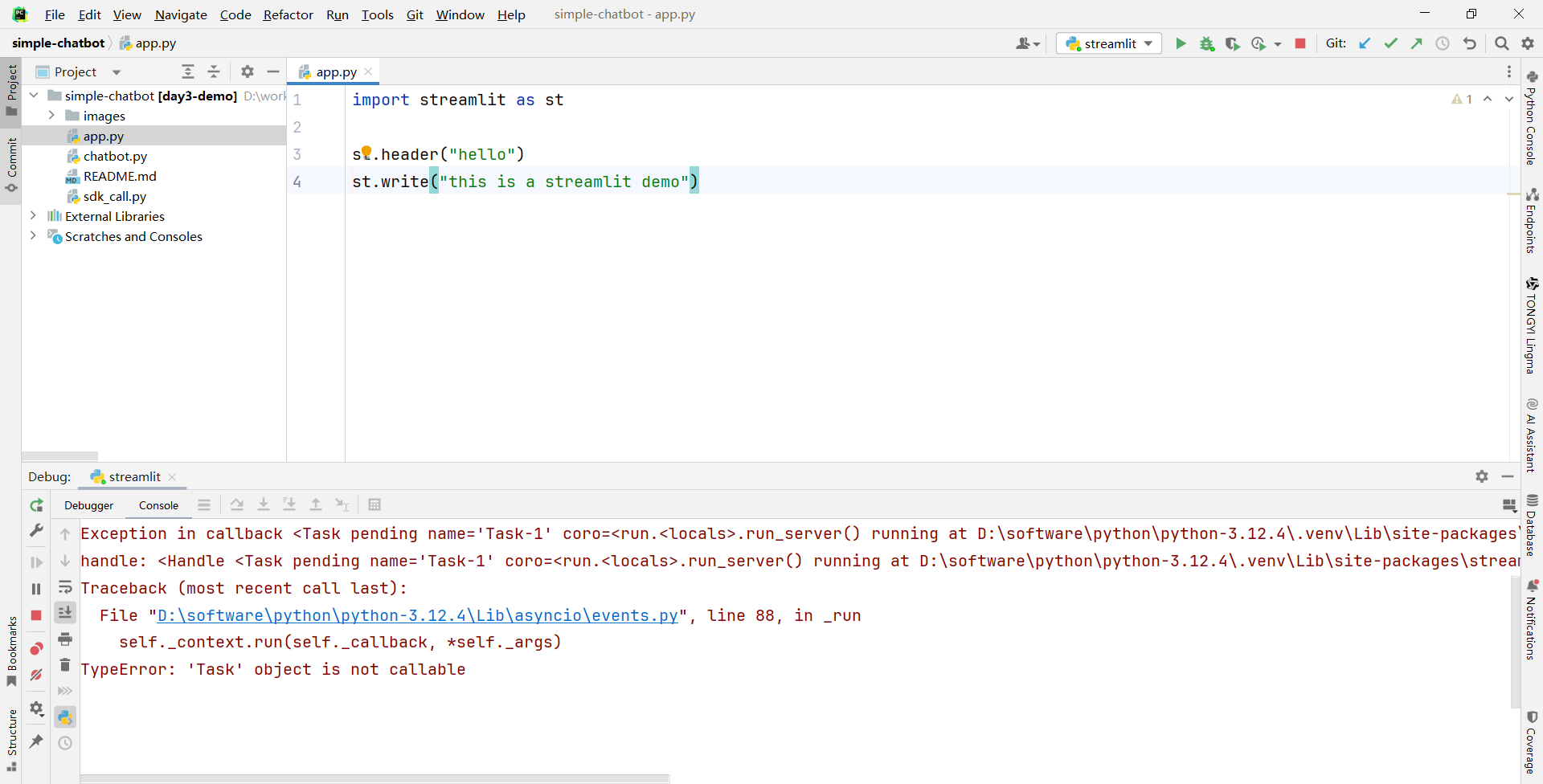
解决如下:
Help | Find Action | Registry | python.debug.asyncio.repl 去掉勾。
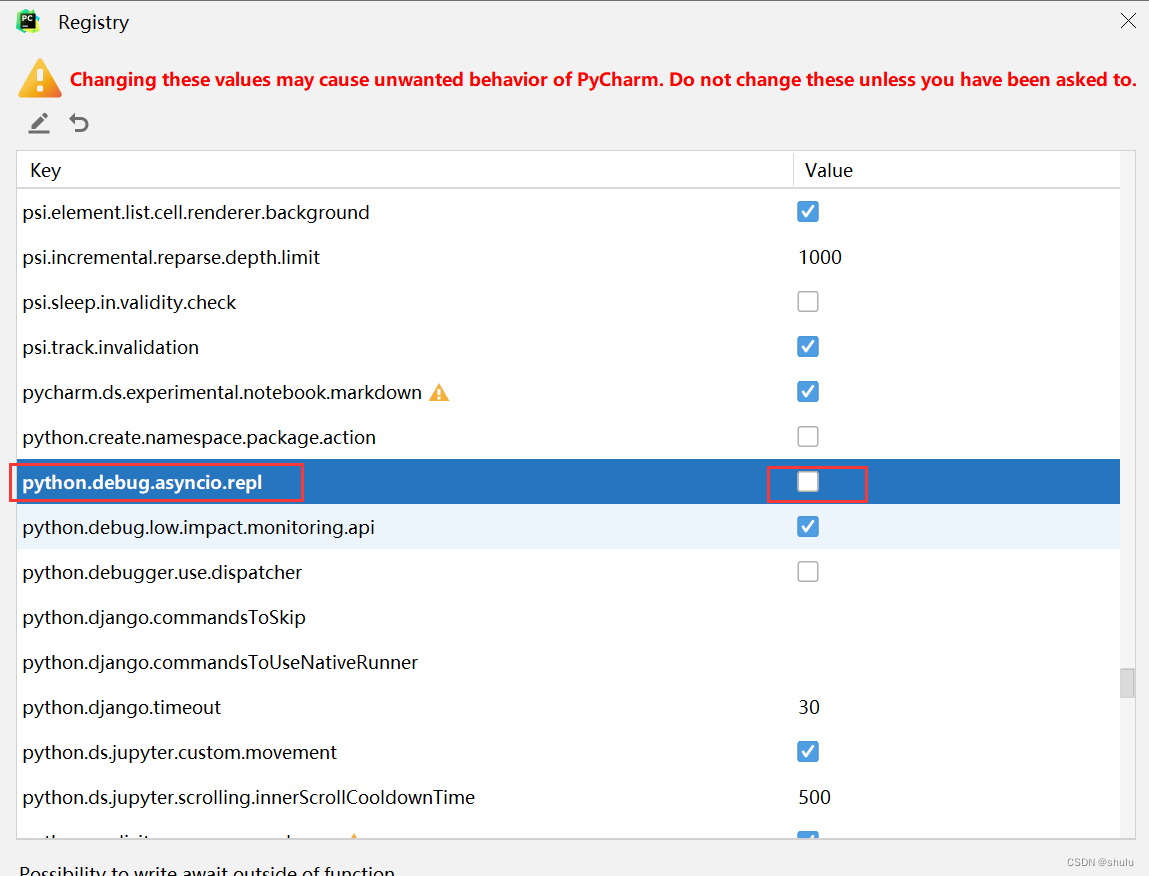
再次点击 debug 就可以正常调试了。


















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











