



 本文深入探讨了浮点数的不同精度类型,包括双精度、单精度和半精度,重点介绍了半精度浮点数的起源、用途及布局。通过对比三种浮点数的结构,解析了它们的表示规则,并讨论了在深度学习等场景中使用半精度浮点数的优势。
本文深入探讨了浮点数的不同精度类型,包括双精度、单精度和半精度,重点介绍了半精度浮点数的起源、用途及布局。通过对比三种浮点数的结构,解析了它们的表示规则,并讨论了在深度学习等场景中使用半精度浮点数的优势。
浮点数是计算机上最常用的数据类型之一,有些语言甚至数值只有浮点型(Perl,Lua同学别跑,说的就是你)。
常用的浮点数有双精度和单精度。除此之外,还有一种叫半精度的东东。
双精度64位,单精度32位,半精度自然是16位了。
半精度是英伟达在2002年搞出来的,双精度和单精度是为了计算,而半精度更多是为了降低数据传输和存储成本。
很多场景对于精度要求也没那么高,例如分布式深度学习里面,如果用半精度的话,比起单精度来可以节省一半传输成本。考虑到深度学习的模型可能会有几亿个参数,使用半精度传输还是非常有价值的。
Google的TensorFlow就是使用了16位的浮点数,不过他们用的不是英伟达提出的那个标准,而是直接把32位的浮点数小数部分截了。据说是为了less computation expensive。。。
比较下几种浮点数的layout:
双精度浮点数
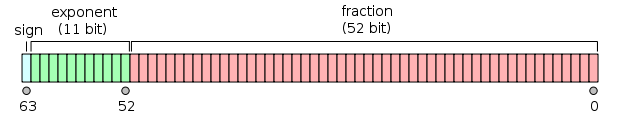
单精度浮点数

半精度浮点数
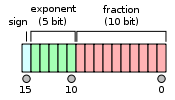
它们都分成3部分,符号位,指数和尾数。不同精度只不过是指数位和尾数位的长度不一样。
解析一个浮点数就5条规则
如果指数位全零,尾数位是全零,那就表示0
如果指数位全零,尾数位是非零,就表示一个很小的数(subnormal),计算方式 (−1)^signbit × 2^−126 × 0.fractionbits
如果指数位全是1,尾数位是全零,表示正负无穷
如果指数位全是1,尾数位是非零,表示不是一个数NAN
剩下的计算方式为 (−1)^signbit × 2^(exponentbits−127) × 1.fractionbits
常用的语言几乎都不提供半精度的浮点数,这时候需要我们自己转化
原文地址:https://blog.youkuaiyun.com/sinat_24143931/article/details/78557852

















 3302
3302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









