









一、单线性回归问题
参考:https://blog.youkuaiyun.com/qq_42333474/article/details/119100860
题目一:
您将使用一元线性回归来预测食品车的利润。假设你是一家特许餐厅的首席执行官,正在考虑在不同的城市开设一家新的分店。该连锁店已经在不同的城市有卡车,你有这些城市的利润和人口数据。您希望使用这些数据来帮助您选择下一个要扩展到的城市。
文件ex1data1.txt包含我们的线性回归问题的数据集。第一栏是一个城市的人口,第二栏是那个城市的餐车利润。利润的负值表示亏损。ex1.m脚本已经设置好为您加载这些数据。
数据集ex1data1.txt:
8.5781,12
6.4862,6.5987
5.0546,3.8166
5.7107,3.2522
14.164,15.505
5.734,3.1551
8.4084,7.2258
5.6407,0.71618
5.3794,3.5129
6.3654,5.3048
5.1301,0.56077
6.4296,3.6518
7.0708,5.3893
6.1891,3.1386
20.27,21.767
5.4901,4.263
6.3261,5.1875
5.5649,3.0825
18.945,22.638
12.828,13.501
10.957,7.0467
13.176,14.692
22.203,24.147
5.2524,-1.22
6.5894,5.9966
9.2482,12.134
5.8918,1.8495
8.2111,6.5426
7.9334,4.5623
8.0959,4.1164
5.6063,3.3928
12.836,10.117
6.3534,5.4974
5.4069,0.55657
6.8825,3.9115
11.708,5.3854
5.7737,2.4406
7.8247,6.7318
7.0931,1.0463
5.0702,5.1337
5.8014,1.844
11.7,8.0043
5.5416,1.0179
7.5402,6.7504
5.3077,1.8396
7.4239,4.2885
7.6031,4.9981
6.3328,1.4233
6.3589,-1.4211
6.2742,2.4756
5.6397,4.6042
9.3102,3.9624
9.4536,5.4141
8.8254,5.1694
5.1793,-0.74279
21.279,17.929
14.908,12.054
18.959,17.054
7.2182,4.8852
8.2951,5.7442
10.236,7.7754
5.4994,1.0173
20.341,20.992
10.136,6.6799
7.3345,4.0259
6.0062,1.2784
7.2259,3.3411
5.0269,-2.6807
6.5479,0.29678
7.5386,3.8845
5.0365,5.7014
10.274,6.7526
5.1077,2.0576
5.7292,0.47953
5.1884,0.20421
6.3557,0.67861
9.7687,7.5435
6.5159,5.3436
8.5172,4.2415
9.1802,6.7981
6.002,0.92695
5.5204,0.152
5.0594,2.8214
5.7077,1.8451
7.6366,4.2959
5.8707,7.2029
5.3054,1.9869
8.2934,0.14454
13.394,9.0551
5.4369,0.61705
python代码实现:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path = 'C:/Users/Administrator/Desktop/吴恩达机器学习数据集/week1/ex1data1.txt'
data = pd.read_csv(path, header=None,names = ['Population', 'Profit'])
# 读取csv文件
# header = 0是默认情况(即不标明,默认就是header = 0),表示以数据的第一行为列索引,若改names,则第一行数据会丢失(直接修改第一行数据)。
# header=None时,显示每一行数据,添加names,第一行数据不会丢失
# names为横向索引header的名字,可以是数字,如names=range(2,6)
data.head() # 检验数据,可检验5行
data = pd.DataFrame(data) # 生成图表,pandas中方法,也可以直接用data
print(data.head()) # head函数默认输出五行
# 特征归一化(为了使梯度下降得更方
# 便)
data = (data - data.mean()) / data.std() # (原始数据 - 平均值)/ 标准差
data.head()
# 定义代价函数
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2) # X为输入矩阵。*theta的转置为假设函数,-y后整体平方;power函数计算幂
return np.sum(inner) / (2 * len(X))
# 在原始数据集表上增加第0列,总共数据集为三列
data.insert(0, 'Ones', 1)
cols = data.shape[1] # shape函数读取data中的二维的长度,即为数据的列数,此时共有三列,clos=3;shape[0]为行数
X = data.iloc[:, :-1] # X为数据中的所有行,以及除了最后一列,此时X中有ones列与population列,X是72*2的数据,列数等同于[0:2]
y = data.iloc[:, cols - 1:cols] # y为最后一列数据,等同于[2:3]
X = np.matrix(X.values) # 将X转换为矩阵,72*2
y = np.matrix(y.values) # 将y转换为矩阵,72*1
theta = np.matrix(np.array([0, 0])) # theta向量是两个值都初始化为0的一维向量,1*2,转置后为2*1
print("初始theta值的代价为:")
print(computeCost(X, y, theta)) # 此时theta为初始自定义的值(0,0),计算出了此时输入的代价
# 定义梯度下降函数
def gradientDecent(X, y, theta, alpha, iters): # alpha为学习率,iters为设定迭代次数
tempt = np.matrix(np.zeros(theta.shape)) # theta的维度的所有数据全部初始化为0
parameters = int(theta.ravel().shape[1]) # ravel函数将theta的维度降为一维,shape[1]为列数
cost = np.zeros(iters) # 初始化代价,值为0的有iters个值的矩阵
for i in range(iters):
error = (X * theta.T) - y # 预测值与实际值的误差,为72*1矩阵,放在大循环内小循环外,每次迭代后的theta进行了更新,error值随之变换。
for j in range(parameters): # 梯度下降重要步骤,根据公式将每个theta[j]的值下降一次
term = np.multiply(error, X[:, j]) # error与第j列的向量对应位置相乘并最终求和,之前增加ones列用于与1相乘
tempt[0, j] = theta[0, j] - ((alpha / len(X)) * (np.sum(term)))
cost[i] = computeCost(X, y, tempt) # 计算第i此迭代时此theta值的代价
theta = tempt # 将theta向量更新,进行下次迭代循环继续处理theta
return theta, cost
# 赋值
alpha = 0.01
iters = 1500
g, cost = gradientDecent(X, y, theta, alpha, iters)
print("参数theta向量:")
print(g)
# 预测70000人口的时候,根据公式h= theta0 + theta1*X
predict1 = (1, 7) * g.T # g.T为g的转置,g为1*2的参数向量 ,1*theta[0],7为population,7*参数theta[1]得到预测值profit
print("预测值1:")
print(predict1)
# 作图
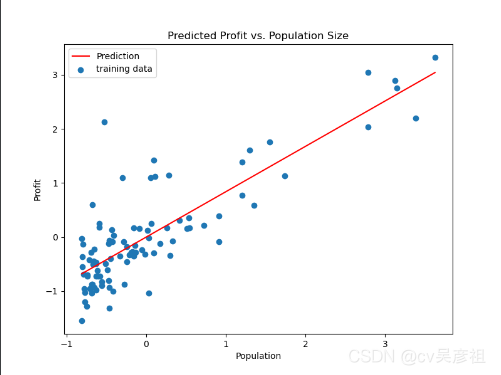
x = np.linspace(data.Population.min(), data.Population.max(), 100) # 生成等差数列,100个等差点
f = g[0, 0] + (g[0, 1] * x) # f为假设函数,theta0+theta1*x
fig, ax = plt.subplots(figsize=(8, 6)) # 创建作图画布
ax.plot(x, f, 'r', label='Prediction') # 画出线,红色,名为Prediction
ax.scatter(data.Population, data.Profit, label='training data') # scatter为散点图
ax.legend(loc=2) # 在图上标明一个图例,用于说明每条曲线的文字显示,loc为第二象限
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
、
题目二:多线性回归问题
在这一部分,你将实施多变量线性回归来预测房价。假设你正在卖房子,你想知道一个好的市场价格是多少。一种方法是首先收集最近出售的房子的信息,并制作一个房价模型。文件ex1data2.txt包含俄勒冈州波特兰市房价的训练集。第一栏是房子的大小(以平方英尺为单位),第二栏是卧室的数量,第三栏是房子的价格。ex1 multi.m脚本已经设置好,可以帮助您逐步完成本练习。
数据集
2104,3,399900
1600,3,329900
2400,3,369000
1416,2,232000
3000,4,539900
1985,4,299900
1534,3,314900
1427,3,198999
1380,3,212000
1494,3,242500
1940,4,239999
2000,3,347000
1890,3,329999
4478,5,699900
1268,3,259900
2300,4,449900
1320,2,299900
1236,3,199900
2609,4,499998
3031,4,599000
1767,3,252900
1888,2,255000
1604,3,242900
1962,4,259900
3890,3,573900
1100,3,249900
1458,3,464500
2526,3,469000
2200,3,475000
2637,3,299900
1839,2,349900
1000,1,169900
2040,4,314900
3137,3,579900
1811,4,285900
1437,3,249900
1239,3,229900
2132,4,345000
4215,4,549000
2162,4,287000
1664,2,368500
2238,3,329900
2567,4,314000
1200,3,299000
852,2,179900
1852,4,299900
1203,3,239500
python代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path = 'C:/Users/Administrator/Desktop/吴恩达机器学习数据集/week1/ex1data2.txt'
#多个特征相差过大,容易震荡,故需要归一化操作
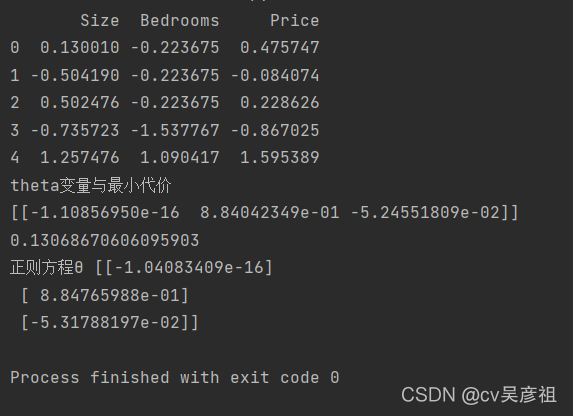
data = pd.read_csv(path,header=None,names=['Size','Bedrooms','Price'])
data = (data-data.mean())/data.std() #均值化归一操作,mean()函数对所有的值求平均值,std()函数为标准差
print(data.head())
#接下来初始化数据集变量,首先将变量从数据集中分离出来,然后转化为matrix矩阵才能相乘,theta初始化为全0的矩阵
data.insert(0, 'ones', 1) #在第0列加一列值为1,与theta0进行相乘
cols = data.shape[1] #数据的列数
X = data.iloc[:, 0 : cols-1] #分割出y矩阵
y = data.iloc[:, cols-1:cols] #分割出y矩阵
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix(np.array([0,0,0])) #多变量梯度需要三个theta,初始化为0
#定义代价函数
def computeCost(X, y, theta):
inner = np.power(((X*theta.T) - y), 2) #X*theta.T为X矩阵和theta转置矩阵相乘
return np.sum(inner) / (2*len(X))
#定义梯度下降函数
def gredientDecent(X, y, theta, alpha, iters): #alpha为学习率 iters为迭代次数
tempt = np.matrix(np.zeros(theta.shape)) #求一个与theta矩阵大小相等的全0矩阵
parameters = int(theta.ravel().shape[1]) #ravel转化为一维,返回1行的个数
cost = np.zeros(iters) #cost为iters个值的一维矩阵,仅有一行,iters列
for i in range(iters):
error = (X * theta.T) - y # 公式,外层循环中每一次theta改变
for j in range(parameters): #内层循环使用梯度下降算法改变theta的值至代价函数最小
term = np.multiply(error, X[ :, j]) #本次迭代theta值,减法项每项对应×输入矩阵中第j列
tempt[0 , j] = theta[0,j]-((alpha/len(X))*(np.sum(term))) #tempt与theta都是一行多列的二维矩阵
theta = tempt # j循环后,theta中的每个属性值都进行了改变,并保存在tempt临时变量中
cost = computeCost(X, y, theta)
return theta, cost # 梯度下降算法多次下降最终得到theta矩阵
alpha = 0.01
iters = 1500
g,cost = gredientDecent(X, y, theta, alpha, iters)
print("theta变量与最小代价")
print(g)
print(cost)
正则方程计算theta,适用于10000特征以内,计算量小,计算速度快:
def normalEqn(X, y):
theta = np.linalg.inv(X.T @ X) @ X.T @y #np.linalg.inv():矩阵求逆; X.T表示矩阵的转置; @表示
return theta
theta2 = normalEqn(X, y)
print("正则方程θ", theta2)

















 2713
2713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









