







最近吴恩达在一次内部分享中提到,“较低参数规模的大模型加上Agent能胜过GPT5”,他呼吁大家去探索Agent,这个结论跟我最近对AI的探索比较契合。
开源大模型的可用性
当下市面上涌现出数百个大规模的模型,其中开源的有几十个。在这些开源可用的模型当中,LLama2-70B和QWen-72B的能力尤为出色。它们的性能或接近,或部分能力甚至已经超过了GPT3.5-Turbo。这意味着,大家有足够多的选择和可能性。
接下来,我们将进行一系列的评测,涉及的模型包括LLama2-70B、通义千问-72B、GPT3.5以及GPT4。这次评测的主要目的并不是验证这些模型的能力,而是通过这些评测,给大家直观地展示开源模型和GPT4之间存在的差距,并且让大家看到这个差距是可以被弥补的。为了排除多语言因素对评测结果的影响,我们选择统一使用英文进行评测。整个评测过程中,我们将对模型进行三道题的测试。
首先,我们来看第一道题,这是一道关于Linux的题目。我们的任务是将一个服务转变成被systemctl托管的服务。
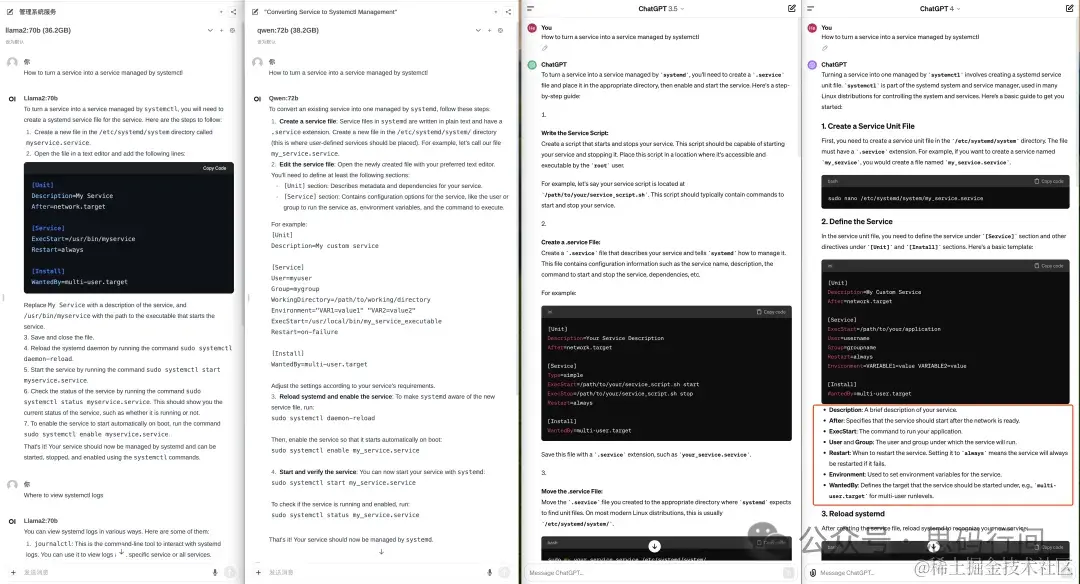
截图从左到右,依次是LLama2-70B、通义千问-72B、GPT3.5、GPT4
从答案中我们可以看出,前三个模型的答案是相似的,都提供了解决问题的步骤。然而,GPT4在答案的结构化和详细程度上做得更好一些。尽管如此,我们有理由相信,如果我们使用高度标准化的Promptÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









