




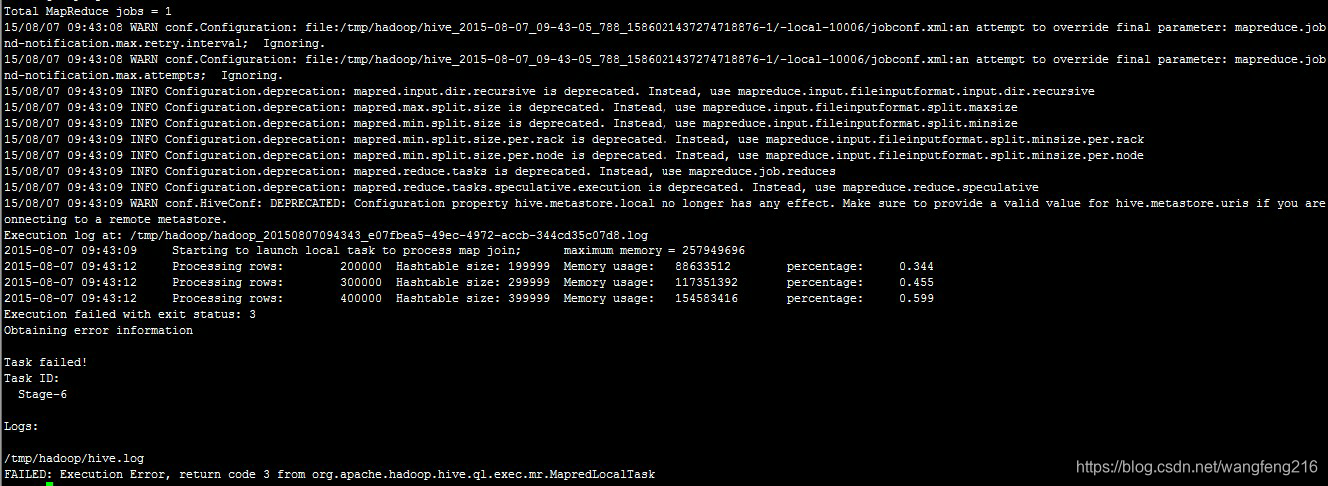
set hive.auto.convert.join=ture 解决
![]()
 博客提及通过设置set hive.auto.convert.join=ture来解决相关问题,涉及大数据领域中Hive的应用,利用该设置可对Hive相关操作进行优化或解决特定问题。
博客提及通过设置set hive.auto.convert.join=ture来解决相关问题,涉及大数据领域中Hive的应用,利用该设置可对Hive相关操作进行优化或解决特定问题。
set hive.auto.convert.join=ture 解决
![]()
 8326
1338
3190
3141
1万+
2082
2万+
8326
1338
3190
3141
1万+
2082
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























