



 本文深入探讨了虚拟化技术,包括虚拟化CPU和内存的过程。详细解释了Direct Execution、Limited Direct Execution的问题与解决方案,以及进程间切换的挑战。此外,文章还介绍了多种调度算法,如FIFO、SJF、STCF、RR、MLFQ、CFS等,并对比了各自的优缺点。最后,阐述了地址空间的概念,以及如何通过Paging和多级页表机制实现内存虚拟化。
本文深入探讨了虚拟化技术,包括虚拟化CPU和内存的过程。详细解释了Direct Execution、Limited Direct Execution的问题与解决方案,以及进程间切换的挑战。此外,文章还介绍了多种调度算法,如FIFO、SJF、STCF、RR、MLFQ、CFS等,并对比了各自的优缺点。最后,阐述了地址空间的概念,以及如何通过Paging和多级页表机制实现内存虚拟化。
OSTEP学习笔记-Virtualization
Process
进程是由 内存中地址空间的内容、CPU寄存器中的内容(PC、栈指针等)和I/O信息(打开的文件)等组成
Machine state有三种:running ready blocked
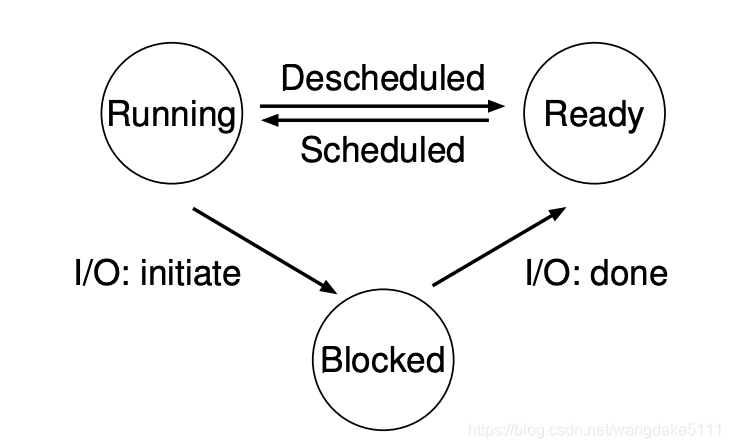
OS中的数据结构:Process List
Process API
Direct Execution
为了虚拟化CPU,想到的解决方法首先是通过time sharing,即每个进程运行一段时间。
出现的两个难题:
- 性能:如何在不增加系统过多的开销的情况下实现虚拟化
- 控制:如何在高效运行进程的同时保有对CPU的控制
Limited Direct Execution
Direct Execution的意思就是让进程的指令直接在CPU上运行,这样的解决方案是最简单的,但是这样会出现的问题是:OS无法得知程序是否做了某些我们不想让他做的(因为拥有所有权限)、如何进行time sharing。
Problem 1: 限制操作
尽管直接在CPU上运行很快,但是由于进程拥有所有权限,导致它们可能会做一些我们不想进程做的事(如随意访问计算机资源),所以一种办法就是限制操作。所以解决方案就是使用两种模式:kernel mode & user mode 。
一般的指令都在user mode下执行,当需要system call时,进程会通过trap指令陷入kernel mode。 在这个过程中,硬件需要确保保存所有的 caller‘s register(调用者寄存器)。(在x86中,会将这些都压入kernel stack中)
OS在boot阶段将安装好trap table,所以当发生trap时,通过system-call number就能正确跳转到system-call。

LDE protocol有两个阶段
- boot阶段,内核初始化trap table,这时CPU会记住他们的位置为了后面的使用
- running阶段,当一个进程运行时,内核会在调用return-from-trap之前设置一些东西(分配在process list上的节点,分配内存)以便可以使进程开始运行。
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
Problem 2: 进程间切换
第二个问题是进程间如何切换,我最开始也觉得这是个很简单的事,毕竟有os调度,但书中提到了,OS也是个软件,本身也是需要time sharing的(不禁让我感觉开始套娃)。所以是怎么解决的呢?
在早期,一些developer的方法是cooperative approach,这种方法是当进程调用system call时,将控制权返还给os,但是其中的问题是,假如某个恶意程序(或bug)写了一个无限循环,并且在其中不写入system call,那这个程序将永远抢占CPU资源,导致死机,只能reboot了。
另一种方法就是Non-Cooperative approach。简单来说就是使用
TIMER,每次timer到时了,就会发出interrupt(中断发生时,系统会屏蔽timer的signal),将control返回给OS。得到控制后的问题就是保存和恢复上下文(也就是上下文切换,context switch)。当需要进行上下文切换时,OS会调用switch routine,os会保存好正在运行的这个进程的process information,然后恢复将要运行的这个进程的process information。在context switch中,会发生两次save&restore,第一次是当timer中断发生时,硬件会隐式的保存正在运行的进程的user registers。第二次是当OS决定进行上下文切换时,kernel registers会被显式的由软件(也就是OS)保存在该进程的进程结构中。如下图

Scheduling
Intro
在调度中,有几个重要的衡量指标:turnaround time, response time
T
t
u
r
n
a
r
o
u
n
d
=
T
c
o
m
p
l
e
t
i
o
n
−
T
a
r
r
i
v
a
l
T_{turnaround} = T_{completion} - T_{arrival}
Tturnaround=Tcompletion−Tarrival
而Response time则是等于job第一次运行时间减去任务到达时间
T
r
e
s
p
o
n
s
e
=
T
f
i
r
s
t
r
u
n
−
T
a
r
r
i
v
a
l
T_{response} = T_{firstrun} - T_{arrival}
Tresponse=Tfirstrun−Tarrival
在已知任务时长中有几种调度算法,分别是FIFO、SJF、STCF、RR。
FIFO
FIFO的全称是First In First Out, 即先进先出,只有当一个作业完成后,才会进行下一个作业,属于非抢占型调度(non-preemptive). FIFO的turnaround time 和 response time都很大,不是一个很好的进程调度算法
SJF
SJF全称是Shortest Job First,原理很简单,即最短的作业优先运行,也是非抢占型调度,相比较FIFO,当所有作业同时到达时,turnaround time指标此时最优,但是当作业不同时到达时,最坏情况与FIFO一致。
STCF
STCF全称是Shortest Time-to-Completion First, 即最短时间完成的作业优先,它是一个抢占型调度。举个例子,当A在运行时,B到达了且所需完成时间<A完成时间,那么B将会“抢占CPU”让其自己运行。STCF的turnaround指标很低,是这种情况下的最优算法。
但是STCF的response time很差,而现代的操作系统都讲究interactive(交互),因此response time是个很重要的指标
RR
RR全称是Round Robin,与上面的算法,一次将job finish不同,该算法每次只让job运行一个time slice,当time slice到了后,该算法调度下一个job运行,time slice的取值为timer interrupt的整数倍。RR的response time表现的很好,但是turnaround time就很差了。 RR算法的time slice选取很重要,如果time slice很小,那么context switch的开销会很大,如果太大,那么response time又不会表现的太好。
但是事实上,我们并不知道job‘s length,因此SJF/STCF的实现似乎很难建立。
Multi-Level Feedback Queue
MLFQ调度算法有两个目标
- 优化turnaround time
- 使系统interactive
MLFQ有五条规则

分别是: - 如果A的优先级>B的优先级,那么A运行
- 如果A的优先级=B的优先级,那么A和B用RR算法,其quantum(也叫time slice) 根据不同的queue决定。
- 如果一个作业加入系统,它会被放置在优先级最高的队列
- 一旦一个作业用完了它在给定队列的时间储蓄(不管他放弃了多少次CPU),它的优先级都会降低
- 在经历一段时间后, 将所有的作业移到优先级最高的队列
Proportional Share
Lottery scheduling
Lottery scheduling是一种比例分配调度器,根据jobs持有多少张tickets和系统一共有多少张tickets来决定job有多少几率运行,如系统有一百张tickets,而job A有75张,那么A有75%的概率获得CPU。但是这个75%都是概率上的,并不是一定就是75%,现实往往会偏离这个数值,但是大体上是相差无几的。
Ticket Mechanisms
- ticket currency
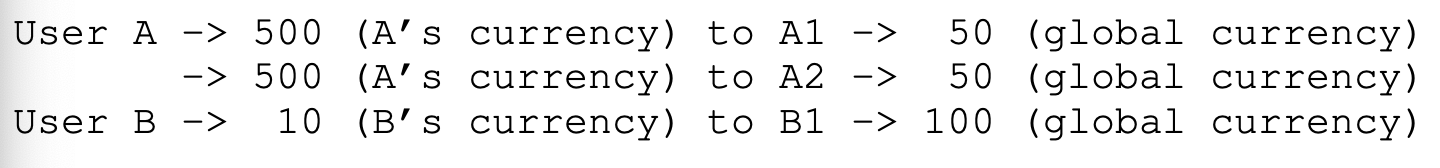
即用户A和B各获得五十张票,但是用户A的体系里,能能给A1 1000张,A21000张,但对应到全局下,A1只有25张,A2也只有25张 - ticket transfer
即一个进程可以暂时转移一些ticket给另一个进程,在C/S架构中很有用 - ticket inflation
即一个进程可以暂时提高或降低自己所持有的ticket数量(一般应用在进程间能互相相信的环境中,如果是competitive scenario,也许一个进程会抢占整个CPU)。
由于lottery scheduling的随机性,其实该调度并不fair,所以引入一个度量指标 U
U = T ( a r r i v a l A ) / T ( a r r i v a l B ) U = T_(arrivalA)/T_(arrivalB) U=T(arrivalA)/T(arrivalB)
如果存在两个任务,它们持有ticket数目相等且job length相等,那么U=1:即一个完全公平的scheduler应该无限趋近于1
由于Lottery Scheduling是大概上的概率而非绝对性的概率,于是提出了
Stride Scheduling
这个算法和Lottery算法相反,stride为ticket的反比,比如说,如果A,B,C分别有100, 50, 250张tickets,我们的stride通过我们自己选的一个大数来求得,比如说10000,那么A,B,C的stride分别为100,200,40。每次某个进程运行后,会通过一个counter(叫做pass)来增加。每次调度器需要选择一个进程来运行时,会选择各个进程pass值最小的来运行。举个例子(如下图)
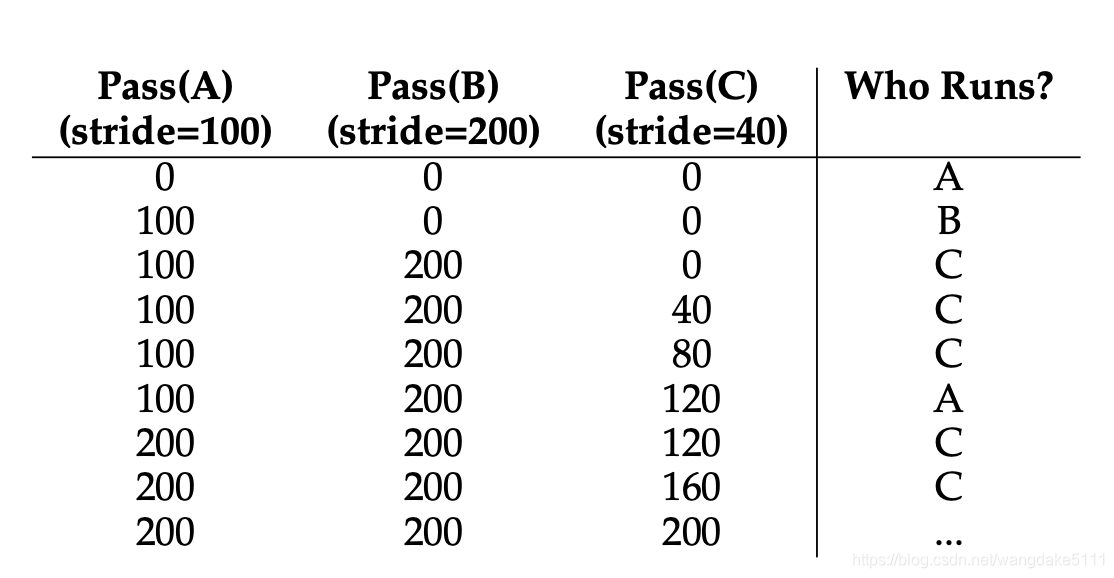
尽管stride scheduling看起来很好,但是lottery scheduling在另一方面更好:没有global state(stride scheduling的pass值是global state)举个例子,如果一个新进程进入系统,那么它的pass值应该是多少?如果为0,那么它将独占CPU很长一段时间,因为其他进程的pass值可能已经很大了。
CFS
除了上述的两种Fair-share scheduling,现在的Linux使用了另一种-CFS,即Completely Fair Scheduler,不仅实现了fair-share scheduling,还效率高可扩展。
CFS的time slice并非固定的,而是通过一个vruntime(virtual runtime)来计数。
CFS为了平衡性能和公平,引入了几个控制参数,sched_latency & min_granularity。
举个例子,如果sched_latency = 48,而这里有4个job,那么每个job的time slice为12,但如果job太多,那么time slice就会过小导致context switch过于频繁,所以min_granularity就起作用了,它保证任何一个job的time slice不小于它。通常被设置为6。
讲完最基本的CFS,现在引入Weight(权重),每个进程都有属于自己的weight,所以time_slice不将再是等分,而是
t
i
m
e
_
s
l
i
c
e
k
=
w
e
i
g
h
t
k
∑
i
→
0
n
−
1
w
e
i
g
h
t
i
⋅
s
c
h
e
d
_
l
a
t
e
n
c
y
time\_slice_{k} = \frac{weight_{k}}{\sum^{n-1}_{i \to 0}{weight_{i}}} \cdot sched\_latency
time_slicek=∑i→0n−1weightiweightk⋅sched_latency
vruntime 也将改变
v
r
u
n
t
i
m
e
i
=
v
r
u
n
t
i
m
e
i
+
w
e
i
g
h
t
0
w
e
i
g
h
t
i
⋅
r
u
n
t
i
m
e
i
vruntime_i = vruntime_i + \frac{weight_0}{weight_i} \cdot runtime_i
vruntimei=vruntimei+weightiweight0⋅runtimei
从公式可知,weight越大,同样的runtime,vruntime增加的越少。
值得一提的是,CFS存储可以运行或者正在运行的进程的数据结构为红黑树。
CFS处理IO的情况:假如说有个进程因为IO导致一段时间没有运行,而其他进程已经运行了较长一段时间,当这个进程开始运行时,它将会抢占CPU很长一段时间,导致其他进程starvation。为了避免这种情况,往往是将这个进程的vruntime设置为红黑树中值最小的那个,在这个方面上,CFS就不是那么“公平”了。
在介绍完如何虚拟化CPU后,接下来需要进行虚拟化的就是内存了
Address Space
虚拟化内存的一个很重要的抽象概念就是:地址空间。
每个进程有一个专属于自己的地址空间,这会让进程感觉自己独占了整个内存而没有人和他争抢。
所以现在的关键问题就是:如何建立这样一个抽象使得在单个物理内存上,为多个运行进程提供一个私有的,很大的地址空间。
在得出答案之前,先讲述一下虚拟内存系统重要的三个目标。
- Transparency:也就是进程不知道自己的地址空间是被虚拟化出来的
- Efficiency:也就是速度要快,占用空间尽量小
- Protection:要保证进程不能影响到其他进程,也不能影响到OS
(TIPS:我们在C语言中打印指针时,得到的就是虚拟地址)
Memory API
介绍了malloc和free,推荐在shell中使用
man malloc
man free
这里在说几个常用的错误
- 忘记分配内存
简单的说,就是你声明了一个指针,但是没有为他分配空间
比如说:char *a; print("%x",a); - 没有分配足够的内存
也叫缓冲区溢出,有时可能不会出现问题,但是这样可能会导致后面的变量覆盖前面变量的值 - 忘记初始化分配的内存
如果没初始化就调用的话,可能会出现读取到未知的数据,若想要初始化的话,可以考虑使用calloc - 忘记释放内存
如果忘记释放内存,经常会发生内存泄漏(memory leak),在一个需要长时间运行的程序中,这是个很严重的问题,因为这些内存最终没被使用,但还使用着堆中的内存,最终会导致堆过大但全是”垃圾“。 - 在用完之前释放内存
和2一样,后面的变量可能会覆盖 - 反复释放内存
多次调用free释放同一个指针,可能会发生奇怪的事情 - 错误调用free
比如int a; free(a);
会发生一些未知的事情
Mechanism: Address Translation
首先从底层硬件支持的Mechanism讲如何实现虚拟化内存。
这种Mechanism就是一种基于硬件的地址转换(hardware-based address translation),简称为 address-translation。它是LDE(见Limited Direct Execution)的补充。利用address translation,硬件每次对内存访问进行处理,也就是将指令中的虚拟地址转换为数据实际存储的物理地址。
Dynamic Relocation(Hardware-based)
这种mechanism就是为每个CPU新增两个硬件寄存器:base & bound 寄存器。这两个寄存器使得我们能够将地址空间放在物理地址的任何一个地方并且又能限制他们只能访问自己的地址空间。
TIPS:CPU中负责address translation的部分叫做MMU(Memory management unit)
需要的硬件支持:
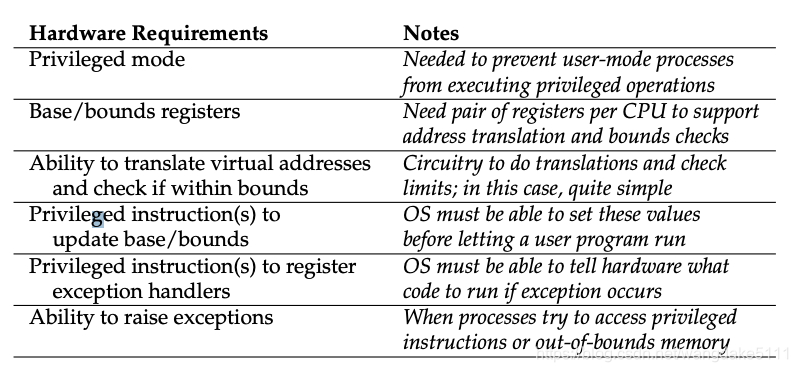
需要的操作系统支持:

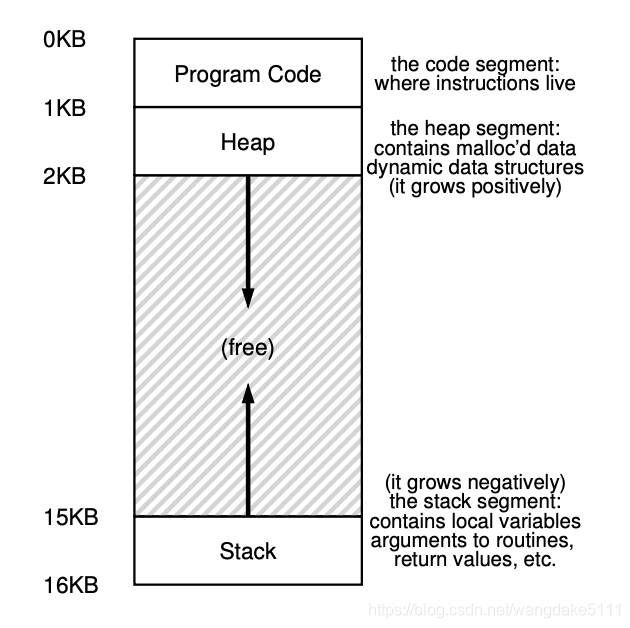
我们举个例子:假设地址空间为16KB,其中有code,heap,stack三个部分,然后我们需要将这个地址空间放到物理内存中,所以会出现下面这种情况
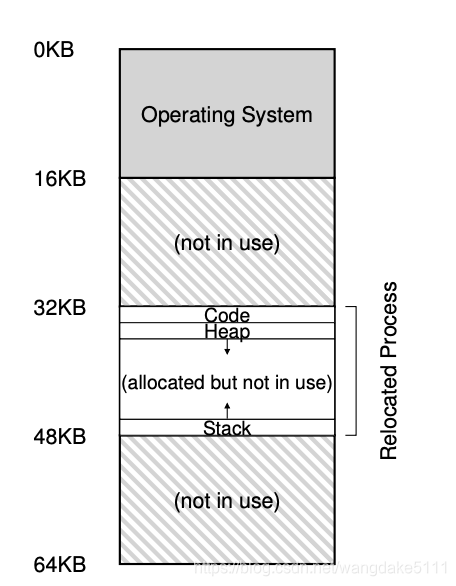
我们能看到,其中的堆和栈中间有很大一部分内存并没有被使用,我们称这种现象为internal fragmentation(内部碎片),而这显然浪费了很多内存,不满足我们对Efficiency的追求,所以引入我们一种新的分配模式:Segmentation。
Segmentation
这种想法就是将地址空间分为三段(code、heap、stack),同时不止有一堆base&bound,而是给每个segmentation一对base & bound,同时把他们三个映射到物理内存的不同地方,从而减少了内部碎片。如下图
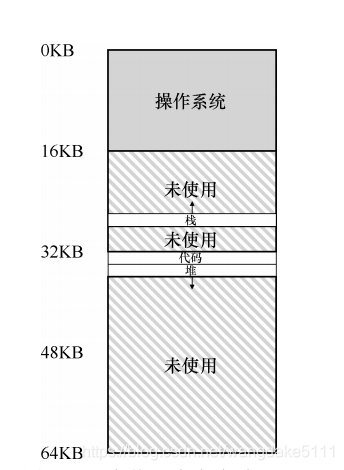
但是这样的话,我们如何知道我们引用的是哪个段呢?
一种解决方式是用虚拟地址的开头几位来标示不同的段,以14位为例,开头两位用来表示需要的是哪个段(比如00是code,01是heap,10是stack)
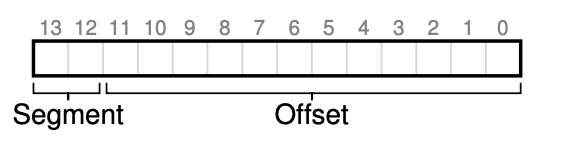
但是出现了一个新的问题:因为栈是向下增长的,所以如果通过base+offset的话,必然是得不到正确的物理地址的。所以我们向硬件寻求一点支持,在段寄存器中添加一个是否支持反向增长的1 bit。所以现在正确的计算方式是将 offset减去栈支持的最大空间,将得到的负数与base相加。
随着分段机制的改进,设计人员意识到,再添加一些硬件支持,就可以实现新的效率提升,特别是代码段,代码共享是很正常的。所以为了支持共享,添加了新的位(保护位),为每个段增加了几个位,来标示程序是否支持读写或者执行该段。比如说把代码段标示为只读,同样的代码可以被多个进程访问而不会被破坏。
尽管分段看起来很美好,但是其实分段又引入了新的问题。
第一个问题比较简单,就是必须保证在进行context switch的时候必须保证所有的段寄存器被好好的save & restore了
第二个问题就比较复杂了,也就是如何管理物理内存的空闲空间。当新的地址空间被创建时,OS就需要在物理内存中为这些段寻找空间进行分配。这里会出现的问题就是:物理内存会有只有小空间但是数量较大的内存快,但是由于段需要的空间大于这些小空间块,所以导致无法分配。比如说,一个进程有一个20Kb的段需要被分配,物理内存中有30KB,但是因为它们不是连续的,所以导致这个段无法得到分配。这个问题又叫做外部碎片(external fragmentation)
有一些办法可以减轻这个问题,第一种是重新排序整个内存空间使他们聚集在一起,但是开支太大。
另一个办法是利用空闲列表管理算法,试图保留大的分配块用于分配,这样的算法有很多:比如best-fit,worst-fit,first-fit等等。但是这些算法只能减小外部碎片但无法消除
(Free space management推荐可以看看CSAPP讲的)
Paging
一般来说,管理空间有两种办法:一种是将空间分割成不同的长度分配,比如上面讲的分段,另一种办法就是将空间分割成固定大小,从我们上面的讨论可以看出,切割成不同长度会导致空间碎片化,随着时间推移,会导致分配内存变得困难。所以我们就需要考虑将空间分割成固定的大小了。Paging就是这样一种方法,将空间分割成固定大小的单元,每个单元叫做一页,物理内存就是一个页数组,也做页帧(page frame)。
页表的一些细节:
在虚拟地址中,offset有多少位和页大小有关,VPN和有多少页有关(在多级页表中,会有多个VPN),VPN的作用是转化为PFN。
页表中的每个数据项都是一个PTE,PTE中有如(valid bit, reference bit, access bit, present bit, protection bit等等等)
在一个32位系统中一个PTE大概是这样的

看到这里,我们可能会觉得Paging,太完美了,很好地解决了外部碎片的问题,是一个很好的抽象。但是, 其实Paging还有一些问题我们还没有涉及如何解决
- 页表太大了,比如说32位的操作系统,如果一页4KB,那么就需要20位VPN,就需要
2
20
2^{20}
220
个PTE,假设每个PTE需要4Byte,那就是4MB,而且每个进程都有一个自己的页表,假设最少一百个进程在运行,那么最少有400MB内存全部被页表占用,这是一个很大的开支,如果是64位系统,那这个开销将更大,所以一般的解决方法是多级页表,在之后我们再说 - 速度太慢了,使用Paging,我们假设完成一条mov指令,需要首先取指令,这就是一次内存访问,然后假如是mov内存中的数据,那么这首先需要访问页表,又是一次内存访问,然后得到真正的物理地址在访问,又是一次内存访问。所以一次mov需要三次内存访问,这个速度是很慢的,一种提速方式就是使用TLB。
TLB
TLB全称是 translation-lookaside buffer, 其基本概念就是类似于缓存,但是是一种全相联缓存,即任意一个地址的数据能放在TLB中的任意一个位置,其他类型缓存可以看CSAPP了解一下。加入了TLB后,address translation发生了一些变化,首先地址翻译会在TLB中寻找是否存在直接能够得到的翻译,如果有,那就不需要访问页表,否则重复没有TLB时的address translation(事实上,还需要考虑页面是否被page out,是否可以访问等因素,但这里先不考虑)。有了TLB后,访问数组或一些相连的数据结构速度会得到提升,不仅如此,基本所有程序速度都会有所提升,这归功于时间局部性和空间局部性,即程序总是有访问连续数据的倾向和重复访问同一个数据的倾向。
若TLB没有hit的时候,一般硬件系统会跑出一个异常,暂停指令流,变为kernel mode,然后跳转至trap handler,但特殊的是,一般的trap handler返回后是跳转到下一条指令,而此时是重新执行之前那条命令。
多级页表
将页表做小有多种策略,我主要讲一下多级页表,多级页表的核心概念是:一个进程真正能使用到的address translation其实小于整个地址空间的,所以有很多虚拟地址其实不需要分配物理空间给它,即不需要生成某些虚拟地址的PTE,所以多级页表就是,举两级页表为例,假设地址空间为16KB,每个Page为64Byte,每个PTE为4Byte。所以虚拟地址为14位,其中6位offset,一个Page能容纳16个PTE,一个地址空间最多256个PTE,也就是16页。因此,PDE(页目录)为4位,PDIndex(页表索引)也为4位。
虽然上述的方法已经很大程度减小了页表大小,但我们还应该考虑到假如电脑在处于高负荷状态下,内存依然存在不够用的情况,所以就需要介绍一种新机制:Swap
SWAP
为什么需要Swap?首先我们需要知道,我们前面讲的都是地址空间很小,完全可以放入物理内存中,但假设我们的地址空间很大时,物理内存放不下时,我们应该怎么办呢?
找硬盘
Mechanism
首先我们需要在硬盘上开辟一部分空间用于物理页的page in & page out。这样的空间就叫做swap space。每当物理内存到达某个临界时,我们会将一些物理页page out。因为新加入了swap这个机制,address translation发生了一些变化,如我们上面所说,硬件首先查看TLB是否hit,若hit直接转换,但由于加入了swap,我们需要more mechanism,也就是present bit,若present bit位1,则表示该页在物理内存中,若位0,则不在物理内存而是在disk上。访问不再物理内存中的页,会发生page fault。
若发生了page fault,也就是页被swap到disk上了,那就需要将该页swap回到物理内存上,你觉得disk address会在哪里呢?一般是在PTE的PFN上。当将页swap回来后,OS会更新页表,将此页标记present为1,更新PFN,并重新执行指令。当内存满了,我们还需要考虑的是page out哪个页面,这就是policy的工作了。
Policy
就是常见的几个算法
FIFO,LRU,RANDOM还有一个CLOCK,就不细讲了。
HOMEWORK
我自己写的课后作业,可以供参阅。
资料
[1]: http://pages.cs.wisc.edu/~remzi/OSTEP/

















 2966
2966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









