




 本文详细介绍基于VM虚拟机的Hadoop集群安装过程,包括环境准备、SSH免密登录设置、hosts配置、Hadoop安装与配置、集群启动验证及Java操作HDFS示例。
本文详细介绍基于VM虚拟机的Hadoop集群安装过程,包括环境准备、SSH免密登录设置、hosts配置、Hadoop安装与配置、集群启动验证及Java操作HDFS示例。
前面写过一篇基于Dockerfile的Hadoop集群安装,但是在安装过程中遇到了很多问题(如:权限,端口与宿主机间访问等),本篇主要基于VM虚拟机实现Hadoop集群安装。
1.相关环境
| 软件 | 版本 |
|---|---|
| CentOS | CentOS Linux release 7.5 |
| Jdk | jdk-8u201-linux-x64.tar.gz |
| Hadoop | hadoop-3.0.0.tar.gz |
2.Hadoop集群规划
| IP | 节点 |
|---|---|
| 10.168.14.49 | hadoop-master |
| 10.168.14.50 | hadoop-slave1 |
| 10.168.14.51 | hadoop-slave2 |
3.设置hadoop ssh免密登录
安装hadoop前我们先配置好ssh免密登录
1).在hadoop-master节点生成秘钥
# 1. 生成秘钥
$ ssh-keygen -t rsa
# 2. 复制秘钥
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 3. 修改authorized_keys文件的权限
$ chmod 600 ~/.ssh/authorized_keys
# 4. 将authorized_keys文件复制到slave节点
$ scp -P 42014 ~/.ssh/authorized_keys uaren@hadoop-slave1:~/
2).打开hadoop-slave1及hadoop-slave2,在终端生成秘钥
# 1. 生成秘钥
$ ssh-keygen -t rsa
# 2. 将authorized_keys文件移动到.ssh目录
$ mv authorized_keys ~/.ssh/
4.配置hosts
10.168.14.49 hadoop-master
10.168.14.50 hadoop-slave1
10.168.14.51 hadoop-slave2
5.hadoop-master节点安装
首先需安装好jdk环境,然后进行hadoop安装及相关配置。
1). 解压hadoop-3.0.0.tar.gz,并配置环境变量
# 1. 解压hadoop-3.0.0.tar.gz
$ tar -zxvf hadoop-3.0.0.tar.gz
# 2. 配置环境变量
$ sudo vi /etc/profile
export HADOOP_HOME=/usr/local/nlp/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 3.使环境变量生效. /etc/profile;执行如下命令
$ hadoop version
# 4.出现如下信息说明配置成功
Hadoop 3.0.0
Source code repository https://git-wip-us.apache.org/repos/asf/hadoop.git -r c25427ceca461ee979d30edd7a4b0f50718e6533
Compiled by andrew on 2017-12-08T19:16Z
Compiled with protoc 2.5.0
From source with checksum 397832cb5529187dc8cd74ad54ff22
This command was run using /usr/local/nlp/hadoop-3.0.0/share/hadoop/common/hadoop-common-3.0.0.jar
2).修改hadoop相关配置
| 配置文件 |
|---|
| hadoop-env.sh |
| core-site.xml |
| hdfs-site.xml |
| yarn-site.xml |
| mapred-site.xml |
| workers |
(a). vi hadoop-env.sh
export JAVA_HOME=/usr/local/nlp/java/jdk1.8.0_201
<!--修改ssh默认端口-->
export HADOOP_SSH_OPTS="-p 42214"
(b). vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:8100/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/nlp/hadoop-3.0.0/tmp</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
| name | value | description |
|---|---|---|
| fs.defaultFS | hdfs://hadoop-master:8100/ | namenode RPC交互端口 |
| hadoop.tmp.dir | /usr/local/nlp/hadoop-3.0.0/tmp | 指定使用hadoop时产生文件的存放目录 |
| dfs.permissions | false | dfs权限是否打开,一般设置false |
| fs.trash.interval | 1440 | HDFS垃圾箱设置,可以恢复误删除,分钟数,0为禁用,添加该项无需重启hadoop |
©. vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:8101</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:8201</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:8301</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:8401</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
| name | value | description |
|---|---|---|
| dfs.replication | 1 | hdfs数据块的复制份数,默认3,理论上份数越多跑数速度越快,但是需要的存储空间也更多 |
| dfs.http.address | 0.0.0.0:8101 | NameNode web管理端口 |
| dfs.datanode.address | 0.0.0.0:8201 | datanode控制端口 |
| dfs.datanode.ipc.address | 0.0.0.0:8301 | datanode的RPC服务器地址和端口 |
| dfs.datanode.http.address | 0.0.0.0:8401 | datanode的HTTP服务器和端口 |
| dfs.webhdfs.enabled | true | 使用namenode的IP和端口进行所有的webhdfs操作 |
| dfs.permissions | false | dfs权限是否打开,一般设置false |
(d). vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8108</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:8142</value>
</property>
</configuration>
| name | value | description |
|---|---|---|
| yarn.resourcemanager.hostname | hadoop-master | 主机名称 |
| yarn.nodemanager.aux-services | mapreduce_shuffle | NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序 |
| yarn.log-aggregation-enable | true | 是否启用日志聚合 |
| yarn.resourcemanager.webapp.address | 0.0.0.0:8108 | ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。 |
(e). vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>hadoop-master:8104</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:8105</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:8106</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://hadoop-master:8107</value>
</property>
</configuration>
(f).vi workers
hadoop-slave1
hadoop-slave2
注意很多版本的安装都是编辑slaves文件,这个需要注意版本的区别hadoop3.x编辑的是workers文件。
3).将hadoop-master节点配置好的信息复制到其他两台虚拟机上
scp -P 42014 -r /usr/local/nlp/hadoop-3.0.0/* uaren@10.168.14.50:/usr/local/nlp/hadoop-3.0.0/
scp -P 42014 -r /usr/local/nlp/hadoop-3.0.0/* uaren@10.168.14.51:/usr/local/nlp/hadoop-3.0.0/
4). 格式化Namenode
注意只要格式化hadoop-master即可。
$ cd /usr/local/nlp/hadoop-3.0.0/
$ bin/hdfs namenode -format
5).启动hadoop
进入集群主节点启动hadoop
$ sbin/start-all.sh
6).查看hadoop集群启动情况,正常情况应该会显示为如下:
hadoop-master
[uaren@hadoop-master hadoop-3.0.0]$ jps
26355 Jps
24377 NameNode
24828 ResourceManager
24605 SecondaryNameNode
hadoop-slave1
[uaren@hadoop-slave1 hadoop-3.0.0]$ jps
9730 Jps
9447 NodeManager
9327 DataNode
hadoop-slave2
[uaren@hadoop-slave2 hadoop-3.0.0]$ jps
4205 Jps
3790 DataNode
3918 NodeManager
7).浏览器访问hadoop
http://10.168.14.49:8101
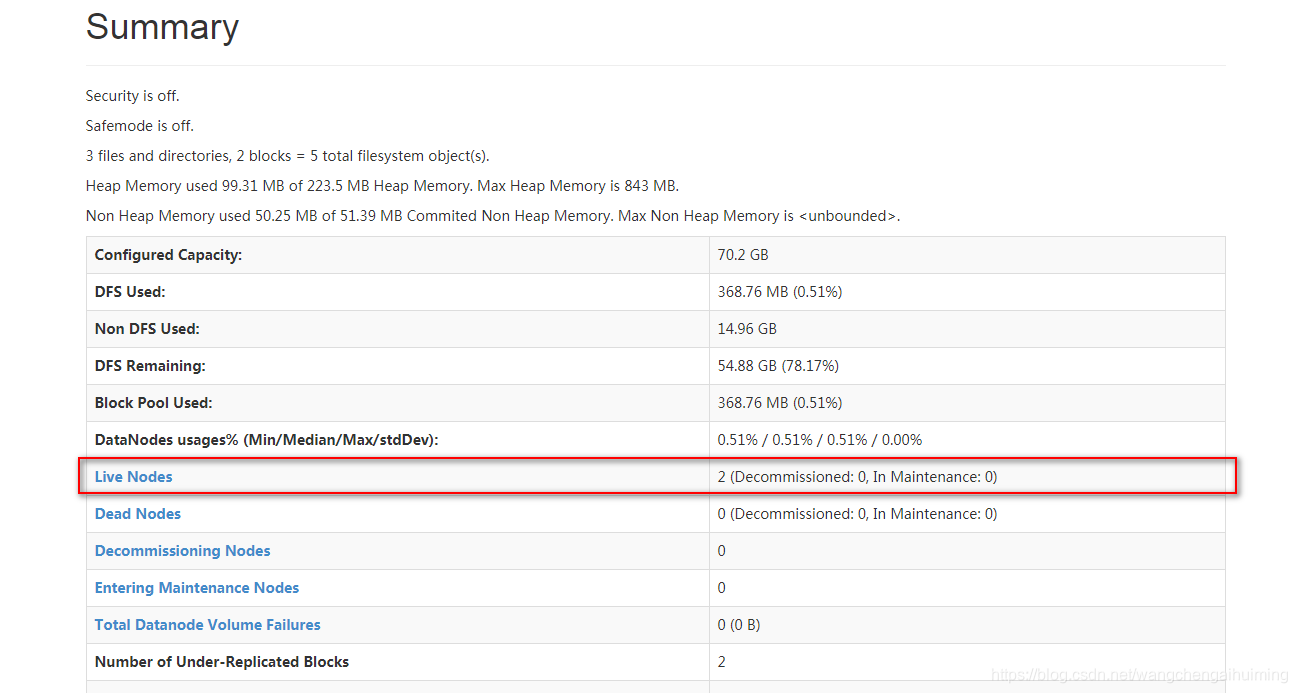 6.java操作hdfs
6.java操作hdfs
我们新建一个maven项目,pom文件导入如下包
注意修改windows环境hosts新加:
10.168.14.49 hadoop-master
10.168.14.50 hadoop-slave1
10.168.14.51 hadoop-slave2
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.0.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-maven-plugins</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
新建测试类
public class HdfsTest {
FileSystem fs = null;
@Before
public void init() throws Exception {
Configuration conf = new Configuration();
conf.set("dfs.client.use.datanode.hostname", "true");
fs = FileSystem.get(new URI("hdfs://hadoop-master:8100"), conf, "root");
}
/**
* 新建文件夹
* @throws Exception
* 作者:will
* 日期:Mar 19, 20192:36:59 PM
*/
@Test
public void testMkdir() throws Exception {
fs.mkdirs(new Path("/yrz"));
fs.close();
}
/**
* 上传文件
* @throws Exception
* 作者:will
* 日期:Mar 15, 20194:31:07 PM
*/
@Test
public void testUpload() throws Exception {
fs.copyFromLocalFile(new Path("c:/CrackCaptcha.log"), new Path("/yrz"));
fs.close();
}
/**
* 下载文件
* @throws Exception
* 作者:will
* 日期:Mar 15, 20194:31:07 PM
*/
@Test
public void testDownload() throws Exception {
fs.copyToLocalFile(false, new Path("/yrz/CrackCaptcha.log"), new Path("E:/CrackCaptcha.log"), true);
fs.close();
System.out.println("下载成功");
}
/**
* 删除文件
* @throws Exception
* 作者:will
* 日期:Mar 15, 20194:31:07 PM
*/
@Test
public void testDelete() throws Exception {
fs.delete(new Path("/yrz/CrackCaptcha.log"), true);
fs.close();
}
}

















 2072
2072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









