







接下来就是使用DeepSeek编写程序实现实际应用,例如:利用DeepSeek编写python程序进行数据分析。
在输入提示语时可以指定代码风格和规范,例如输入指令:“请按照PEP8的风格编写一个Python脚本,用于读取一个文本中重复单词的频率。”
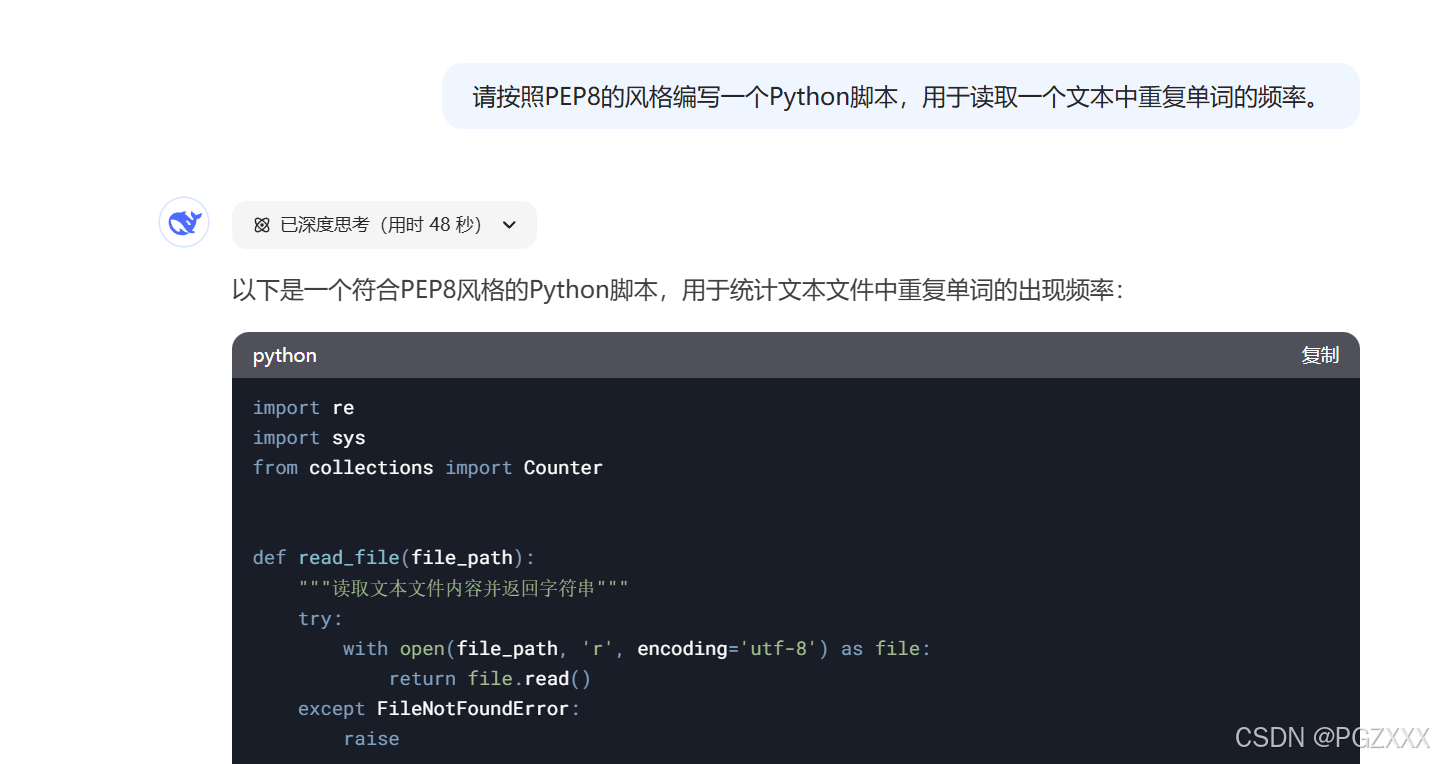
代码示例:
import re
import sys
from collections import Counter
def read_file(file_path):
"""读取文本文件内容并返回字符串"""
try:
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
except FileNotFoundError:
raise
def clean_text(text):
"""清洗文本并返回单词列表"""
return re.findall(r"\b[a-z']+(?:-[a-z']+)*\b", text.lower())
def get_word_frequencies(words):
"""统计单词频率并返回重复单词的计数字典"""
counter = Counter(words)
return {word: count for word, count in counter.items() if count > 1}
def main():
"""主函数处理程序流程"""
if len(sys.argv) != 2:
print("Usage: python word_frequency.py <input_file>")
return
file_path = sys.argv[1]
try:
text = read_file(file_path)
except FileNotFoundError:
print(f"Error: File '{file_path}' not found")
return
words = clean_text(text)
frequencies = get_word_frequencies(words)
# 按频率降序、单词字母顺序排序
sorted_words = sorted(
frequencies.items(),
key=lambda x: (-x[1], x[0])
)
# 格式化输出
max_width = max(len(word) for word in frequencies.keys()) if frequencies else 0
for word, count in sorted_words:
print(f"{word:{max_width}} : {count:>4}")
if __name__ == "__main__":
main()
主要特性:
-
PEP8 合规性:
-
使用4空格缩进
-
行长度控制在79字符以内
-
函数/变量命名使用snake_case
-
模块导入分组和顺序规范
-
文档字符串规范
-
-
功能亮点:
-
支持处理带连字符的复合词(如:state-of-the-art)
-
自动对齐输出格式
-
智能文本清洗(保留缩略语中的撇号)
-
多级排序(先按频率降序,再按字母顺序)
-
-
正则表达式说明:
r"\b[a-z']+(?:-[a-z']+)*\b"-
匹配完整单词边界
-
支持基本单词和带连字符的复合词
-
保留缩略语中的撇号(如:don't)
-
-
使用方式:
python word_frequency.py input.txt
示例输出:
the : 28
and : 15
python : 7
code : 5
异常处理:
-
文件不存在时的友好提示
-
命令行参数验证
-
UTF-8编码读取支持
扩展性:
-
通过修改正则表达式可调整单词匹配规则
-
get_word_frequencies函数可自定义频率过滤阈值 -
输出格式可轻松调整列宽和对齐方式

















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









