



 本文深入探讨MapReduce的Combiner和Partitioner类如何优化作业性能。Combiner在Map端对输出结果进行局部聚合,减少数据传输。Partitioner则负责按Key分区,确保相同分区的键值对在同一个Reduce任务中处理。通过实例展示了如何创建Combiner优化词频统计,以及自定义Partitioner实现按区号分区用户手机号码。
本文深入探讨MapReduce的Combiner和Partitioner类如何优化作业性能。Combiner在Map端对输出结果进行局部聚合,减少数据传输。Partitioner则负责按Key分区,确保相同分区的键值对在同一个Reduce任务中处理。通过实例展示了如何创建Combiner优化词频统计,以及自定义Partitioner实现按区号分区用户手机号码。
combiner类
combiner是用来优化Mapreduce的,它可以提高Mapreduce的运行效率。在MapReduce作业运行过程中,通常每一个Map都会产生大量的本地输出,Combiner的作用就是在Map端对输出结果先做一次合并,以减少传输到Reduce端的数据量。
在上一个博客里我们使用MapReduce实现了词频统计,接下来,我们使用combiner进行下优化
1、新建一个WCCombiner类,代码直接复制WCReduce,中的代码就行,原因呢,很简单,因为combiner只有在数据大的时候其优势才能显示出来,我们这里的使用combiner就和reduce效果一致
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;public class WCConbiner extends Reducer<Text, IntWritable,Text,IntWritable> { //创建输出的v对象 IntWritable v = new IntWritable(); //用来求和 int sum = 0; @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //reduce 端接受到的类型大概是这样的 (wish,(1,1,1,1,1,1)) //对迭代器进行累加求和 for (IntWritable count : values) { sum += count.get(); } //将key value 进行写出 v.set(sum); context.write(key,v); } }
2、修改WCDriver中的代码 新增: job.setCombinerClass(WCConbiner.class);
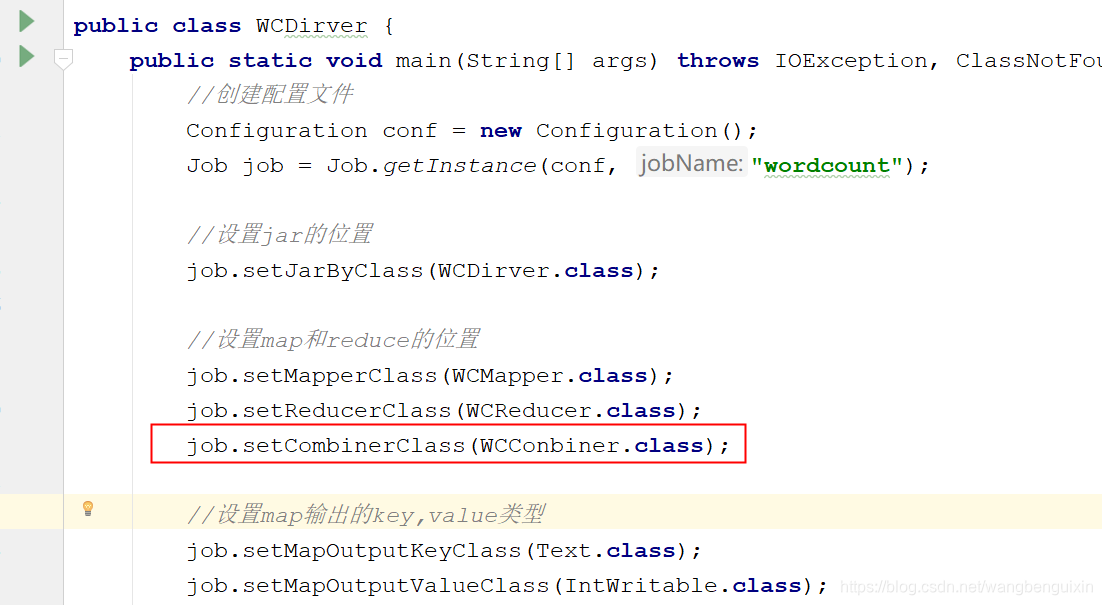
3、删除之前运行程序生成的output包,再次运行即可
Partitoner类
Paritioner的功能是在Map对key进行分区,它也是MapReduce另一个优化组件。Map端最终处理的<key,value>对需要发送到Reduce端去合并,合并的时候,相同分区的<key,value>对会被分配到同一个Reduce上,这个分配过程就是由Partitioner决定的。
在上一个博客里我们使用MapReduce将用户的手机号码和访问量进行了统计,现在,我们继续使用这个素材,将用户的手机号根据区号进行分区,以存放在不同的文件中;
1、新建一个ProvincePartitioner类,继承Partitioner 重写 getPartition方法
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner;//继承 Partitioner 实现抽象方法 public class ProvincePartitioner extends Partitioner<Text,FlowBean> { @Override //值得注意的是,这个方法是有返回值的 public int getPartition(Text key, FlowBean flowBean, int i) { //1、取出手机号前三位 String preNum = key.toString().substring(0,3); int partition = 4; //2、判断属于哪个省的,返回分区号 这里是分了五个区 if ("136".equals(preNum)){ partition = 0; }else if("137".equals(preNum)){ partition = 1; }else if ("138".equals(preNum)){ partition = 2; }else if ("139".equals(preNum)){ partition = 3; } //其他问分区的自动分到第五个区 return partition; } }
2、接下来就简单了,新建一个名为PartitionerDriver的类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class PartioneDirver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //创建配置文件 Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "flowCount"); //设置jar的位置 job.setJarByClass(FlowDriver.class); //设置map和reduce的位置 job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); //设置分区的位置 job.setPartitionerClass(ProvincePartitioner.class); //设置分区的数量 //reduce的数量最好是等于分区的数量 如果等于一 最终生成一个分区 //如果大于五,多余的分区会有空白文件 //如果小于五,则会报错 job.setNumReduceTasks(5);//之前分了五区,最好是相等 //设置map输出的key,value类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); //设置key输出的key,value类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置输入输出的路径 FileInputFormat.setInputPaths(job,new Path("file:///D:\\Idea\\Mapreduce\\input")); //FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path("file:///D:\\Idea\\Mapreduce\\output\\partitionerout")); //FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交程序运行 boolean result = job.waitForCompletion(true); System.exit(result? 0 : 1); } }
3、运行成功,显示结果
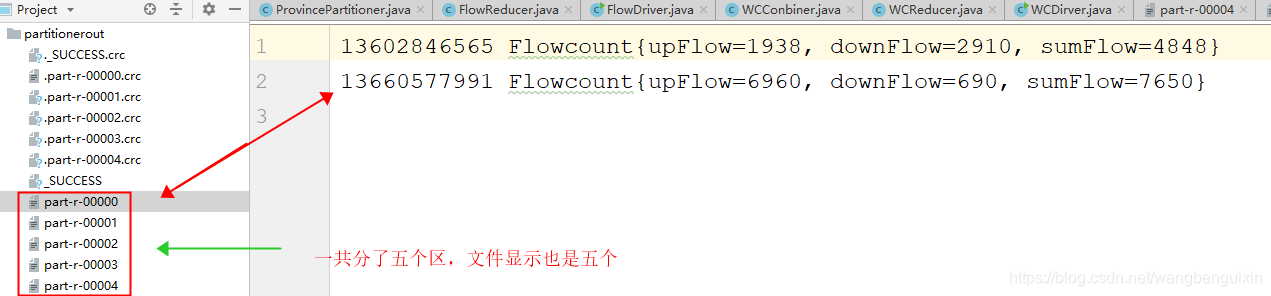
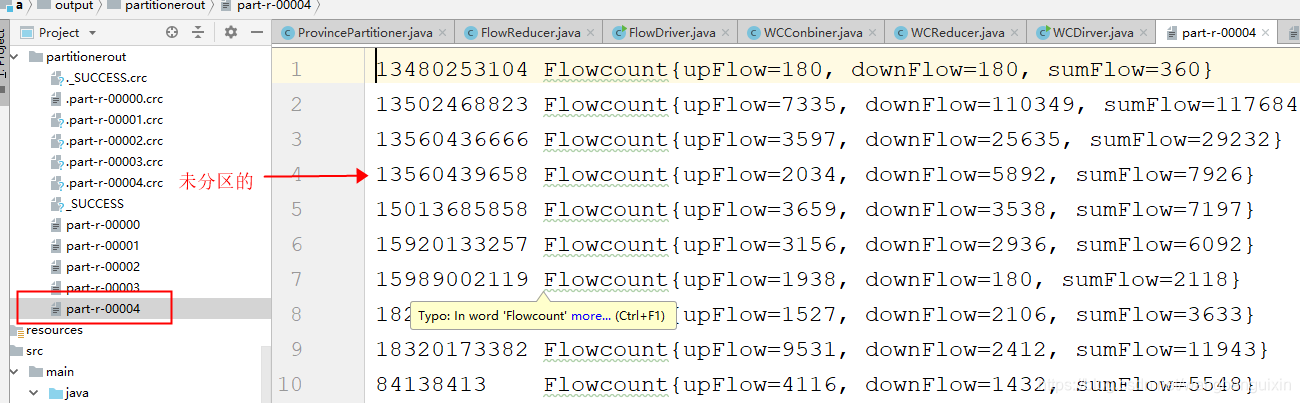

















 2076
2076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









