




 本文深入探讨Redis哨兵架构,介绍其如何通过监视主服务器和从服务器,自动完成故障转移,极大提高系统的可用性。文章详细讲解哨兵的工作流程,包括获取服务器信息、故障检测与转移、领头Sentinel选举等关键环节。
本文深入探讨Redis哨兵架构,介绍其如何通过监视主服务器和从服务器,自动完成故障转移,极大提高系统的可用性。文章详细讲解哨兵的工作流程,包括获取服务器信息、故障检测与转移、领头Sentinel选举等关键环节。
Redis 哨兵架构
1. 主从复制架构的局限
可用性有限:当Master宕机后,此时写操作都失败,直到实例重启。
为解决Master到实例重启所丢失的数据量,提出了哨兵架构。
2. 哨兵架构
哨兵架构示意图如下:
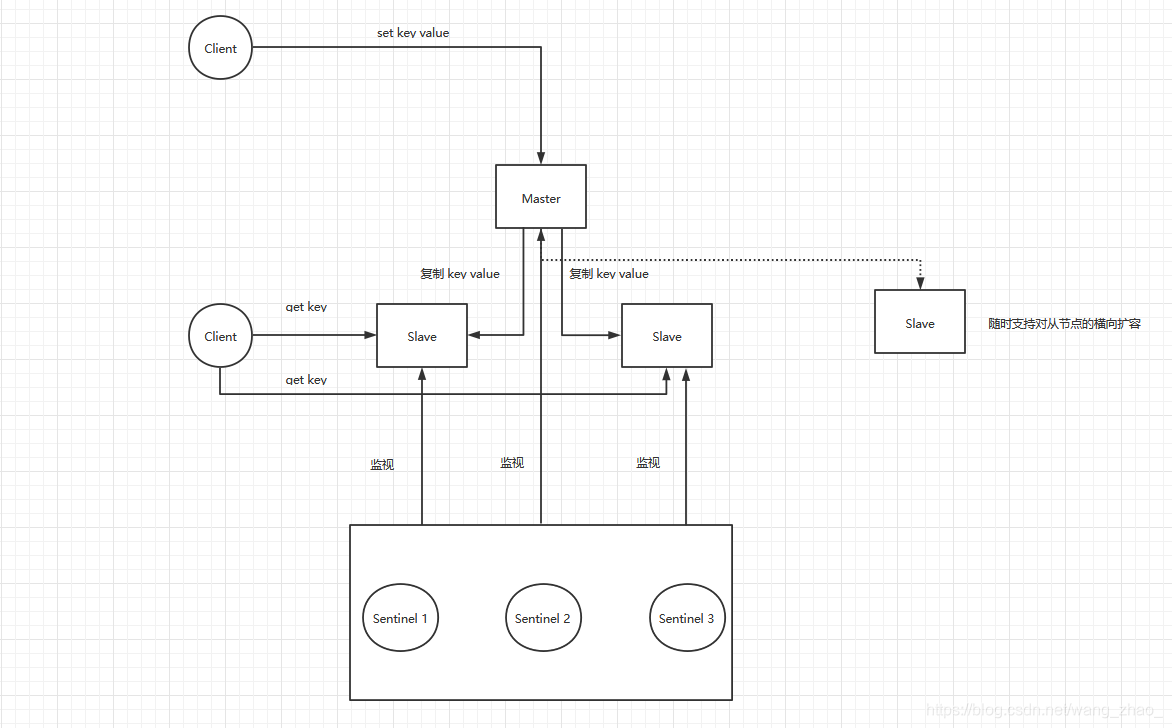
优点
可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进人下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
这样就不需要等待运维人员重启实例,而是自动的进行选举,只不过是在选举的时刻不能进行写操作,可用性极大的提高了。
3. 哨兵工作步骤
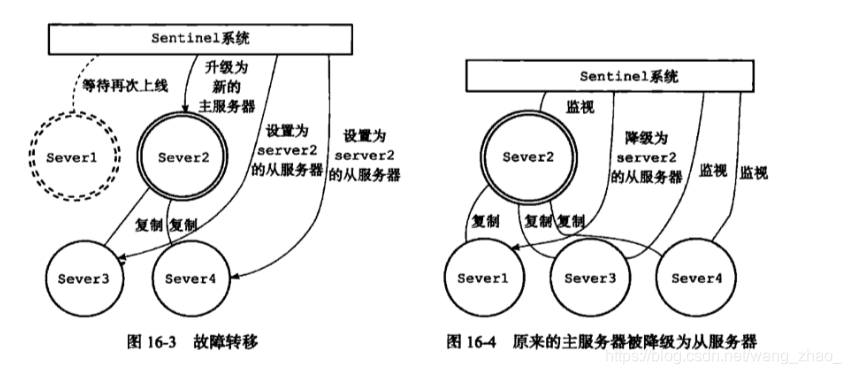
当主服务的server1的下线时长超过用户设定的下线时长上限时,Sentinel系统就会对server1执行故障转移操作:
- 首先,
Sentinel系统会挑选server1属下的其中一个从服务器,并将这个被选中的从服务器升级为新的主服务器。 - 之后,
Sentinel系统会向server1属下的所有从服务器发送新的复制指令,让它们成为新的主服务器的从服务器,当所有从服务器都开始复制新的主服务器时,故障转移操作执行完毕。 - 另外,
Sentinel还会继续监视已下线的server1,并在它重新上线时,将它设置为新的主服务器的从服务器。
4. 获取主服务器信息
Sentinel 默认以每10秒一次的频率,向被监视的主服务器发送INFO命令,通过其回复来获取主服务器的当前信息。
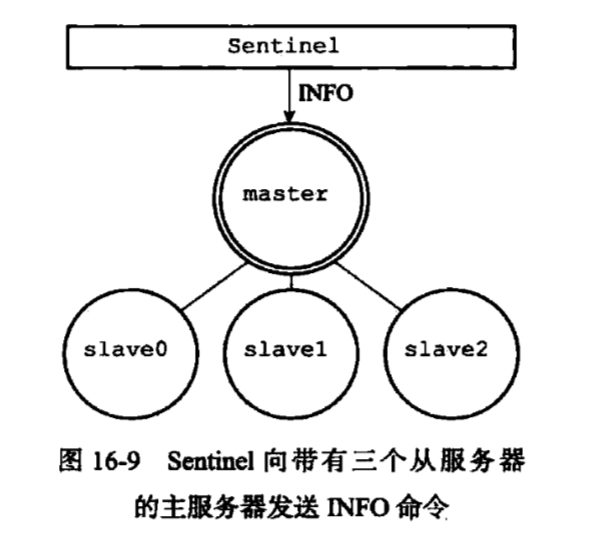
通过分析主服务器返回的INFO命令回复,Sentinel可以获取以下两方面的信息:
- 主服务器自身信息,服务器的运行
ID以及服务器的角色 - 主服务器的所有从服务器,如从服务器的
IP、端口,所以Sentinel无须用户提供从服务器地址信息就可以自动发现从服务器。
5. 获取从服务器信息
当 Sentinel 发现主服务器有新的从服务器时,Sentinel 除了为该从服务器创建相应的实例,还会创建连接向从服务器的命令连接和频道连接。
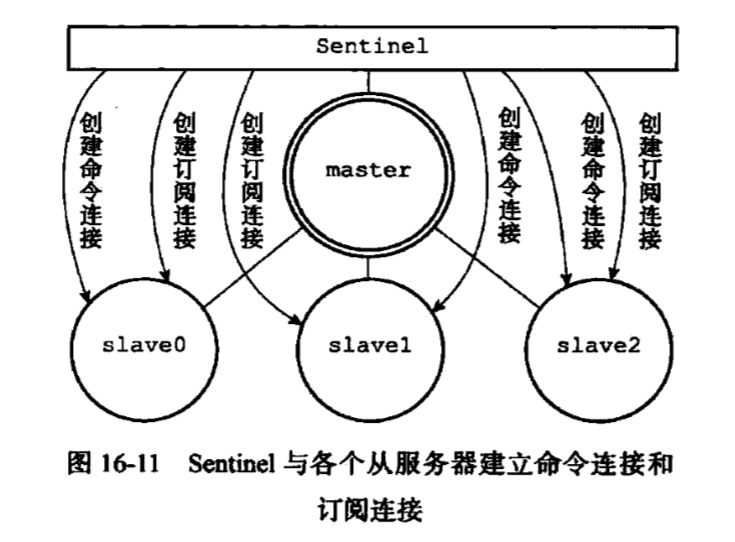
当创建命令连接后,Sentinel 默认会以每10秒一次的频率通过命令连接向从服务器发送 INFO 命令。
根据INFO命令的回复,Sentinel会提取出以下信息:
- 从服务器的运行ID
- 从服务器的角色
- 主服务器的ip、端口
- 从服务器的优先级
- 从服务器的复制偏移量
6. 向主服务器和从服务器发送信息
在默认情况下,Sentinel会以每两秒一次的频率。 通过命令连接向所有被监视的主服务器和从服务器发送以下格式的命令:
PUBLISH __sentinel:he11o "<s_ ip>,<s_ port>,<s_ runid>,<s_ epoch>,<m_ name>,<m_ip>, <m_port>, <m_ epoch> "
s_开头的参数为Sentinel本身的信息。
m_开头的参数为Master本身的信息。
7. 接受来自主服务器和从服务器的频道信息
当Sentinel 与一个主服务器或者从服务器建立起订阅连接之后,Sentinel 就会通过订阅连接,向服务器发送以下命令:
SUBSCRIBE __sentinel___ : hel1o
Sentinel对sentinel__ :hello频道的订阅会一直持续到Sentinel与服务器的连接断开为止。
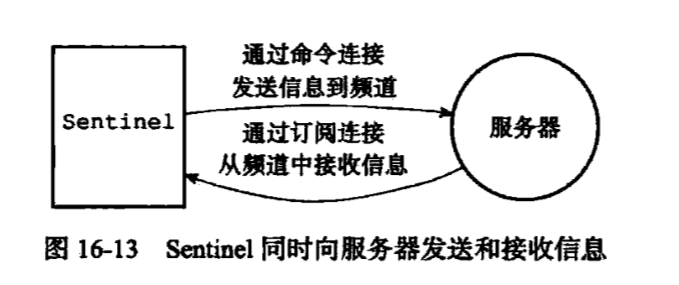
Sentinel会从频道中获取到的信息,对对应主服务器的实例结构进行更新。
7. 检测主观下线
默认情况下,Sentinel 会以每秒一次的频率向所有与他创建了命令连接的实例(包括主服务器、从服务器、其他Sentinel)发送 PING 命令,并通过实例返回的信息判断实例是否在线。
如果有一个实例在 down-after-millisecond毫秒内,连续向 Sentinel返回无效回复,那么 Sentinel 会修改这个实例所对应的实例结构,在结构的flags属性中打开 SRI_S_DOWN 标识,以此标识该实例已经进入主观下线状态。
8. 检测客观下线
当 Sentinel 将一个主服务器判断为主观下线后,为了确保该主服务器真的下线,还需要进行客观下线判断。
当 Sentinel 从其他 Sentinel 那里接收到足够数量的下线判断后,Sentinel 就会将主服务器判定为客观下线,并对服务器进行故障转移操作。
9. 选举领头 Sentinel
当一个主服务器被判断为客观下线时,监视这个下线主服务器的各个Sentinel会进行协商,选举出一个领头Sentinel, 并由领头Sentinel `对下线主服务器执行故障转移操作。
领头Sentinel选举的规则和方法:

10. 故障转移
领头 Sentinel将进行故障转移时,需执行以下3个步骤:
- 在已下线主服务器属下的所有从服务器里面,挑选出一个从服务器,并将其转换为主服务器。
- 让已下线主服务器属下的所有从服务器改为复制新的主服务器。
- 将已下线主服务器设置为新的主服务器的从服务器,当这个旧的主服务器重新上线时,它就会成为新的主服务器的从服务器。
10.1 选出新的主服务器
选举规则
领头服务器将所有从服务器保存到一个列表中,然后进行过滤。
- 删除所有处于下线或掉线的从服务器
- 删除最近 5 秒内没有回复过领头
Sentinel的INFO命令的从服务器 - 删除所有与主服务器连接断开超过
down-after-miliseconds * 10的从服务器 - 根据从服务器的优先级进行排序,选择优先级最高的
- 如果优先级相同,选择
offset最大的,保证数据尽可能一致 - 如果
offset相同,则出run ID最小的从服务器
10.2 修改从服务器的复制目标
当新的主服务器出现之后,领头 Sentinel 下一步要做的就是,让已下线主服务器属下的所有从服务器去复制新的主服务器,这一动作可以通过向从服务器发送 SLAVEOF 命令来实现。
10.3 将旧的主服务器变为从服务器
故障转移操作最后要做的是,将已下线的主服务器设置为新的主服务器的从服务器。
11. 集群脑裂
脑裂,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着。
此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master。
这个时候,集群里就会有两个·master,也就是所谓的脑裂。
这会造成客户端还没有反应过来,数据没有被写入到新的master中,从而造成数据不一致。
解决方案
min-slaves-to-write 1
min-slaves-max-lag 10
第一个参数表示连接到master的最少slave数量为 1
第二个参数表示slave连接到master的最大延迟时间为 10 秒
如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了。
该方案同样是解决异步同步数据丢失的解决方案。

















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









