




 ApacheOzone是一种分布式、可扩展和高性能的对象存储系统,可与Cloudera数据平台(CDP)一起使用,支持S3API和HadoopAPI,适用于多种垂直行业。Ozone提供了统一的存储架构,能够同时存储文件和对象,支持多协议访问,如OzoneS3API、OzoneFS等,提高了存储效率和数据访问性能。
ApacheOzone是一种分布式、可扩展和高性能的对象存储系统,可与Cloudera数据平台(CDP)一起使用,支持S3API和HadoopAPI,适用于多种垂直行业。Ozone提供了统一的存储架构,能够同时存储文件和对象,支持多协议访问,如OzoneS3API、OzoneFS等,提高了存储效率和数据访问性能。
Apache Ozone 是一种分布式、可扩展和高性能的对象存储,可与Cloudera 数据平台(CDP) 一起使用,可以扩展到数十亿个不同大小的对象。它被设计为原生的对象存储,可提供极高的规模、性能和可靠性,以使用 S3 API 或传统的 Hadoop API 处理多个分析工作负载。
今天的平台所有者、企业所有者、数据开发人员、分析师和工程师在 Cloudera 数据平台CDP上创建新的应用程序,他们必须决定在哪里以及如何存储这些数据。结构化数据(例如姓名、日期、ID 等)将存储在常规 SQL 数据库中,如 Hive 或 Impala 数据库。还有更新的 AI/ML 应用程序需要数据存储,使用 Python Boto API 等开发人员友好的范例针对非结构化数据进行了优化。
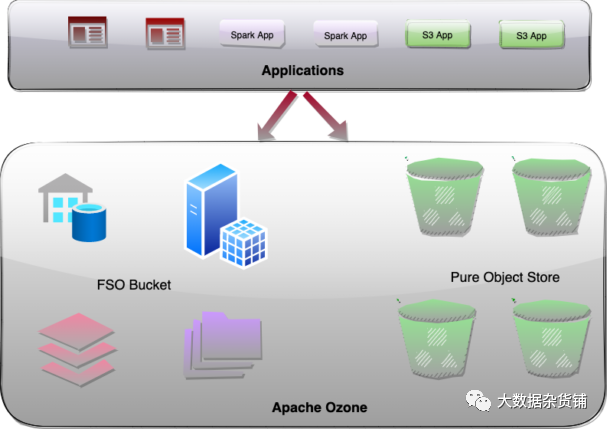
Apache Ozone 满足各种垂直行业的这两种存储用例,其中包括:
-
制造业,他们生成的数据除了提高运营效率外,还可以提供新的商机,例如预测性维护
-
零售,在零售流程的所有阶段都使用大数据——从产品开发、定价、需求预测到商店的库存优化。
-
医疗保健,大数据用于提高盈利能力、进行基因组研究、改善患者体验和挽救生命。
类似的用例存在于所有其他垂直领域,如保险、金融和电信。
在这篇博文中,我们将讨论具有 Hadoop 核心文件系统 (HCFS) 和对象存储(如 Amazon S3)功能的单个 Ozone 集群。一种统一的存储架构,可以同时存储文件和对象,并提供灵活、可扩展和高性能的系统。此外,可以通过不同的协议为各种用例访问存储在 Ozone 中的数据,从而消除数据重复的需要,从而降低风险并优化资源利用率。
工作负载的多样性
当今快速增长的数据密集型工作负载推动了分析、机器学习、人工智能和智能系统,需要一个既灵活又高效的存储
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









