






01 Regression (Piecewise Linear Curves)
一、Model Bias
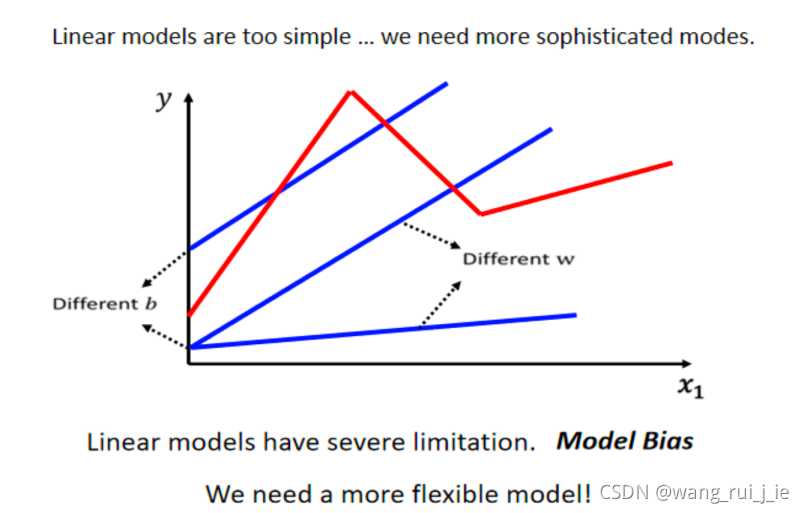
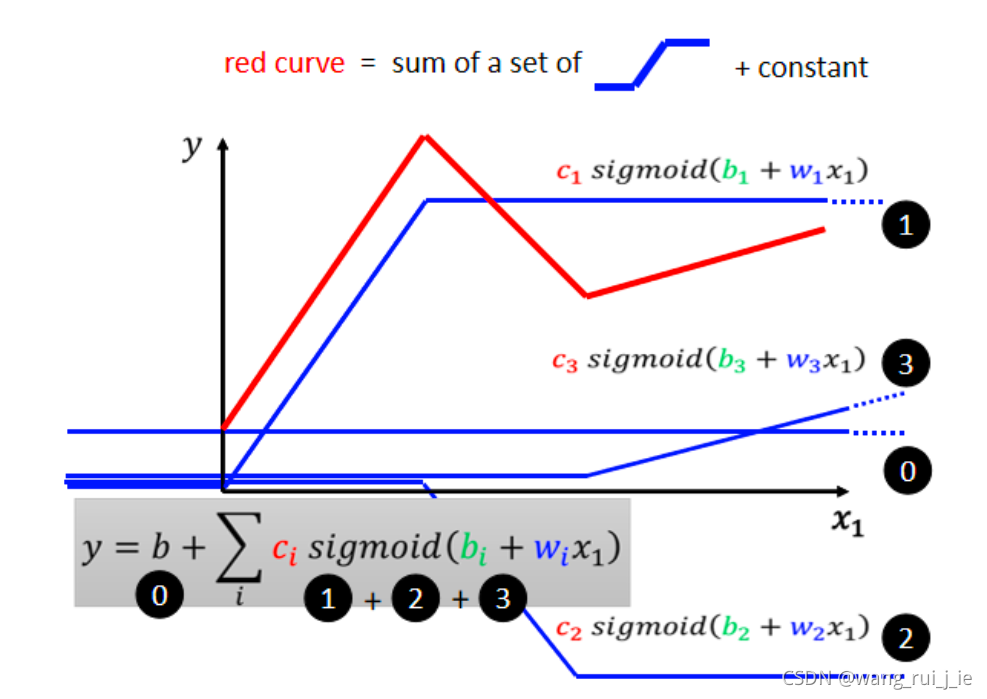
那么如何解决这个问题?
1.Sigmoid(Sigmoid只是一种方法)
二、 define loss function
1.MSEloss
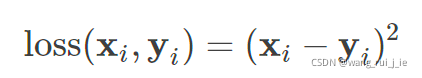
2.Cross-entropy
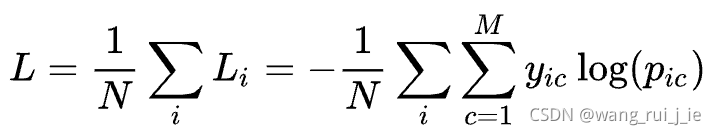
三、Optimization
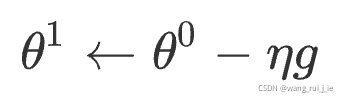
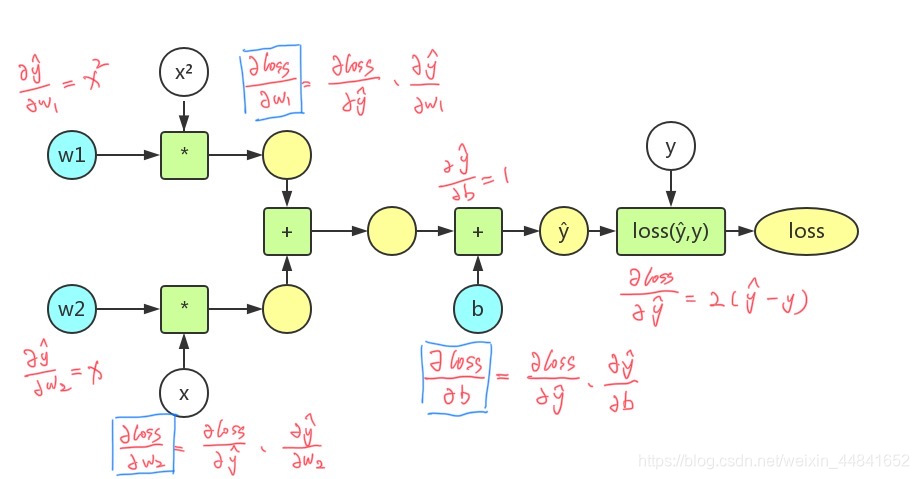
1.back propagation
以下是二次模型y=w1x²+w2x+b,损失函数loss=(ŷ-y)²的计算图
# 高纬线性回归从零开始实现
import torch
import torch.nn as nn
import numpy as np
import sys
n_train,n_test,num_inputs = 20,100,200
true_w,true_b = torch.ones(num_inputs,1)* 0.01,0.05
#总样本数设计30个
features = torch.randn(n_train+n_test,num_inputs)
labels = torch.matmul(features,true_w)+true_b
labels += torch.tensor(np.random.normal(0,0.01,size = labels.size()),dtype=torch.float32)
train_features = features[:n_train,:]
test_features = features[n_train:,:]
train_labels = labels[:n_train]
test_labels = labels[n_train:]
# 初始化模型参数,附上梯度
def init_params():
w = torch.randn((num_inputs,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)
return [w,b]
# 定义L2范数惩罚项
def l2_penalty(w):
return (w**2).sum() / 2
def linreg(X , w , b):
return torch.mm(X , w) + b
def squared_loss(y_hat,y):
# 注意这里返回的是向量,另外, pytorch⾥的MSELoss并没有除以2
return (y_hat - y.view(y_hat.size())) ** 2 / 2
def sgd(params , lr, batch_size): # 随机梯度下降更新参数
for param in params:
param.data -= lr * param.grad / batch_size
batch_size,epoch,lr = 1,100,0.003
net,loss = linreg,squared_loss
dataset = torch.utils.data.TensorDataset(train_features,train_labels)
train_iter = torch.utils.data.DataLoader(dataset,batch_size,shuffle=True)
def Train(lambd):
w,b = init_params()
train_ls,test_ls = [],[]
for i in range(epoch):
for X,y in train_iter:
l = loss(net(X,w,b),y) + lambd * l2_penalty(w)
l = l.sum()
l.backward()
sgd([w,b],lr,batch_size)
w.grad.data.zero_()
b.grad.data.zero_()
#一次epoch后,看看更新了参数的效果,跑一下整个样本:
train_ls.append(loss(net(train_features,w,b),train_labels).mean().item())
test_ls.append(loss(net(test_features,w,b),test_labels).mean().item())
print('epoch=',i+1,'train_ls=',train_ls[i],'test_ls=',test_ls[i])
Train(3)# 高纬线性回归简洁实现
import torch
import torch.nn as nn
import numpy as np
n_train,n_test,num_inputs = 20,100,200
true_w,true_b = torch.ones(num_inputs,1)* 0.01,0.05
#总样本数设计30个
features = torch.randn(n_train+n_test,num_inputs)
labels = torch.matmul(features,true_w)+true_b
labels += torch.tensor(np.random.normal(0,0.01,size = labels.size()),dtype=torch.float32)
train_features = features[:n_train,:]
test_features = features[n_train:,:]
train_labels = labels[:n_train]
test_labels = labels[n_train:]
batch_size,epoch,lr = 1,100,0.001
dataset = torch.utils.data.TensorDataset(train_features,train_labels)
train_iter = torch.utils.data.DataLoader(dataset,batch_size,shuffle=True)
net = nn.Linear(num_inputs,1)
def weight_decay_experiment(lamda):
optimizer = torch.optim.SGD(net.parameters(),lr=lr,weight_decay = lamda)
criterion = torch.nn.MSELoss()
train_ls,test_ls = [],[]
for i in range(epoch):
for X,y in train_iter:
outputs = net(X)
l = criterion(outputs,y)
l.backward()
optimizer.step()
optimizer.zero_grad()
train_ls.append(criterion(net(train_features),train_labels).mean().item())
test_ls.append(criterion(net(test_features),test_labels).mean().item())
print('epoch=', i + 1, 'train_ls=', train_ls[i], 'test_ls=', test_ls[i])
weight_decay_experiment(3)
02 Overfitting
一、Train_loss
1.Model bias
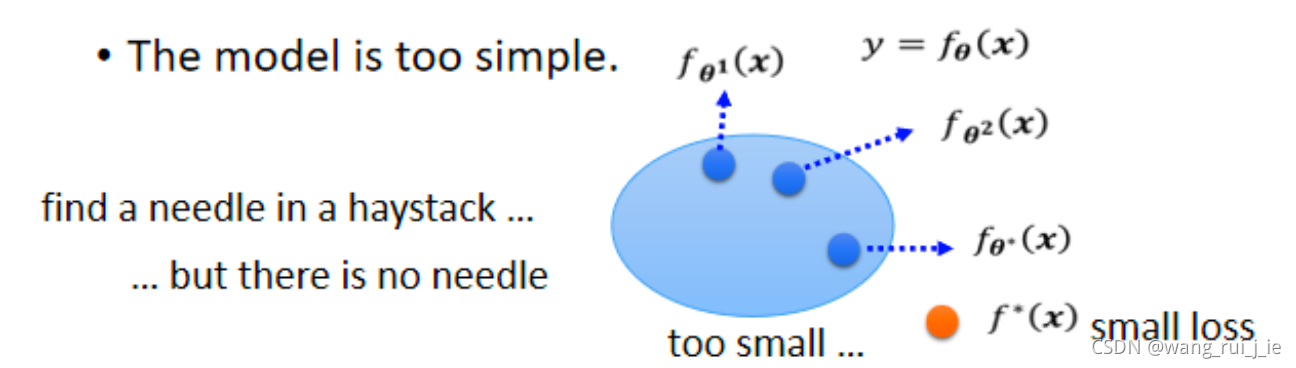 二、Optimization Issue
二、Optimization Issue
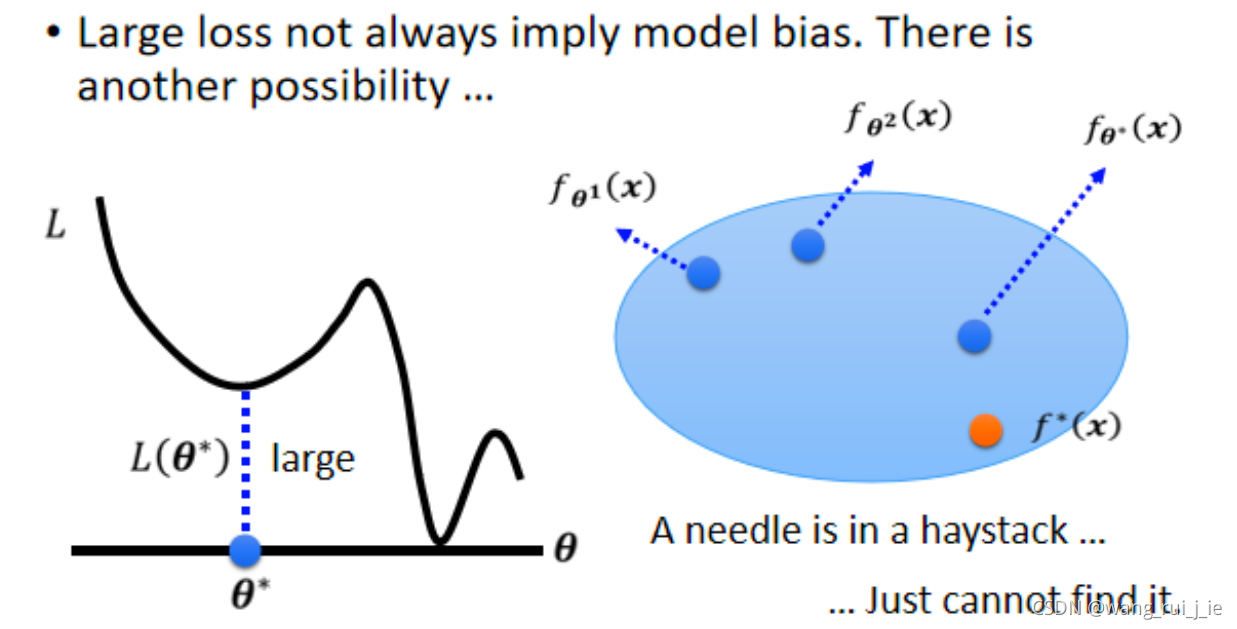
training data的loss不够低的时候,到底是model bias,还是optimization的问题呢?

三、Overfitting
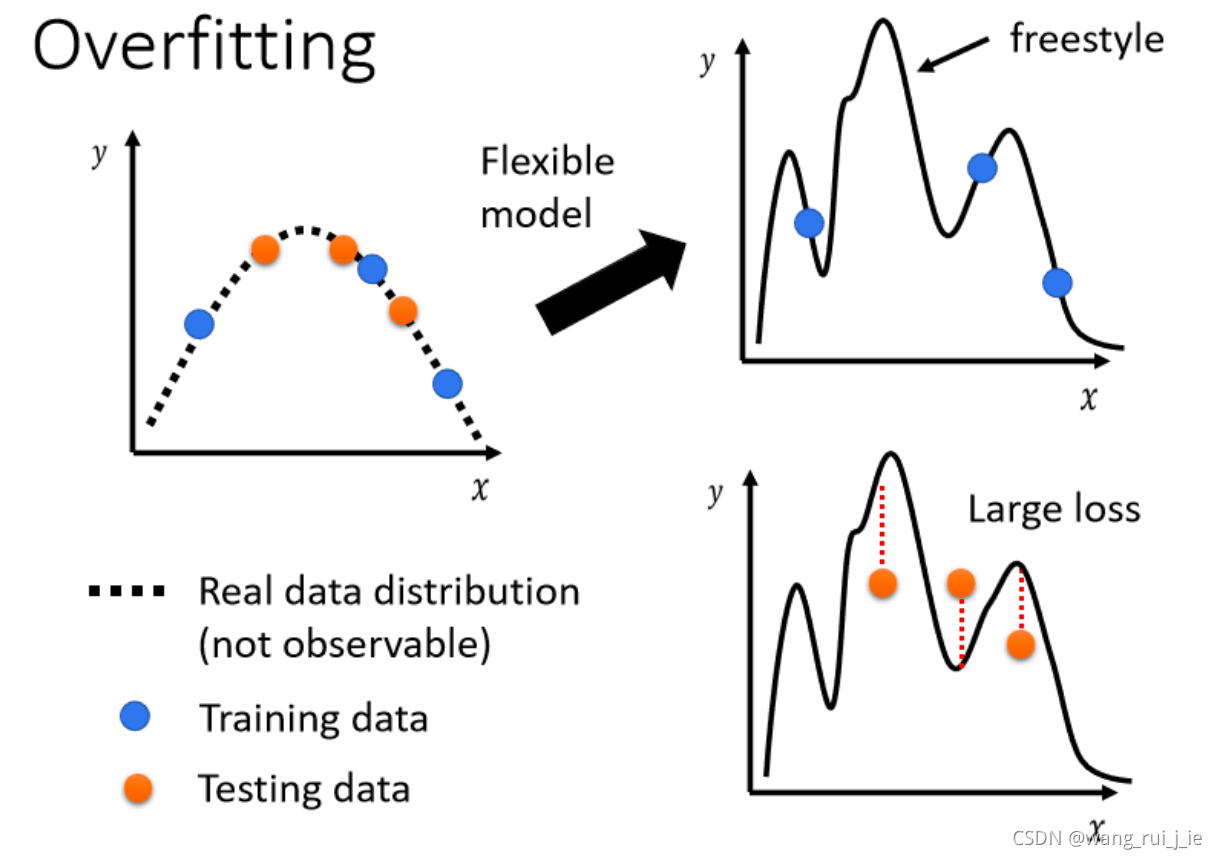
如何解决Overfitting?
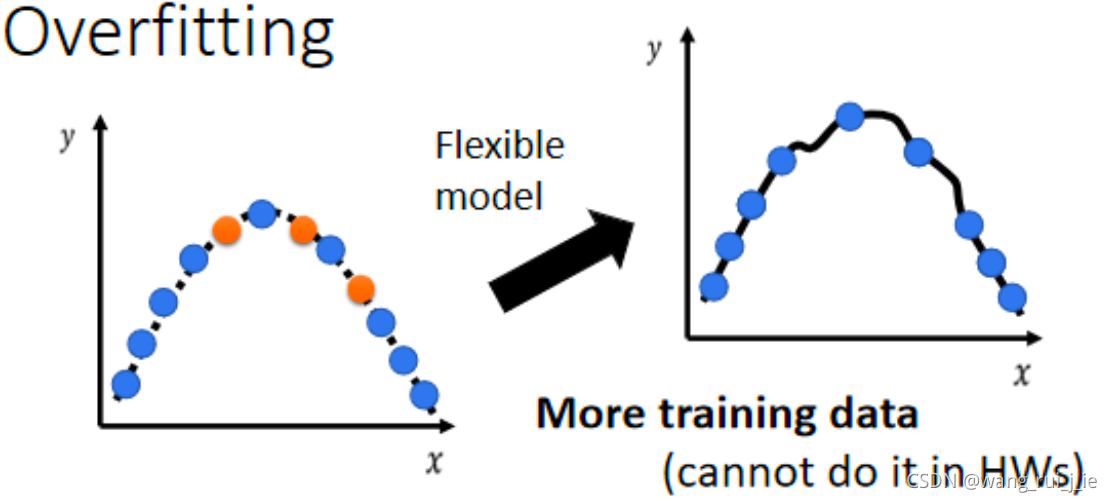
1、增加训练集
2、data augmentation

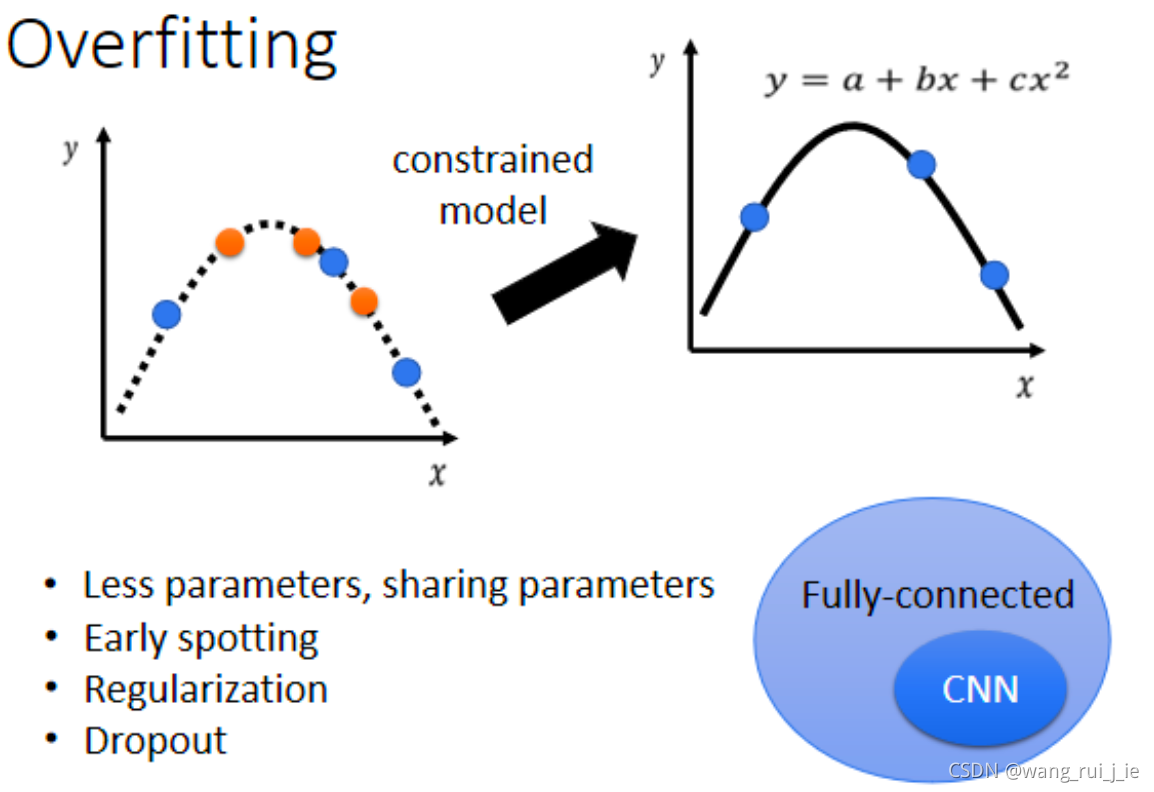
3、模型限制(降低复杂度)
# 丢弃法从零实现
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
def drop_out(X,drop_prob):
X = X.float()
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
if keep_prob == 0:
return torch.zeros_like(X)
mask = (torch.rand(X.shape) < keep_prob).float()
return mask * X / keep_prob
X = torch.arange(16,dtype=torch.float32).reshape(2,8)
print(X)
print(drop_out(X,0.))
print(drop_out(X,0.5))
print(drop_out(X,1.))
# 样本的特征数为784
num_inputs,num_outputs,num_hiddens1,num_hideens2 = 784,10,256,256
W1 = torch.tensor(np.random.normal(0,0.01,size=(num_inputs,num_hiddens1)),dtype=torch.float32,requires_grad=True)
b1 = torch.zeros(num_hiddens1,requires_grad=True)
W2 = torch.tensor(np.random.normal(0,0.01,size=(num_hiddens1,num_hideens2)),dtype=torch.float32,requires_grad=True)
b2 = torch.zeros(num_hideens2,requires_grad=True)
W3 = torch.tensor(np.random.normal(0,0.01,size=(num_hideens2,num_outputs)),dtype=torch.float32,requires_grad=True)
b3 = torch.zeros(num_outputs,requires_grad=True)
params = [W1,b1,W2,b2,W3,b3]
drop_prob1,drop_prob2 = 0.3,0.5
def net(X,is_trainning):
X = X.view(-1,num_inputs)
H1 = (torch.matmul(X,W1)+b1).relu()
if is_trainning:
H1 = drop_out(H1,drop_prob1)
H2 = (torch.matmul(H1,W2)+b2).relu()
if is_trainning:
H2 = drop_out(H2,drop_prob2)
return torch.matmul(H2,W3)+b3
def evaluate_accuracy(data_iter,net):
acc_sum , n = 0.0,0
for X,y in data_iter:
if isinstance(net,torch.nn.Module):
net.eval()#评估模型,这会关闭dropout
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
net.train()
else: # ⾃定义的模型
if ('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数,将is_training设置成False
acc_sum += (net(X, False).argmax(dim=1)== y).float().sum().item()
else:
acc_sum += (net(X,False).argmax(dim=1) ==y).float().sum().item()
n += y.shape[0]
return acc_sum / n
epoch,lr,batch_size = 5,100.0,256
loss = torch.nn.MSELoss()
loss = torch.nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, epoch,
batch_size, params, lr)# 丢弃法简洁实现
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
num_inputs,num_outputs,num_hiddens1,num_hiddens2 = 784,10,256,256
drop_prob1,drop_prob2 = 0.3,0.5
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(drop_prob1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(drop_prob2),
nn.Linear(num_hiddens2, 10)
)
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)
num_epochs, lr, batch_size = 5, 100.0, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs,batch_size, None, None, optimizer)四、model selection
- Cross Validation
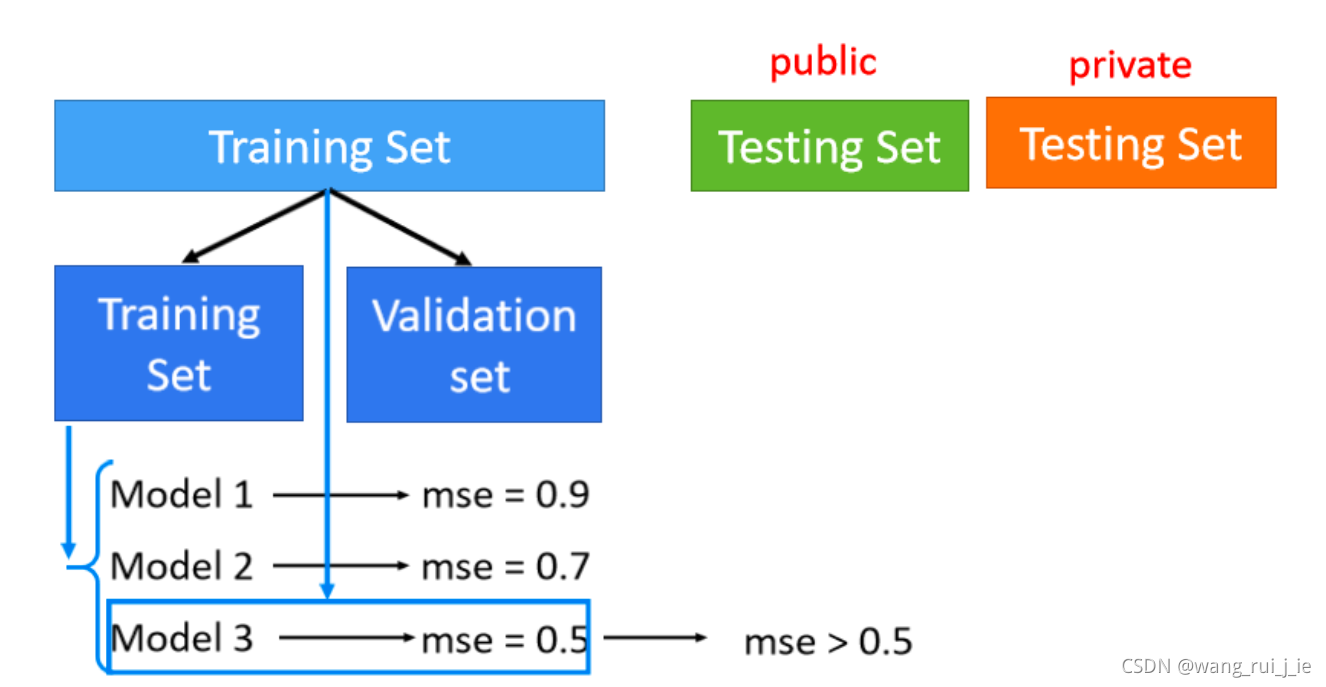
2、N-fold Cross Validation
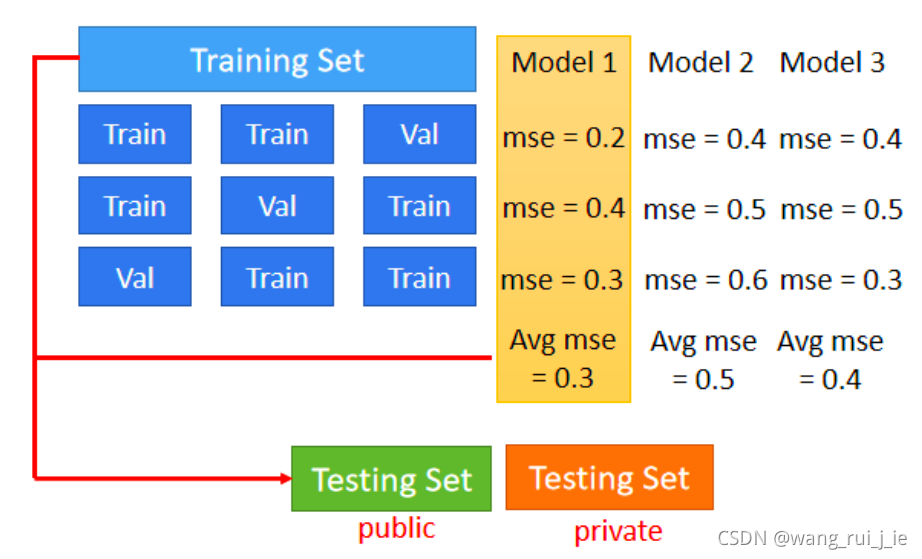
# 挑选出训练集和验证集
def get_k_fold_data(k,i,X,y):
# 返回第i折交叉验证时所需要的训练和验证数据
assert k>1
fold_size = X.shape[0] // k
X_train,y_train = None,None
for j in range(k):
idx = slice(j * fold_size,(j + 1) * fold_size)
X_part,y_part = X[idx,:],y[idx]
if j == i:
X_valid,y_valid = X_part,y_part
elif X_train is None:
X_train,y_train = X_part,y_part
else:
X_train = torch.cat((X_train,X_part),dim=0)
y_train = torch.cat((y_train,y_part),dim=0)
return X_train,y_train,X_valid,y_valid03 Local Minimum And Saddle Point
一、Critical Point
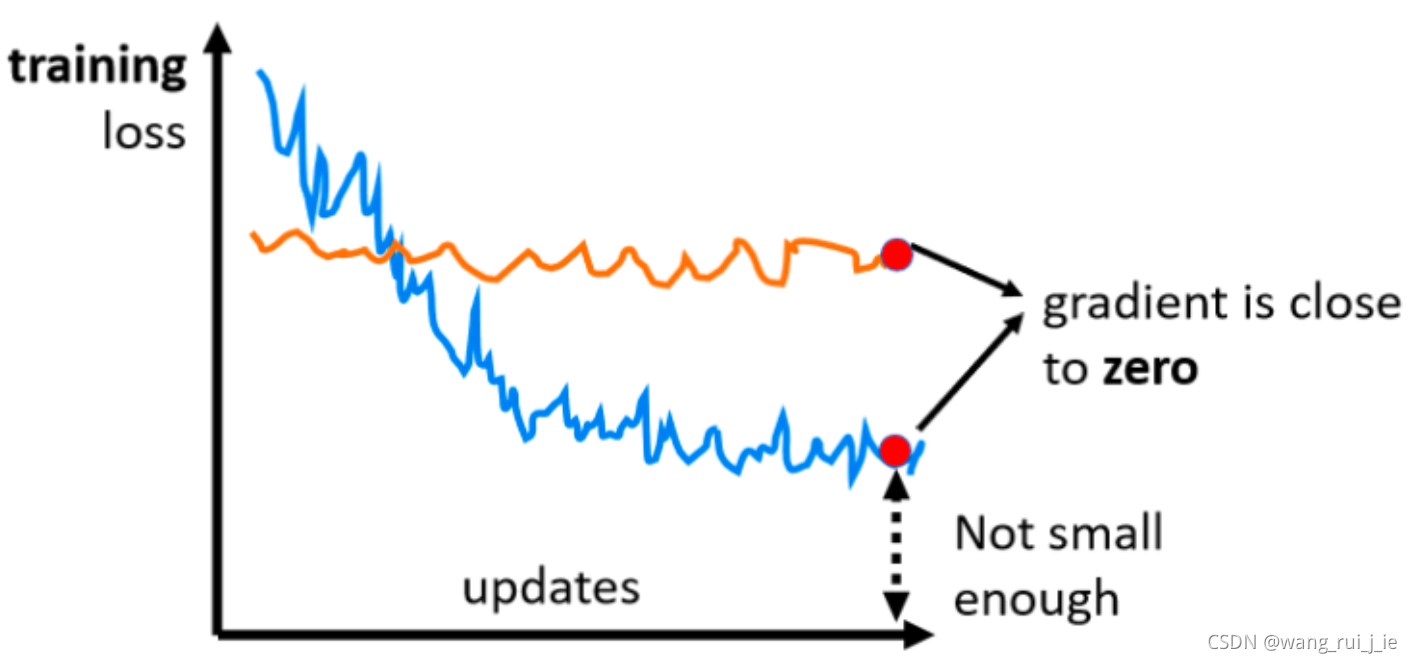

那么如何判断是local minima还是saddle point?

04 Batch and Momentum
一、Optimization with Batch
1.Small Batch v.s. Large Batch
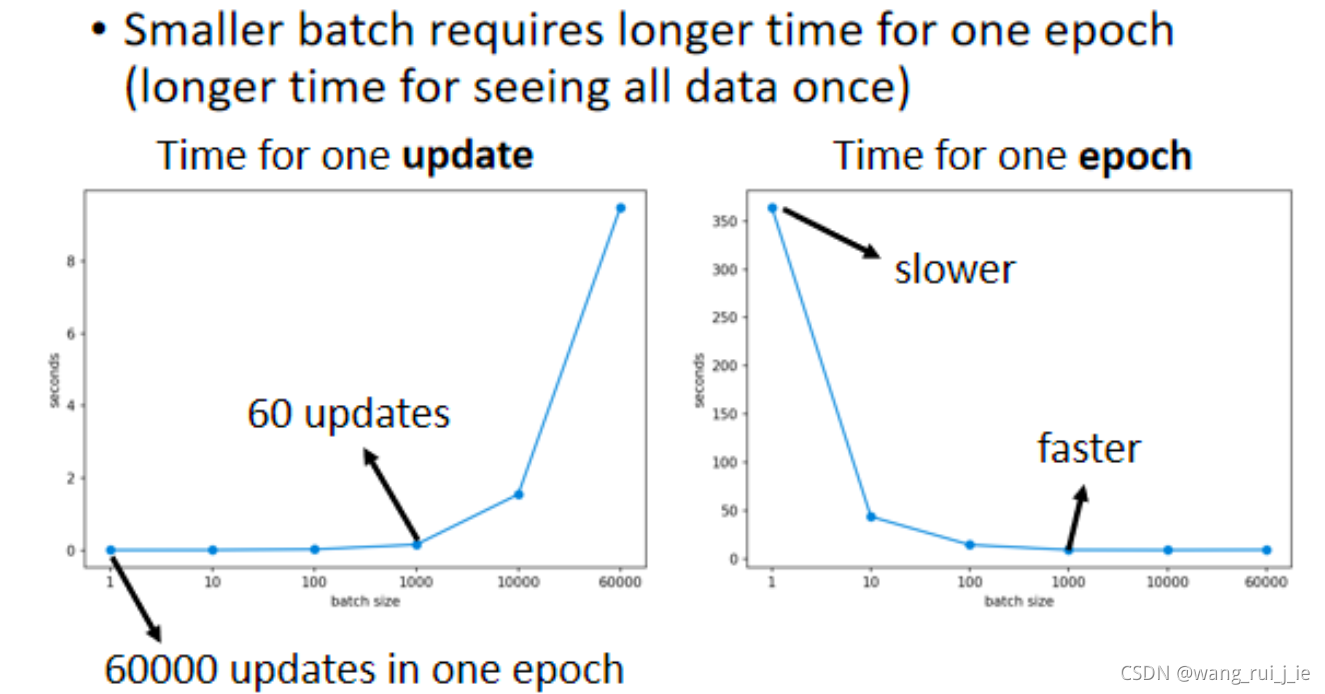
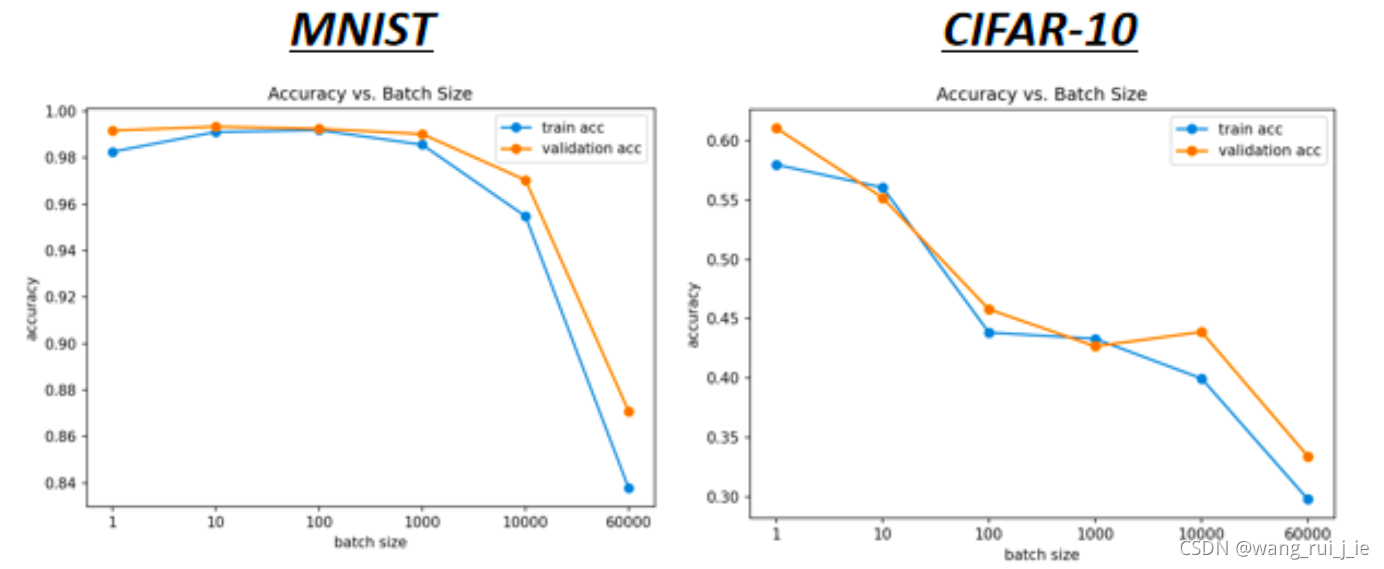
2.Accuracy vs Batch size
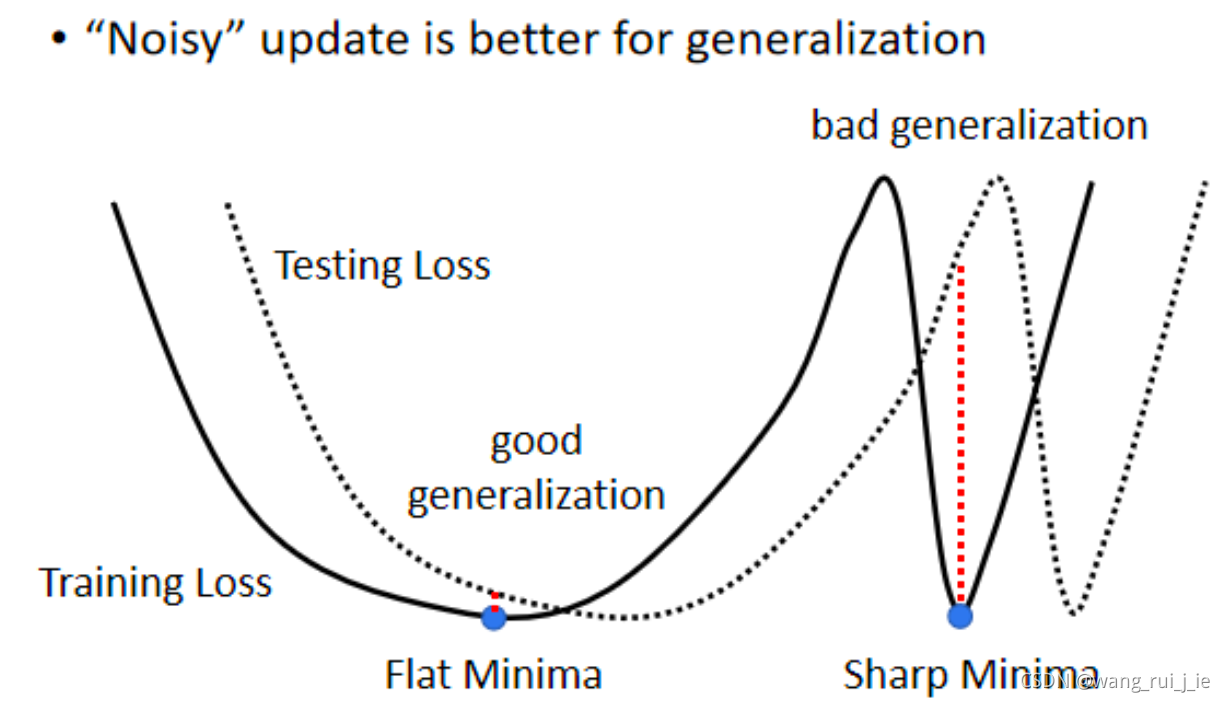
二、Momentum
1.Vanilla Gradient Descent
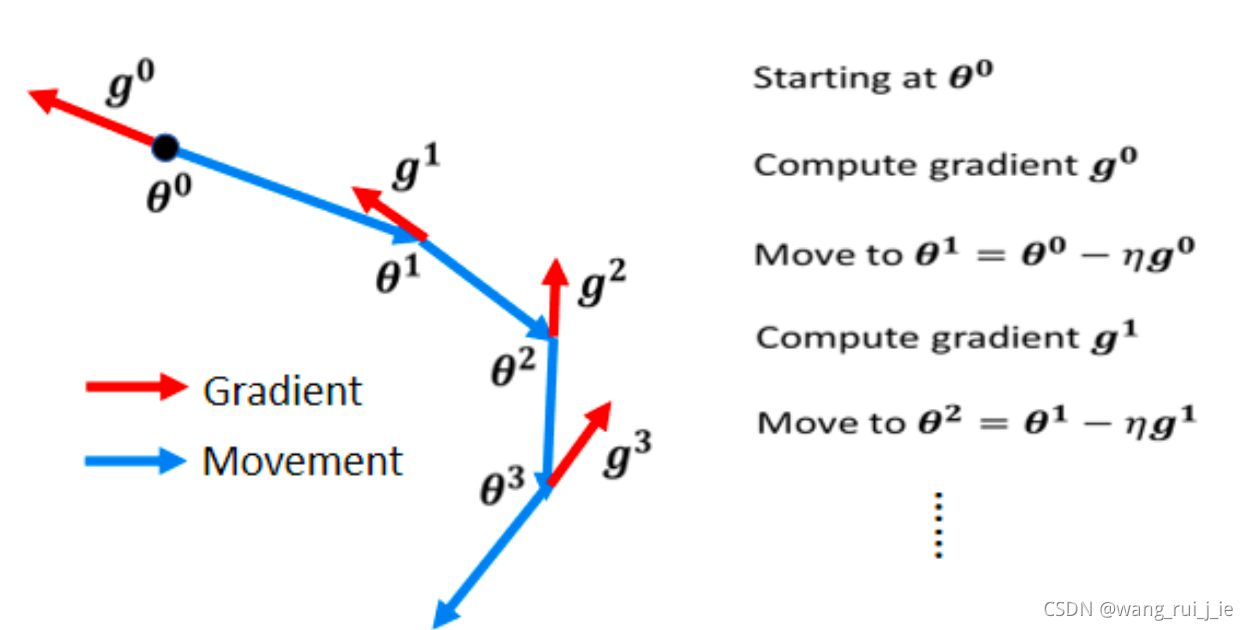
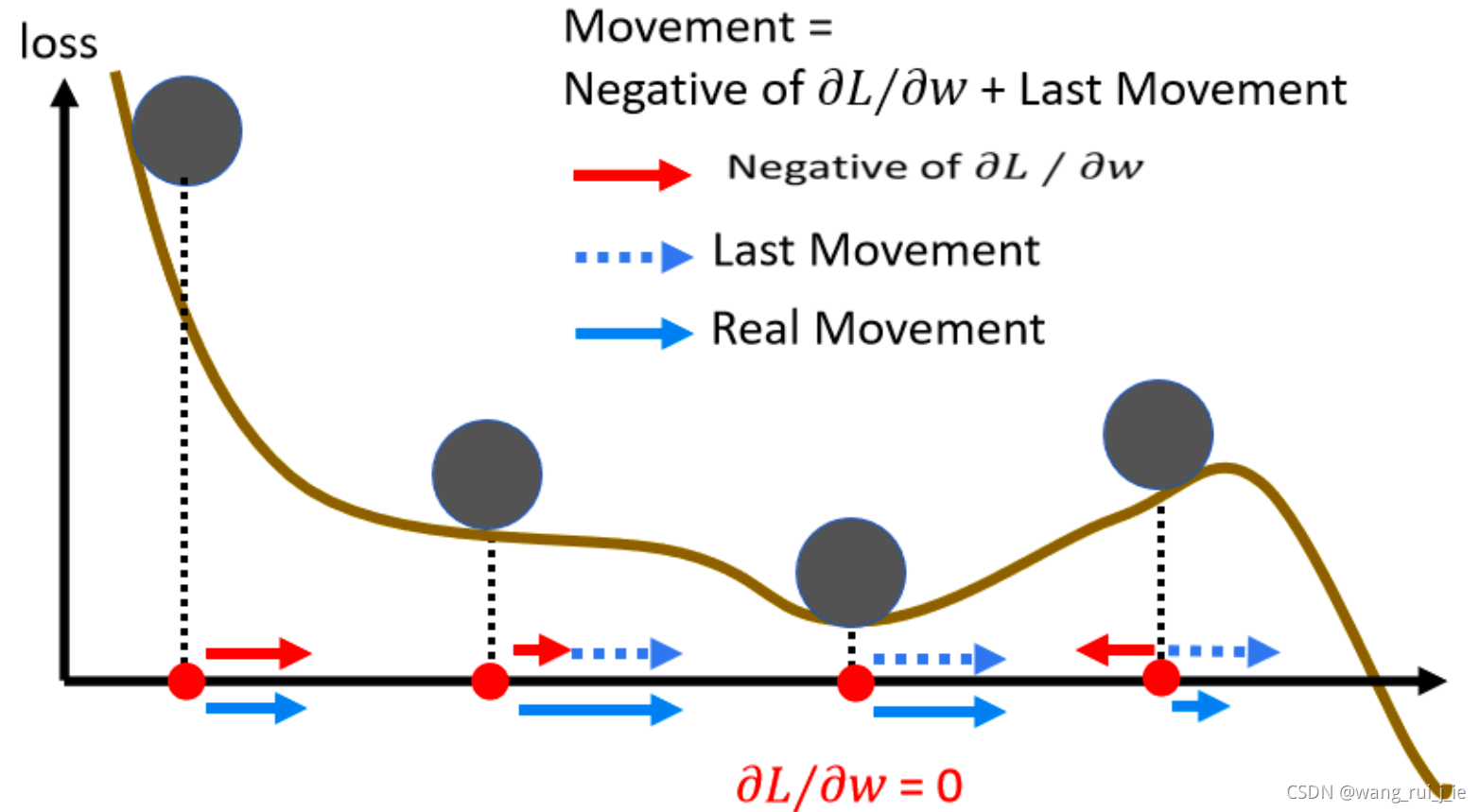
2.Gradient Descent + Momentum
05 Adaptive Learning Rate
一、Tips for training: Adaptive Learning Rate
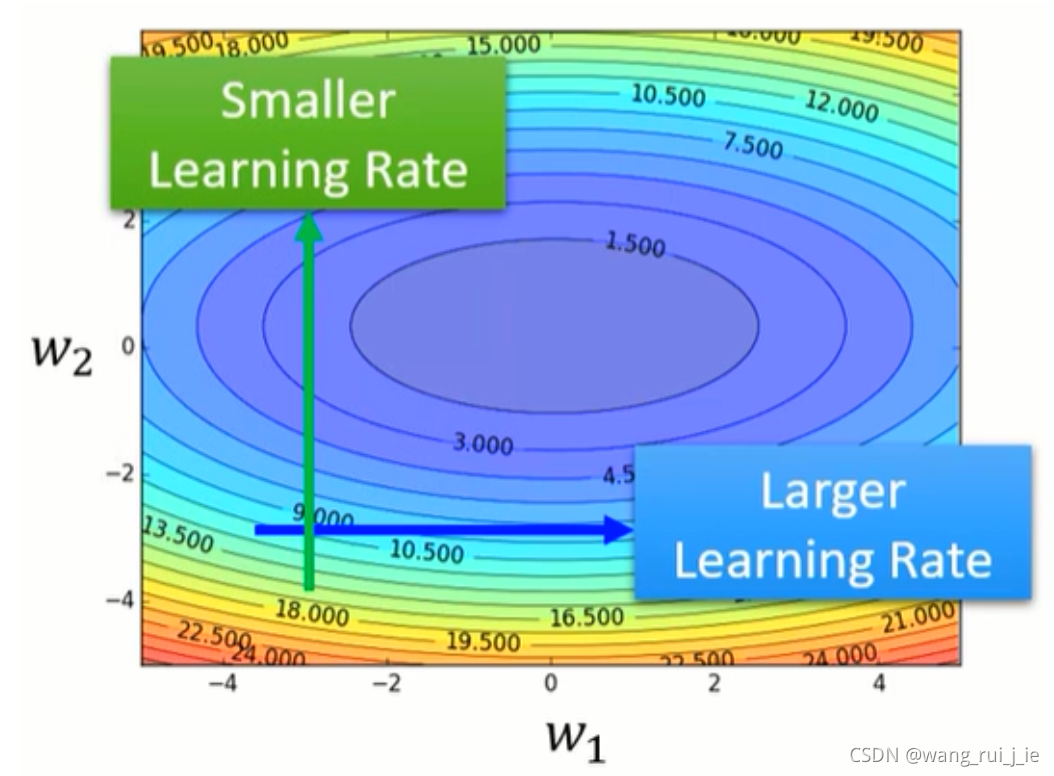
定制版Learning Rate:
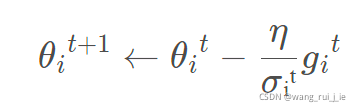
1.Adagrad
(1)Root mean square:
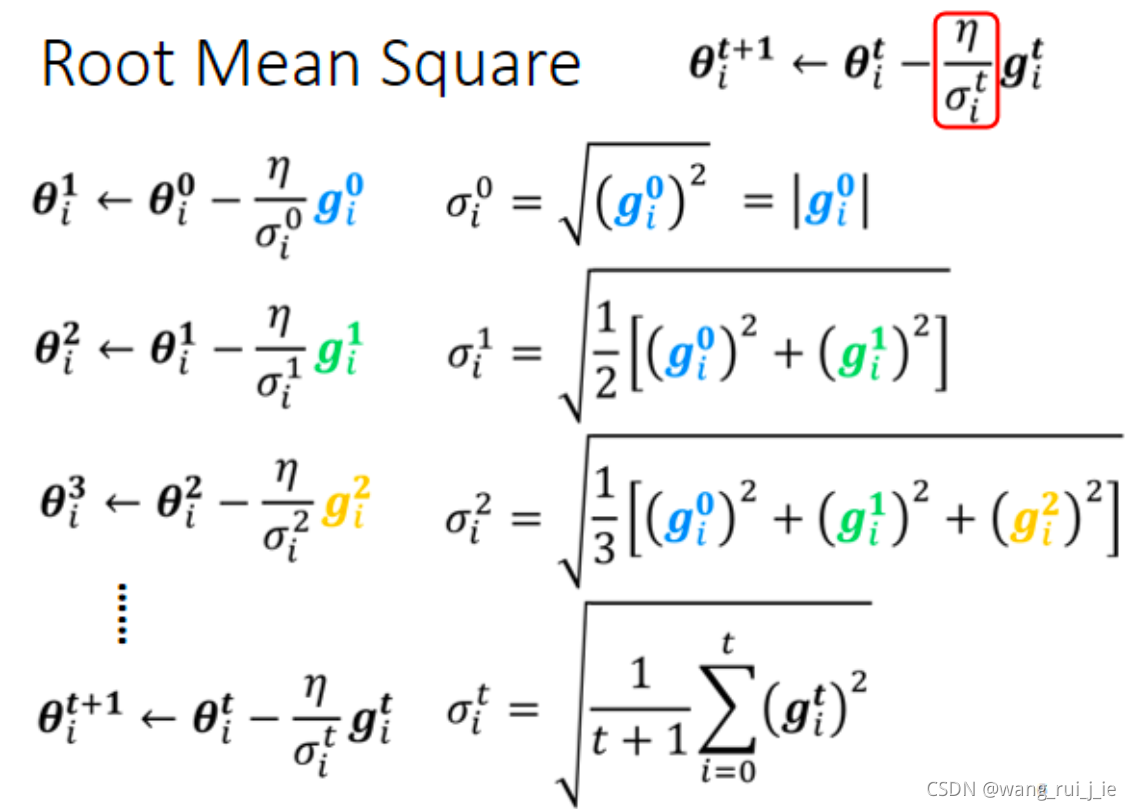
终极版本:
2.RMSProp
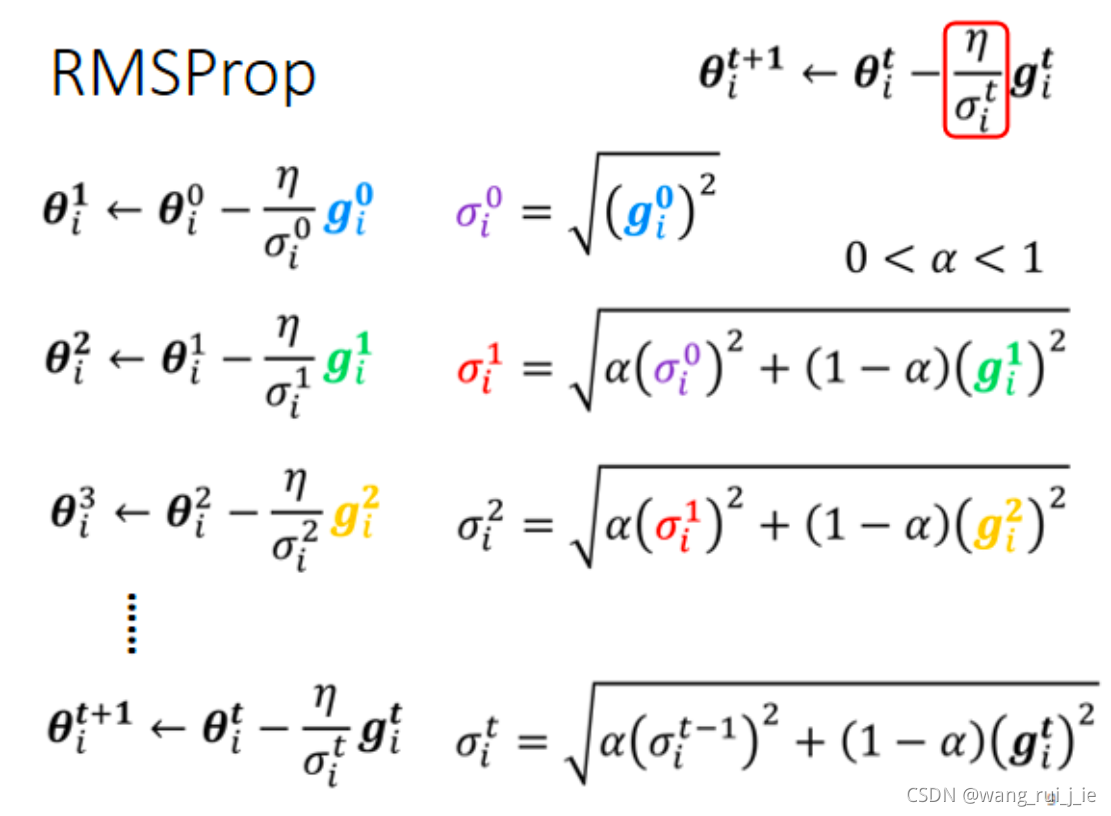
Adam : RMS Prop + Momentum
06 Classification
一、Class as one-hot vector
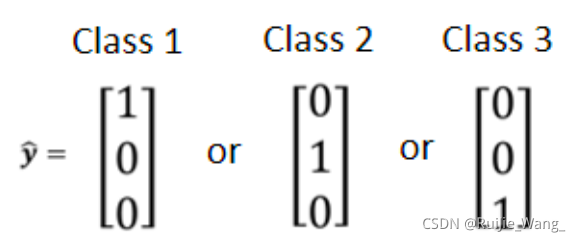
1.Classification with softmax
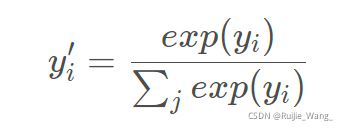
# Fashion-MNIST是⼀个10类服饰分类数据集
import torch
import torchvision
import torchvision.transforms as transform
from torch.utils.data import DataLoader
import numpy as np
import time
import sys
minist_train = torchvision.datasets.FashionMNIST(root='./datasets/FashionMNIST',train=True,download=True,transform = transform.ToTensor())
minist_test = torchvision.datasets.FashionMNIST(root='./datasets/FashionMNIST',train=False,download=True,transform=transform.ToTensor())
print(type(minist_test))
print(len(minist_train),len(minist_test))
feature,label = minist_train[0]
print(feature.shape,label)
# 以下函数可以将数值标签转成相应的文本标签
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress',
'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankleboot']
return [text_labels[int(i)] for i in labels]
batch_size = 256
train_iter = DataLoader(minist_train,batch_size=batch_size,shuffle=True)
test_iter = DataLoader(minist_test,batch_size=batch_size,shuffle=False)
num_inputs = 784
num_outputs = 10
W = torch.tensor(np.random.normal(0,0.01,(num_inputs,num_outputs)),dtype=torch.float32)
b = torch.zeros(num_outputs,dtype=torch.float32)
W.requires_grad_(True)
b.requires_grad_(True)
def softMax(X):
X_exp = X.exp()
partition = X_exp.sum(dim=1,keepdim=True)
return X_exp / partition
def sgd(params , lr, batch_size): # 随机梯度下降更新参数
for param in params:
param.data -= lr * param.grad / batch_size
def net(X):
return softMax(torch.mm(X.view(-1,num_inputs),W)+b)
def cross_entropy(y_hat,y):
# 这里gather相当于挑选
# 如y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
# y = torch.LongTensor([0, 2])
# y_hat.gather(1, y.view(-1, 1)) ,得到的结果就是tensor([[0.1000],[0.5000]]),这个0.1拿来做交叉熵效果就很差,能体现出不太正确
return -torch.log(y_hat.gather(1,y.view(-1,1))) #所以这里的y_hat.gat....得到的就是真正的对应着y的y_hat的概率,拿来做交叉熵
def accuracy(y_hat,y):
#其中 y_hat.argmax(dim=1)返回矩阵y_hat每⾏中最⼤元素的索引,且返回结果与变量y形状相同。
return (y_hat.argmax(dim=1) == y).float().mean().item()
def evaluate_accuracy(data_iter,net):
acc_sum,n = 0.0,0
for X,y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
epoch,lr = 5,0.1
def train(net,train_iter,test_iter,loss,epoch,batch_size,params=None, lr=None, optimizer=None):
for epoch in range(epoch):
train_loss, train_acc, n = 0.0, 0.0, 0
for X,y in train_iter:
y_hat = net(X)
l = loss(y_hat,y).sum()
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
sgd(params, lr, batch_size)
else:
optimizer.step()
train_loss += l.item()
train_acc += (y_hat.argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter,net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_loss / n, train_acc / n,
test_acc))
train(net,train_iter,test_iter,cross_entropy,epoch,batch_size,[W,b],lr)07 Batch Normalization
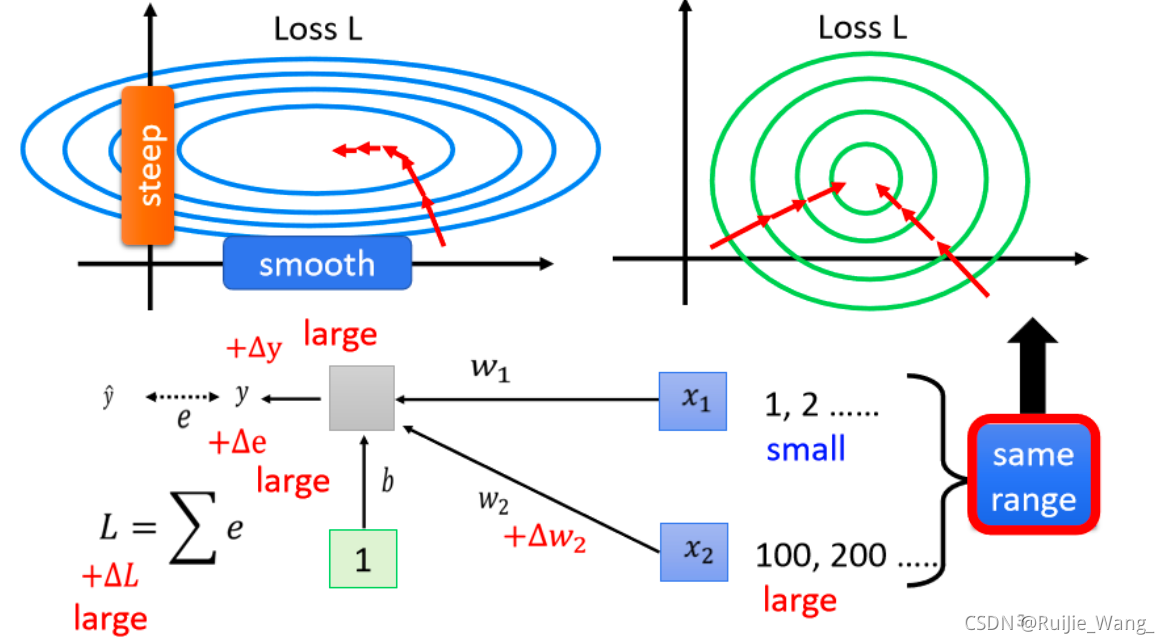
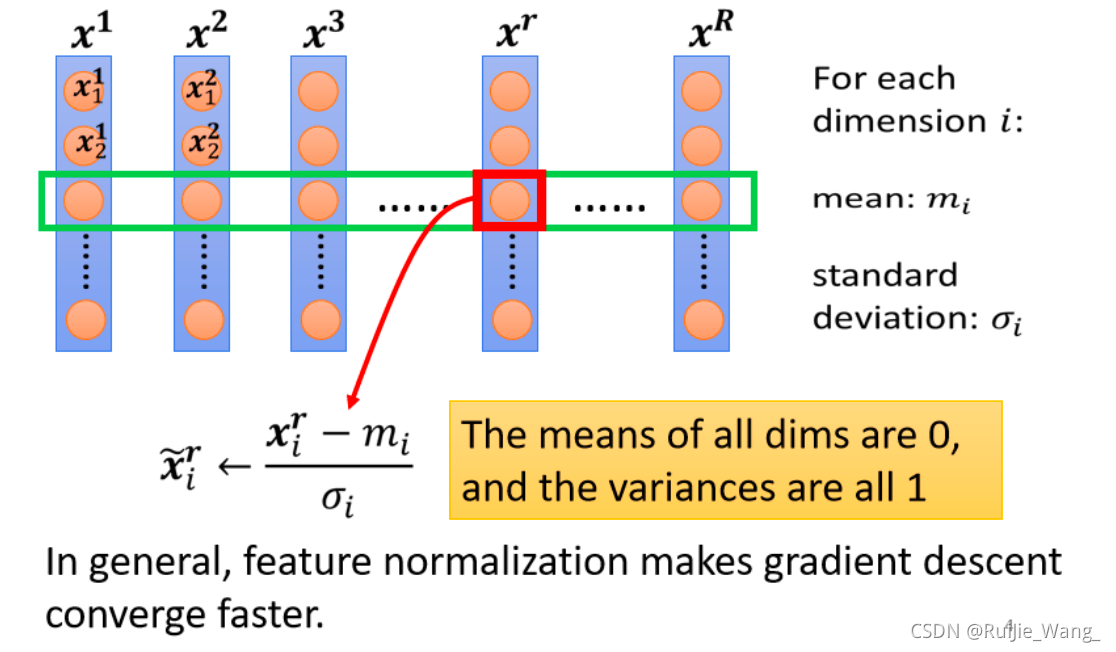
一、Feature Normalization
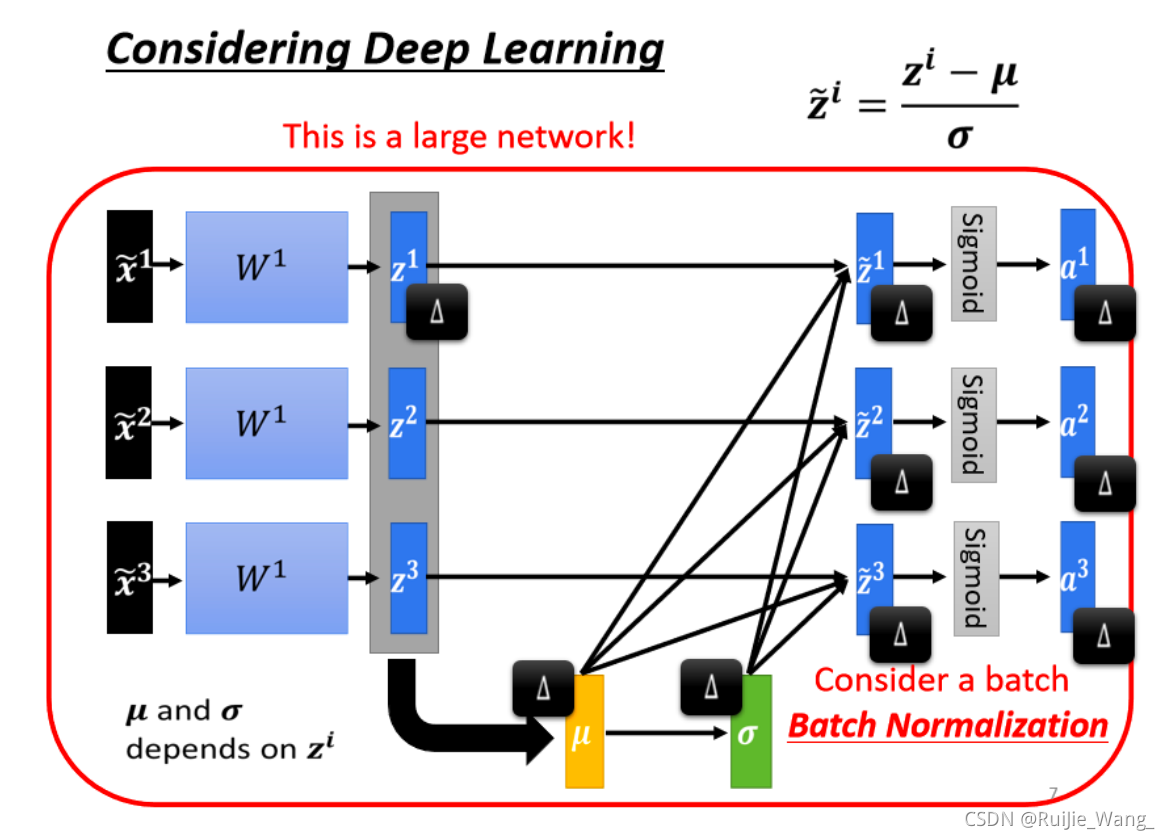
二、Considering Deep Learning
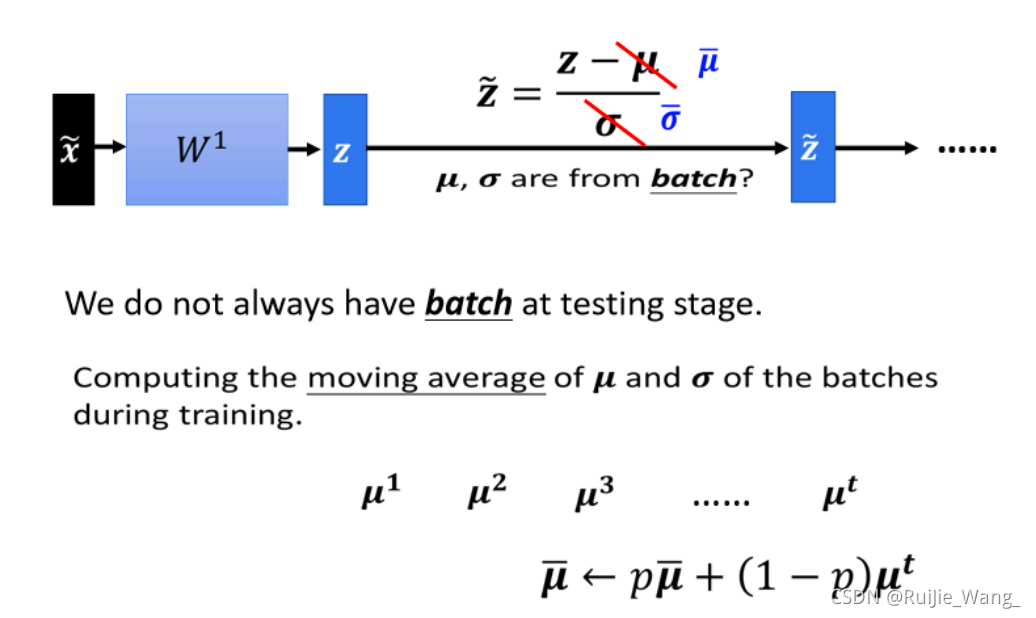
三、Testing

















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









