



在信息爆炸的时代,搜索引擎已成为我们获取知识、解决问题的重要工具。然而,随着数据量的激增和用户需求的多样化,传统的搜索引擎面临着精准度不足和结果单一化的挑战。
为了应对这些挑战,基于检索增强生成(Retrieval-Augmented Generation, RAG)的技术应运而生,它通过结合检索和生成两个阶段来提升搜索的精准度和丰富性。本文将对RAG技术进行深入分析,并探讨其在搜索领域的应用前景。
RAG技术概述
RAG技术是一种结合了信息检索和文本生成的人工智能方法。它通过从大规模数据源中检索相关信息来增强语言模型的回答能力。
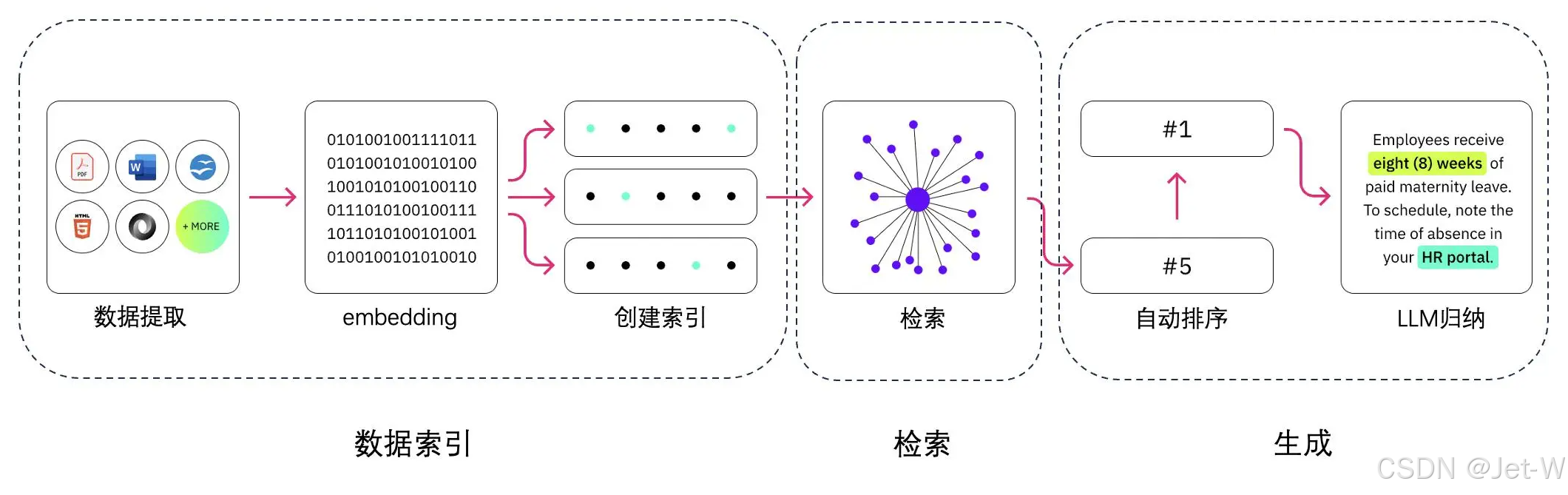
RAG的核心组件:检索器(Retriever)和生成器(Generator)
检索器(Retriever)
检索器负责从知识库中检索与用户查询最相关的信息片段。这一过程通常涉及以下步骤:
文档向量化:使用预训练的语言模型将文档转换为向量表示。
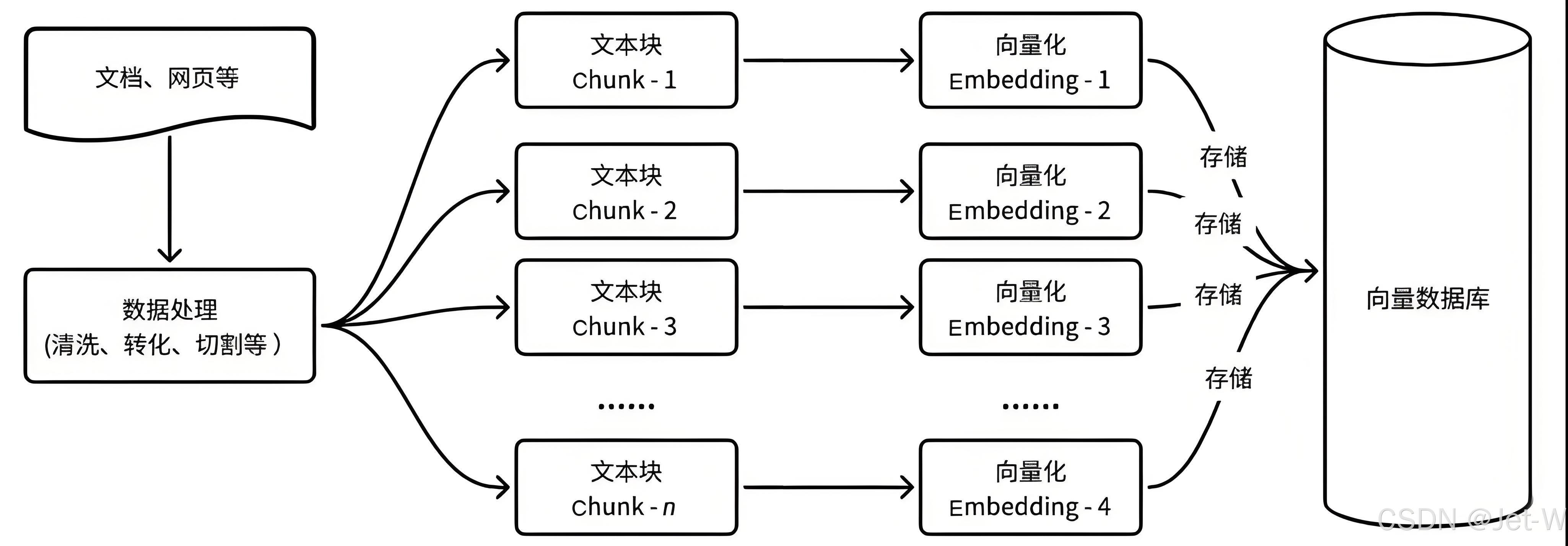
常见文档向量化方法
One-Hot Encoding
这是最基本的词向量表示方法,每个单词被表示为一个与词汇表大小相同的向量,其中只有一个元素为1,其余为0。这种方法简单但无法表达词与词之间的关系,且维度很高。
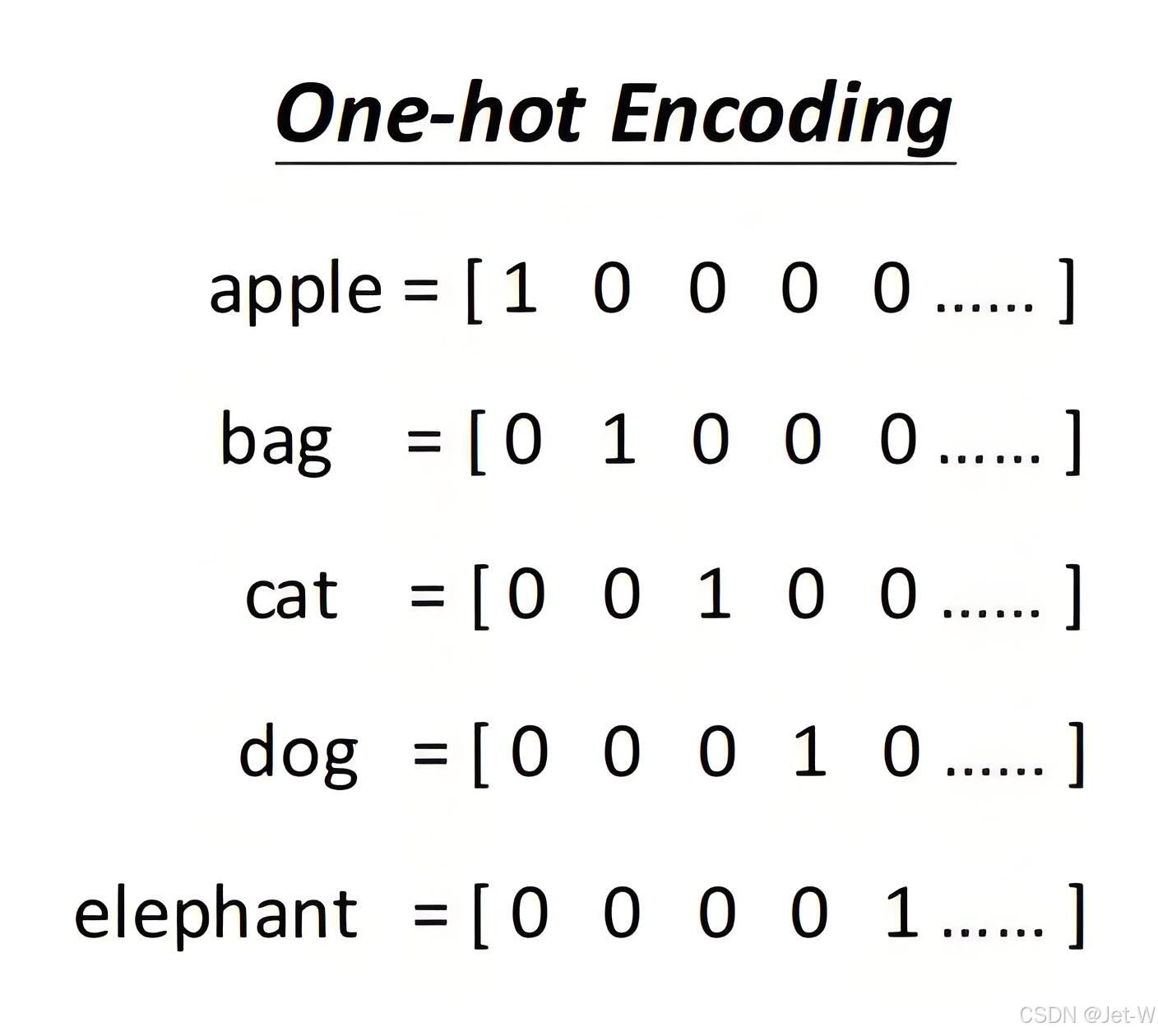
cat\dog\elephant是同一类的,都属于动物,他们之间应当存在联系,apple 和 其它四个内容没有联系。但是,从上述的编码中我们没法看出cat\dog\elephant存在某种关系。
词袋模型(Bag of Words Model)
不考虑文本中单词的顺序和语法关系,将文本表示为单词的集合,每个单词的出现次数作为特征。这种方法通过统计每个单词在文本中出现的频率来量化文本。
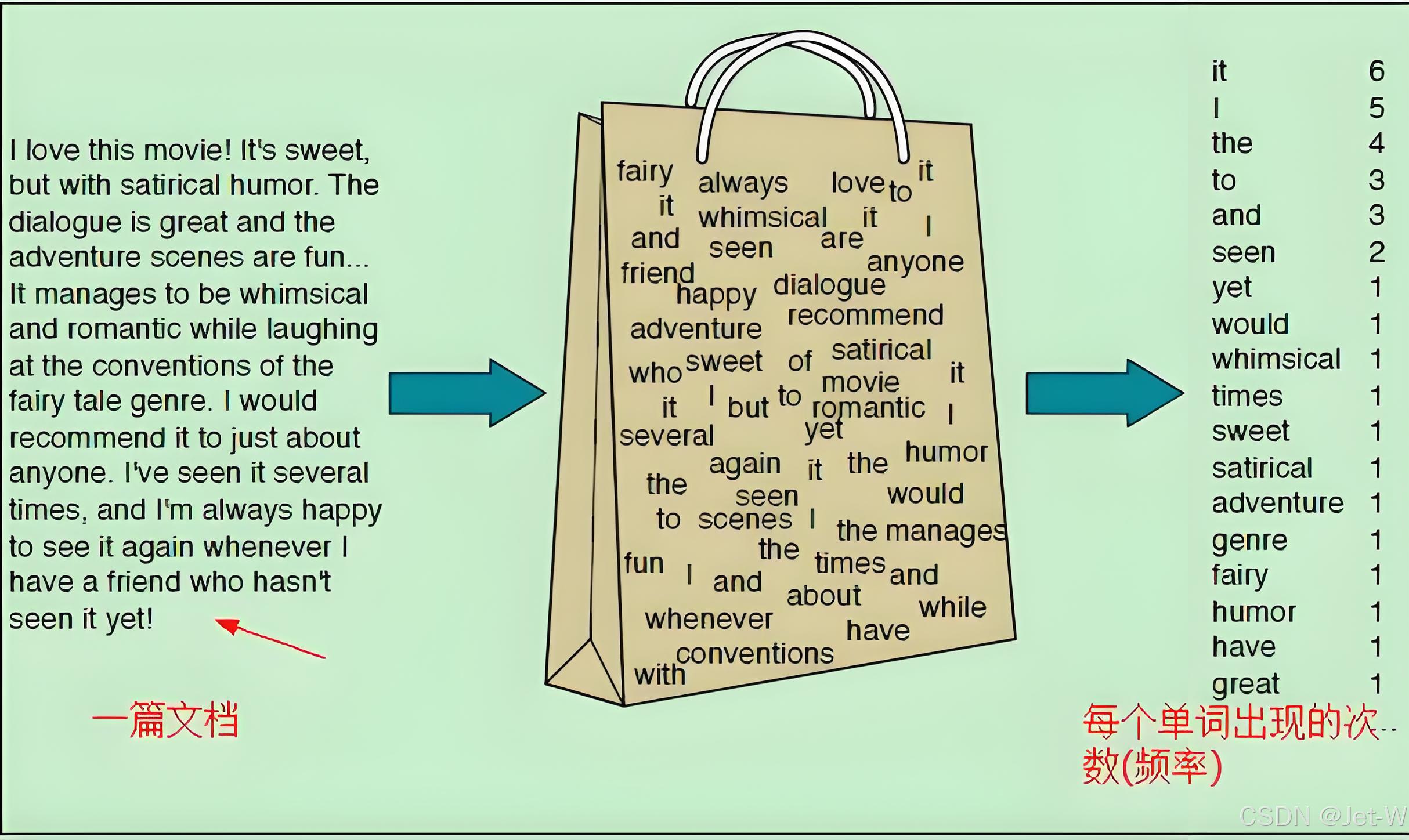
只考虑单词出现的次数,不考虑语法和语义信息,可能会丢失一些重要信息。
词频-逆文档频率(TF-IDF)
是词袋模型的一个扩展,通过考虑单词在文档集合中的逆文档频率来减少常见单词的权重,增强罕见单词的权重。
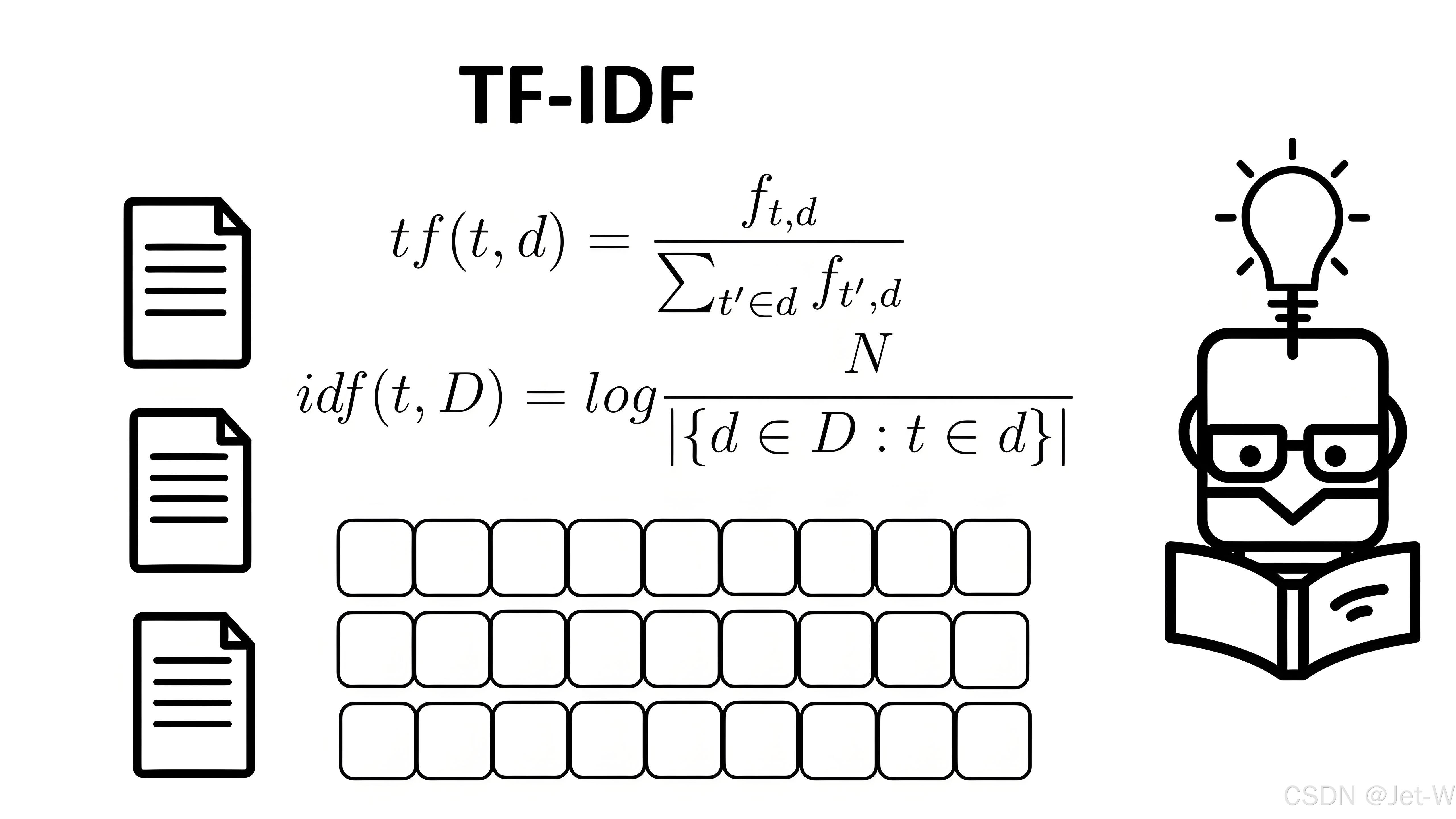
由简单的词出现次数统计,优化为根据权重加权来统计词频。
Word2Vec
一种基于神经网络的词嵌入方法,通过训练得到每个词的向量表示。
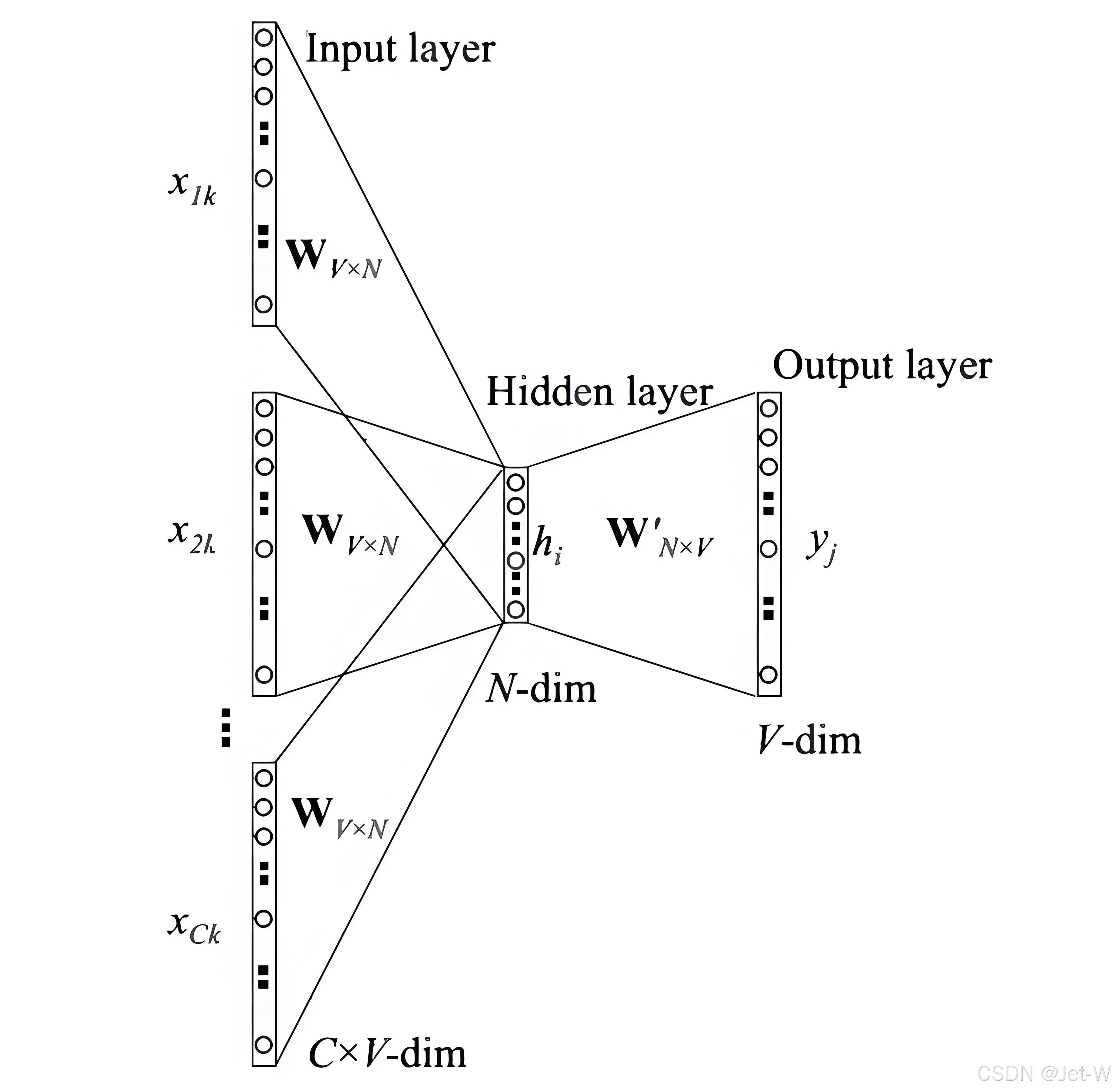
CBOW模型,根据上下文预测中间词,这里输入仍然是每个词汇的one-hot向量,输出为给定词汇表中每个词作为目标词的概率。
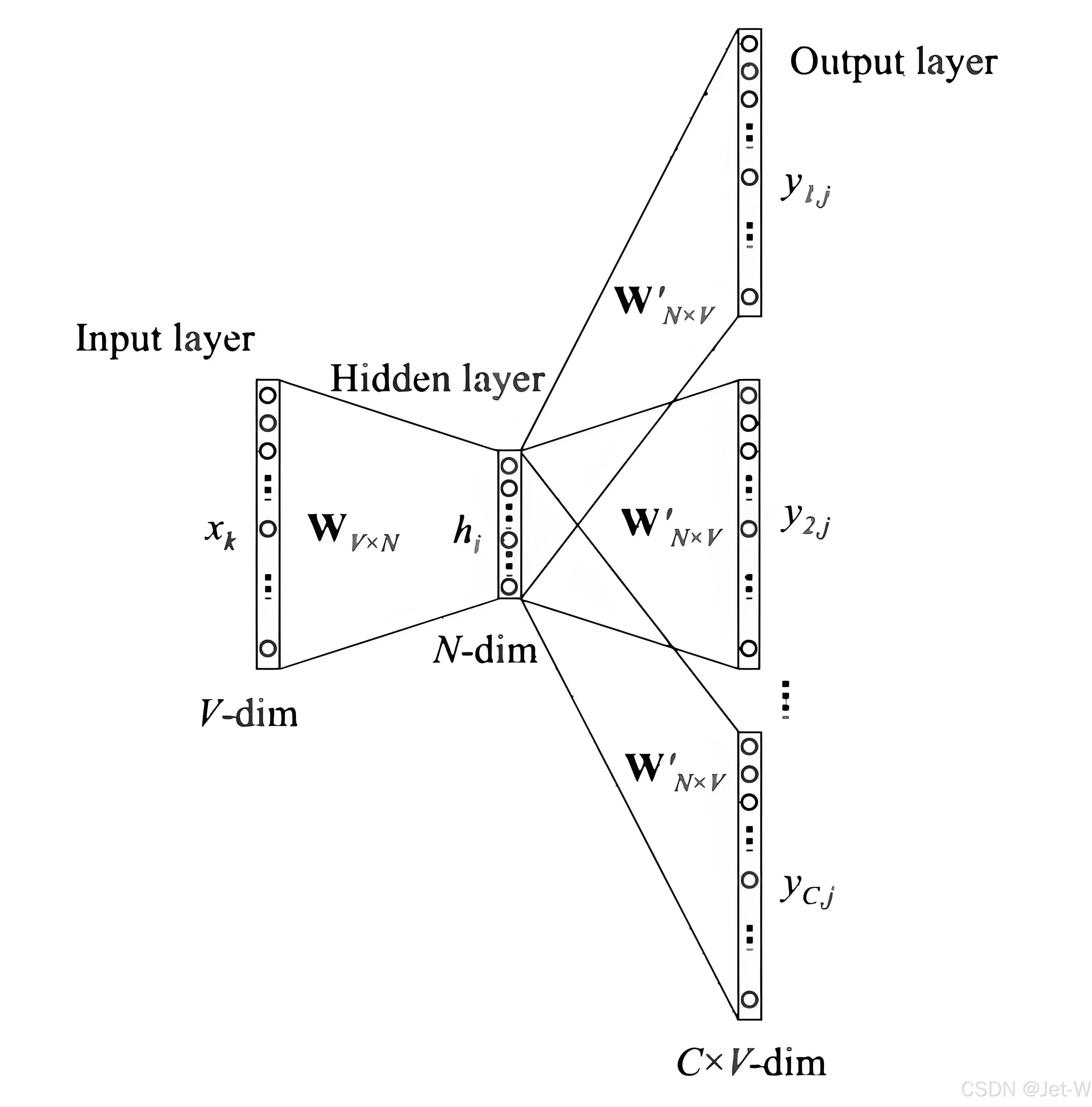
Skip-gram模型,根据中间词预测上下文词,输入是任意单词,输出为给定词汇表中每个词作为上下文词的概率。
Doc2Vec
Word2Vec的一个扩展,用于处理整个文档或句子。
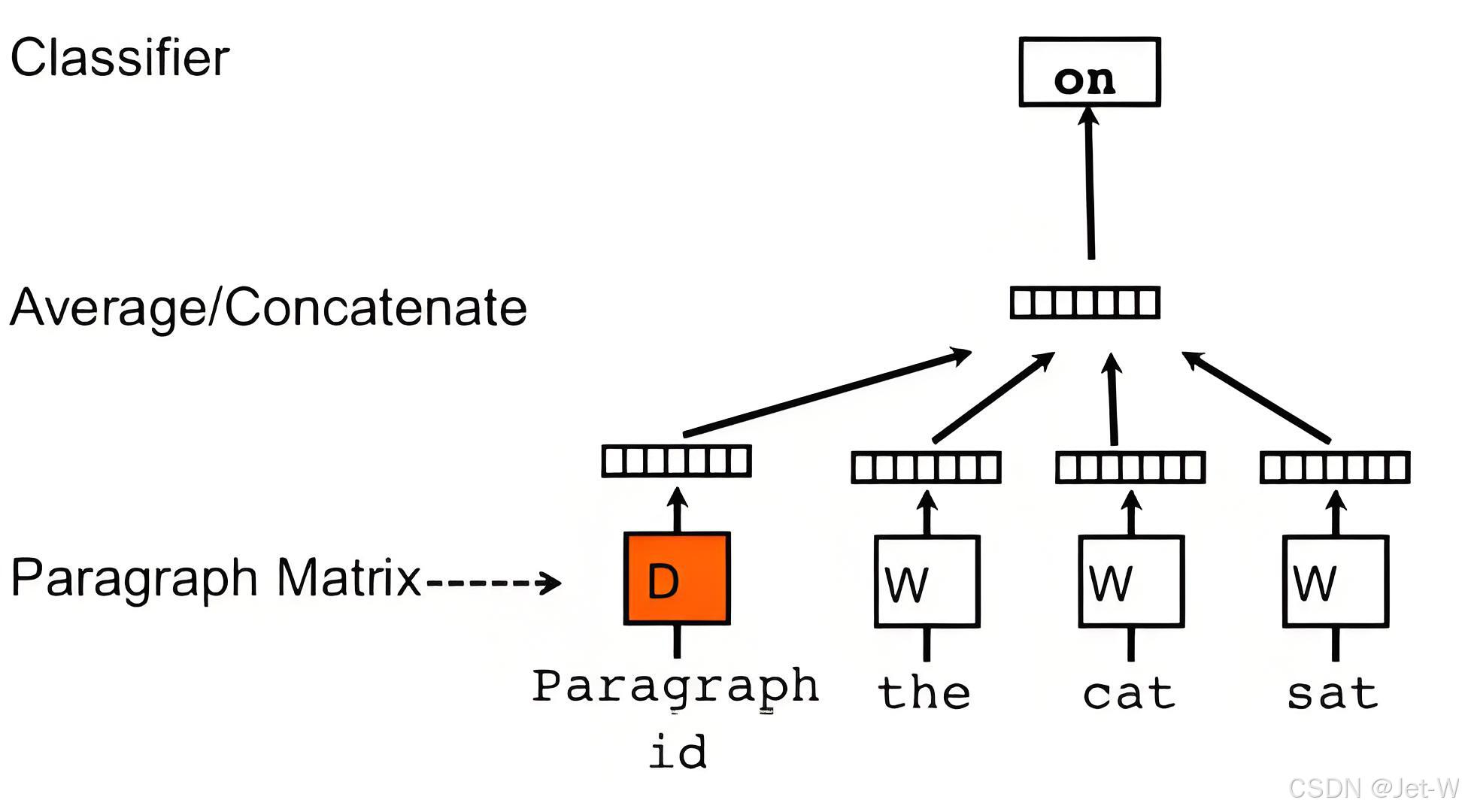
使用了word2vec模型,并添加了另一个向量(段落id),对于每个文档是唯一的。
FastText
由Facebook AI Research开发,与Word2Vec类似,但增加了对词内部结构(如前缀和后缀)的建模,能够更好地处理罕见词和新词。
GloVe(Global Vectors for Word Representation)
通过矩阵分解的方法,利用全局词频统计信息来学习词向量,能够捕捉词与词之间的语义和语法关系。
ELMo(Embeddings from Language Models)
由Allen NLP团队提出,使用深度双向语言模型来生成每个词的上下文相关的词向量。
BERT(Bidirectional Encoder Representations from Transformers)
由Google提出,通过预训练的Transformer模型,生成能够捕捉到丰富上下文信息的词向量。
Sent2Vec
类似于Doc2Vec,但专注于生成句子级别的向量表示,可以用于句子相似度计算、情感分析等任务。
索引构建:将向量表示存储在搜索引擎中,构建索引以便于快速检索。
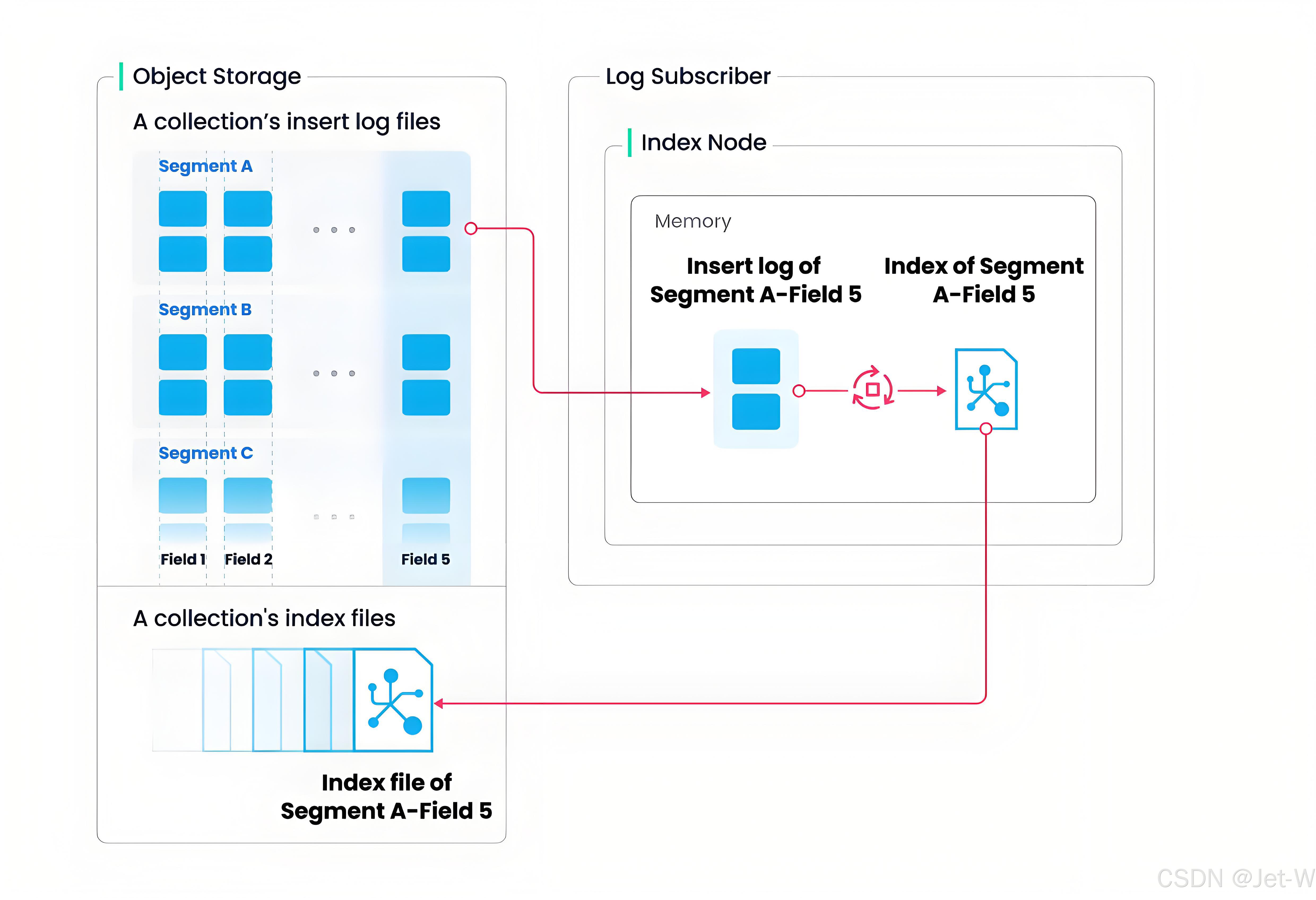
Milvus 索引构建流程:将 collection 分成了更⼩的粒度,即 segment,每个 segment 对应自己的独立的索引。
相似性搜索:根据用户的查询向量,在索引中寻找最相似的文档。
常用的相似度计算算法
欧几里得距离(Euclidean Distance)
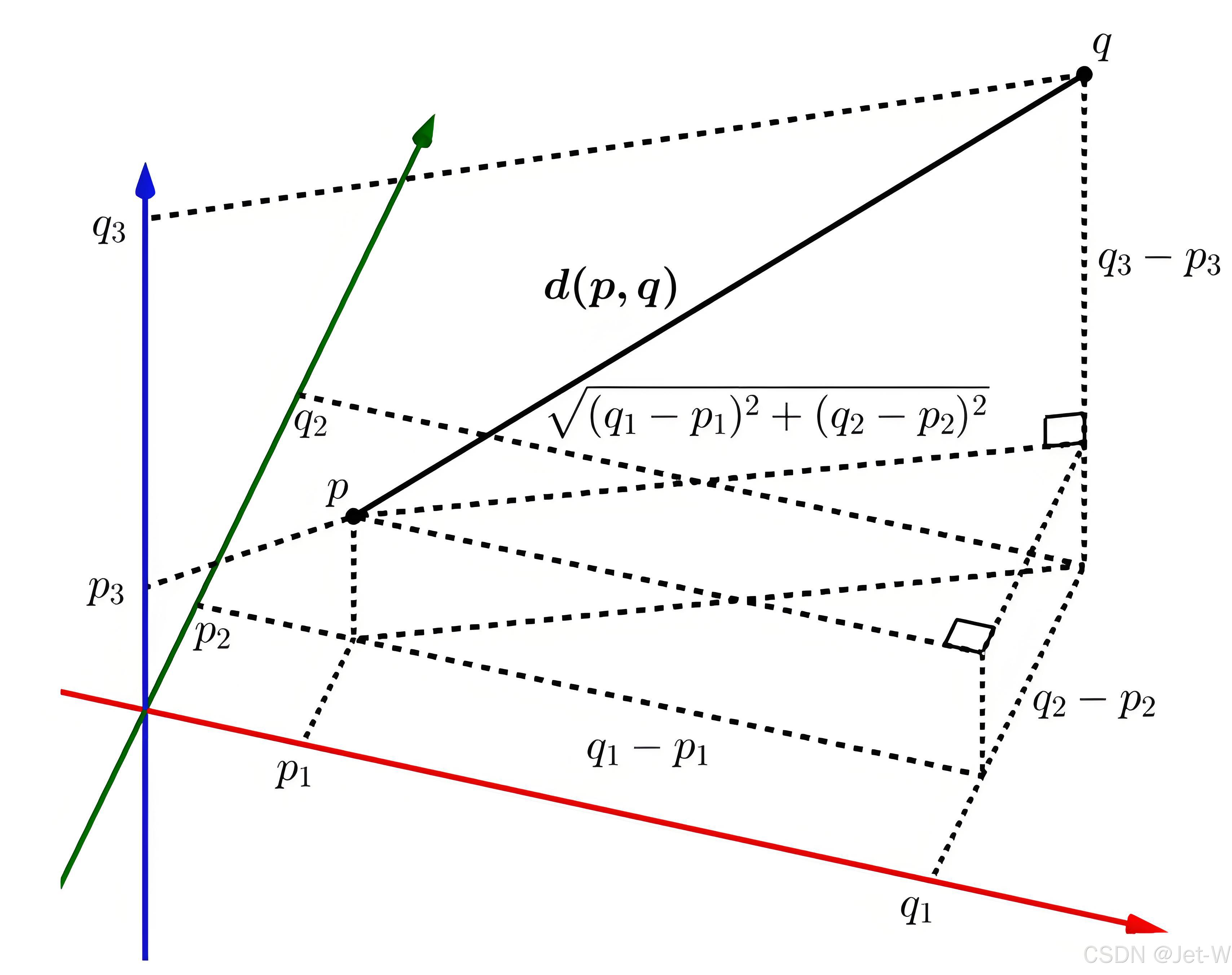
欧几里得距离或欧几里得度量是欧几里得空间中两点间“普通”(即直线)距离。欧几里得距离有时候有称欧氏距离,在数据分析及挖掘中经常会被使用到,例如聚类或计算相似度。
如果我们将两个点分别记作(p1,p2,p3,p4…)和(q1,q2,q3,14,…),则欧几里得距离的计算公式为:
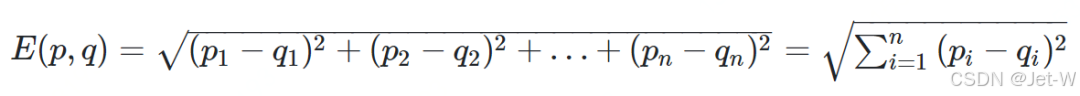
曼哈顿距离(Manhattan Distance)
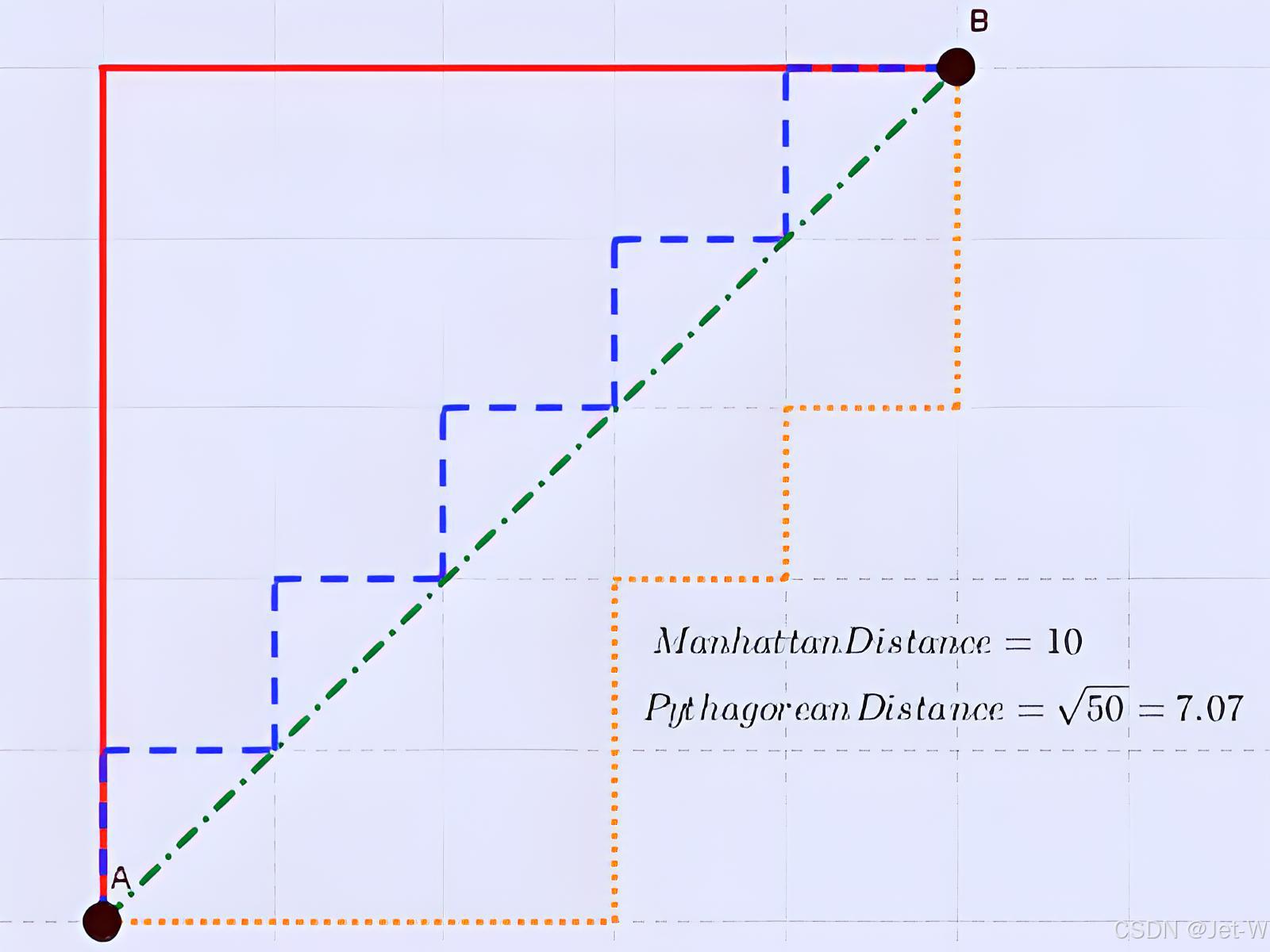
曼哈顿距离是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,是种使用在几何度量空间的几何学用语,用以标明两个点在标准坐标系上的绝对轴距总和。
上图中红线代表曼哈顿距离,绿色代表欧氏距离,也就是直线距离,而蓝色和橙色代表等价的曼哈顿距离。
通俗来讲,想象你在曼哈顿要从一个十字路口开车到另外一个十字路口实际驾驶距离就是这个“曼哈顿距离”,此即曼哈顿距离名称的来源,同时,曼哈顿距离也称为城市街区距离(City Block distance)。
余弦相似度(Cosine Similarity)
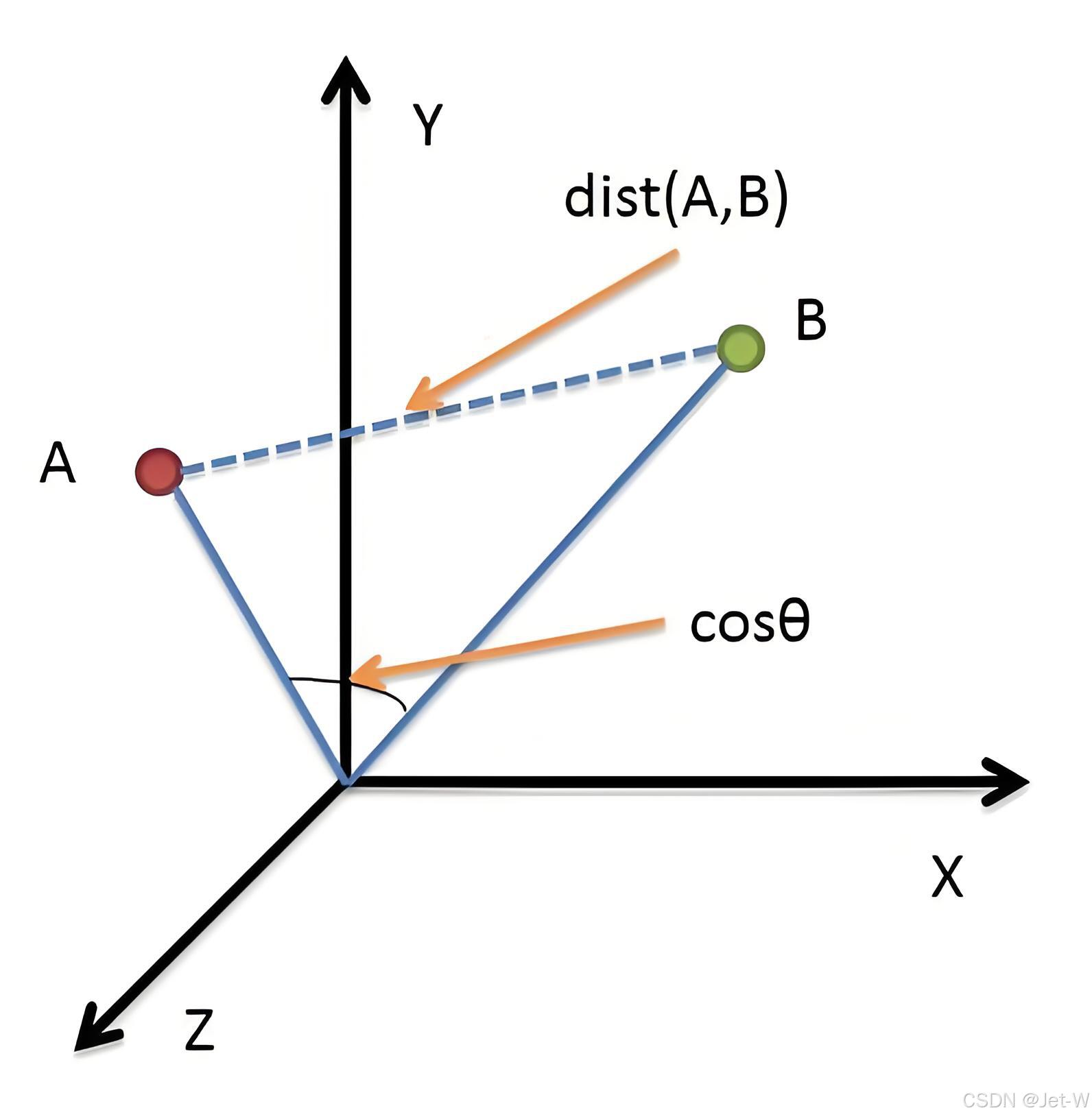
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。
从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。
两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。
这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为0到1之间。
杰卡德相似系数(Jaccard Similarity Coefficient)
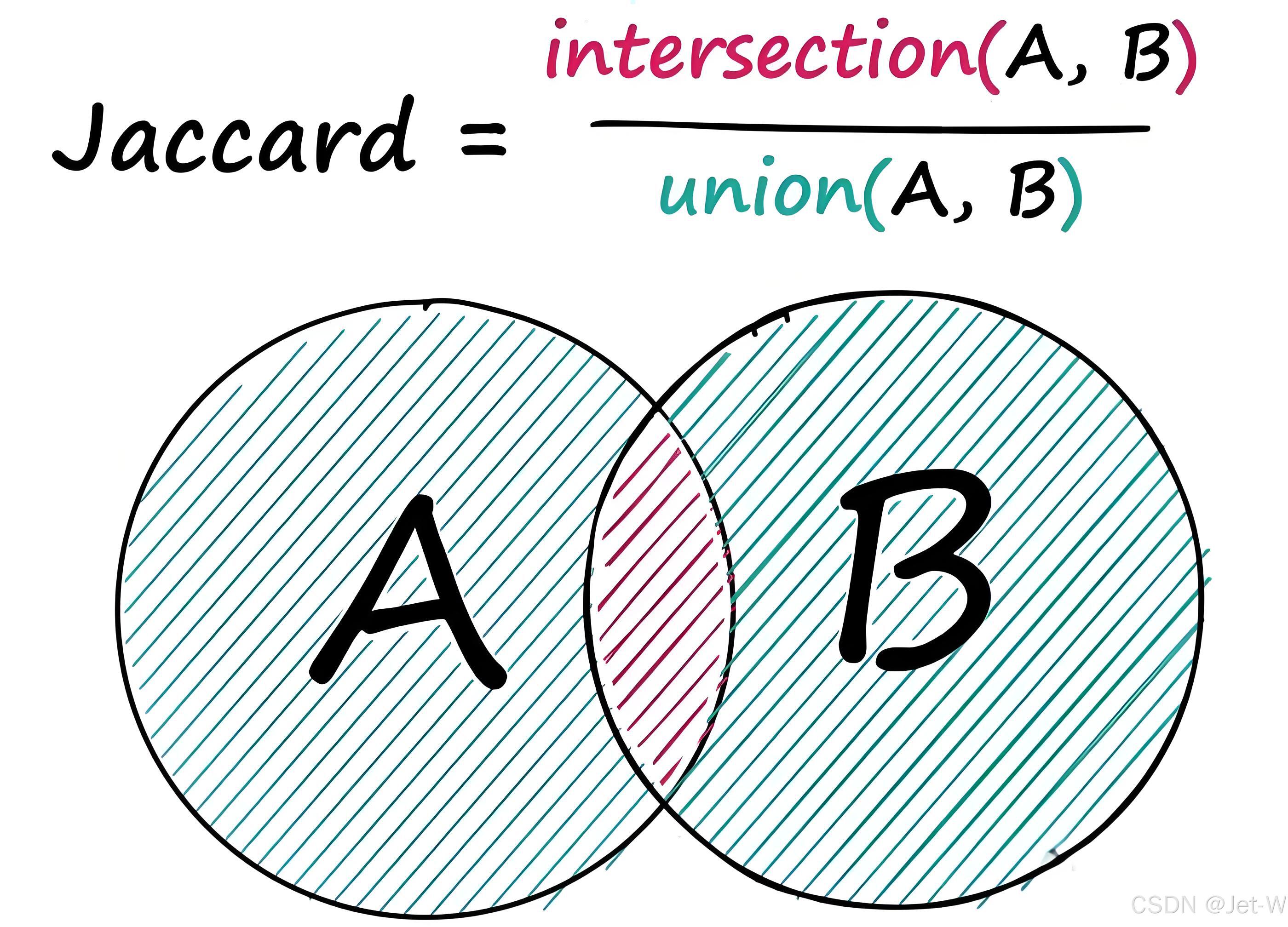
两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B) 表示。
杰卡德相似系数是衡量两个集合相似度的一种指标(余弦距离也可以用来衡量两个集合的相似度)。
汉明距离(Hamming Distance)
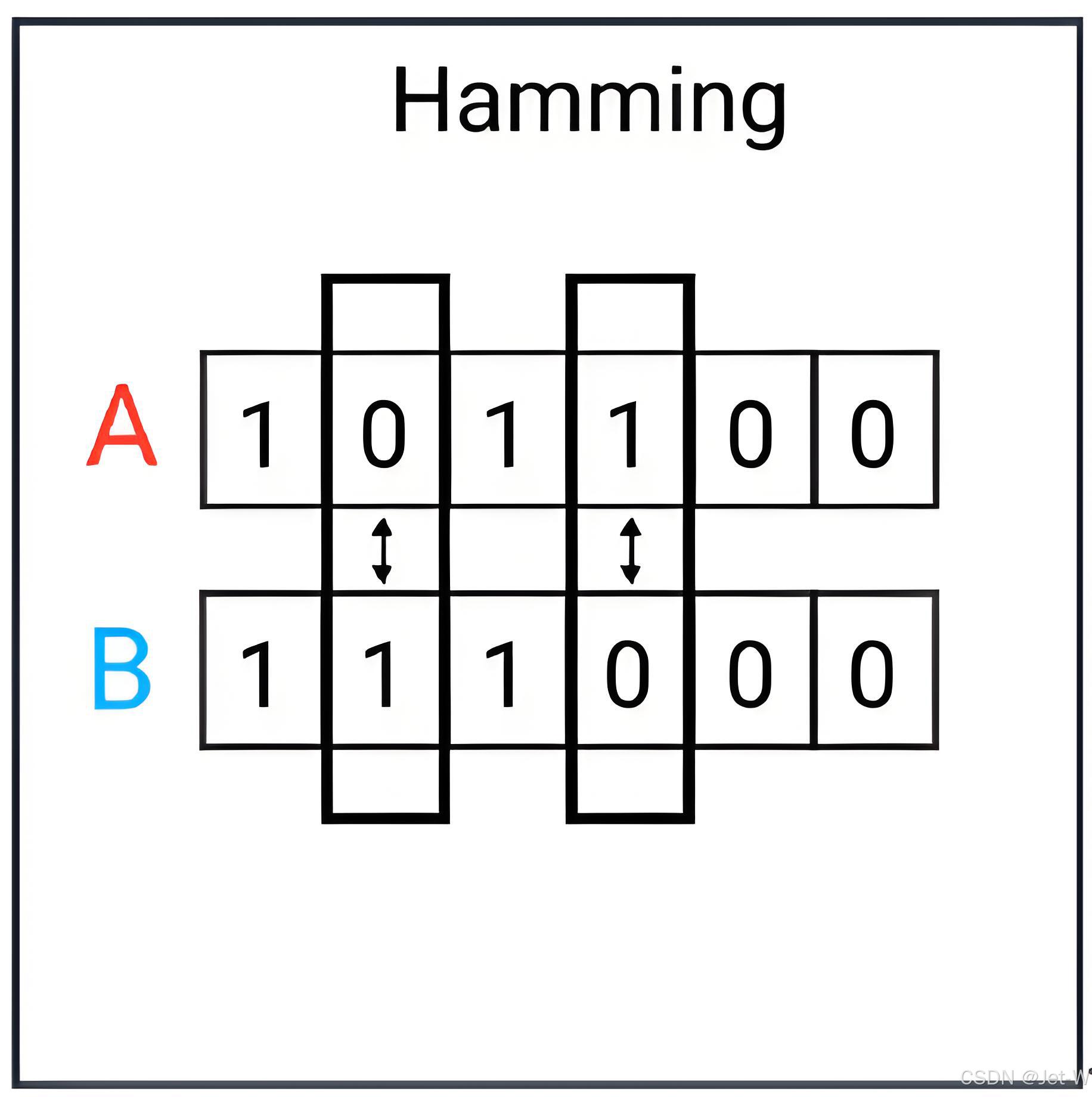
汉明距离有一个最为鲜明的特点就是它比较的两个字符串必须等长,否则距离不成立。
它的核心原理就是如何通过字符替换(最初应用在通讯中实际上是二进制的0-1替换),能将一个字符串替换成另外一个字符串。
汉明距离主要应用在通信编码领域上,用于制定可纠错的编码体系。
在机器学习领域中,汉明距离也常常被用于作为一种距离的度量方式。在LSH算法汉明距离也有重要的应用。与汉明距离比较相近的是编辑距离。
皮尔逊相关系数(Pearson Correlation Coefficient)
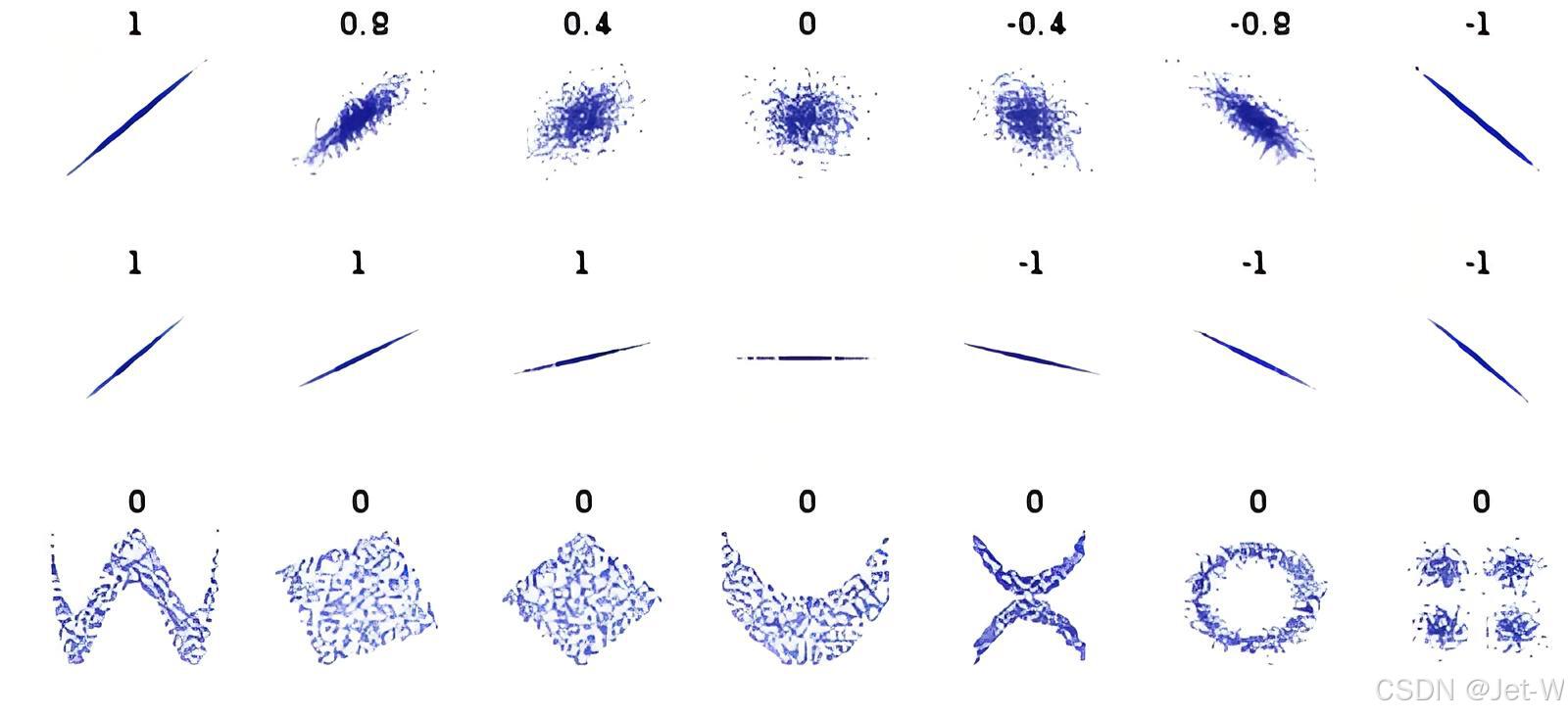
皮尔逊相关系数度量两个向量之间的线性相关性,其值介于-1(完全负相关)和1(完全正相关)之间。
切比雪夫距离(Chebyshev Distance)

切比雪夫距离是两个向量之间各维度差的最大值,它是最坏情况下的距离度量。
若将国际象棋棋盘放在二维直角座标系中,格子的边长定义为1,座标的x轴及y轴和棋盘方格平行,原点恰落在某一格的中心点,则王从一个位置走到其他位置需要的步数恰为二个位置的切比雪夫距离,因此切比雪夫距离也称为棋盘距离。
例如位置F6和位置E2的切比雪夫距离为4。任何一个不在棋盘边缘的位置,和周围八个位置的切比雪夫距离都是1。
生成器(Generator)
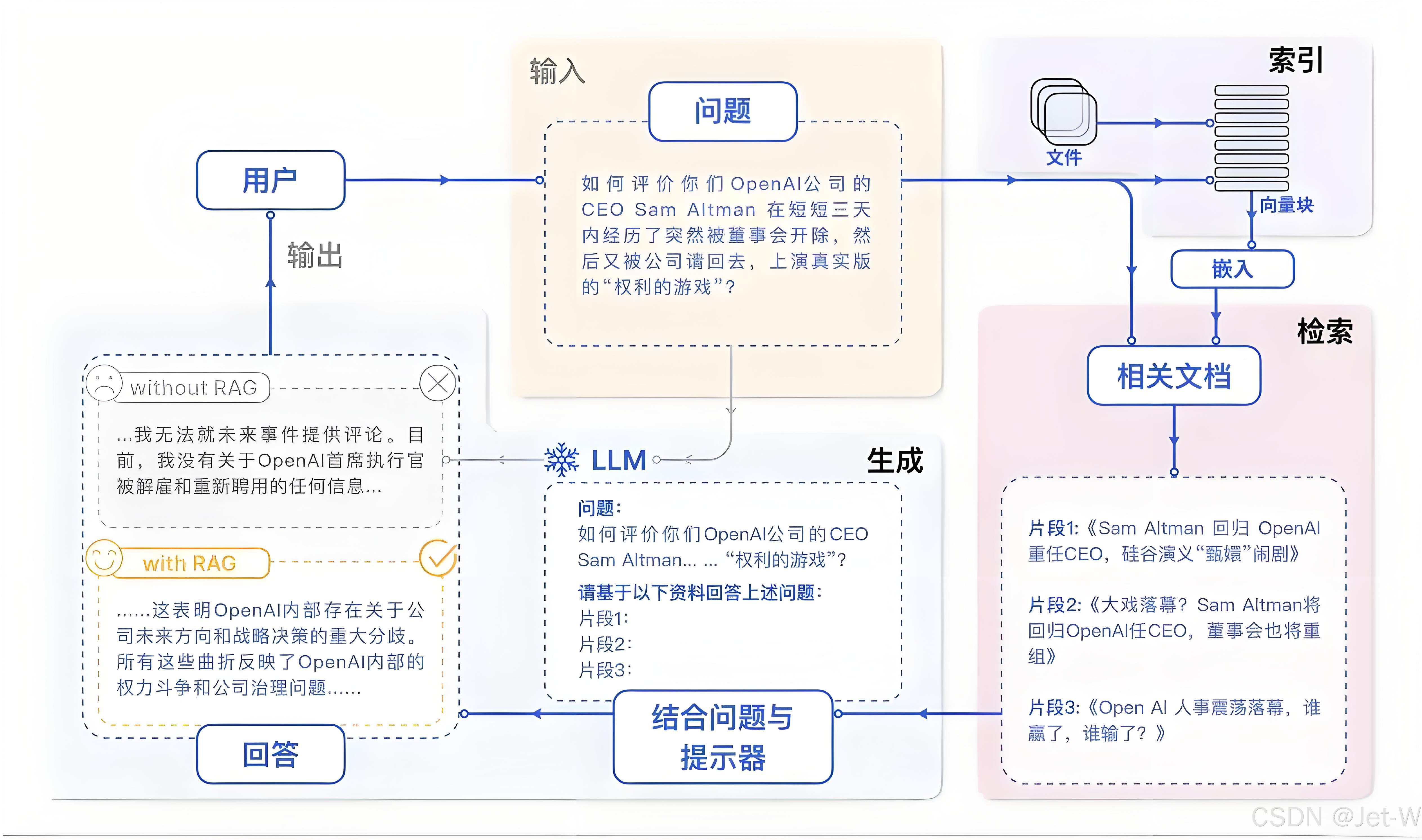
生成器利用检索到的信息片段和原始查询来生成准确、连贯的回答。这通常通过以下方式实现:
- 上下文构建:将检索到的文档与用户查询结合,形成丰富的上下文。
- 文本生成:使用语言模型根据上下文生成回答或补充信息。
RAG技术的优势
提升搜索精准度
RAG技术通过检索最相关的文档,增强了语言模型对用户查询的理解,从而生成更准确的回答。这种精准度的提升对于处理复杂查询尤为重要。
丰富搜索结果
RAG技术能够整合多个相关文档的信息,提供比单一文档更全面的答案。此外,它还能够根据用户的查询动态地检索最新的信息,使得搜索结果更加丰富和多样化。
实时信息整合
RAG技术可以实时地整合最新的信息,确保搜索结果不仅基于模型的训练数据,还能反映最新的数据和趋势。
ES集成RAG增强搜索



















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











