import spark.implicits._爆红
最新推荐文章于 2024-09-25 17:25:14 发布




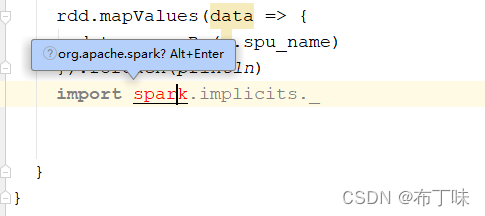
 博客作者在使用Spark时遇到了一个问题,原本以为`spark`是包名,实际上它是一个变量名。通过修正为`session`作为变量名,问题得到了解决。博客主要讨论了SparkSession的配置和正确使用变量名避免编译错误。
博客作者在使用Spark时遇到了一个问题,原本以为`spark`是包名,实际上它是一个变量名。通过修正为`session`作为变量名,问题得到了解决。博客主要讨论了SparkSession的配置和正确使用变量名避免编译错误。
博客作者在使用Spark时遇到了一个问题,原本以为`spark`是包名,实际上它是一个变量名。通过修正为`session`作为变量名,问题得到了解决。博客主要讨论了SparkSession的配置和正确使用变量名避免编译错误。
博客作者在使用Spark时遇到了一个问题,原本以为`spark`是包名,实际上它是一个变量名。通过修正为`session`作为变量名,问题得到了解决。博客主要讨论了SparkSession的配置和正确使用变量名避免编译错误。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























 4971
4971







