




今天我们来讲一讲mysql 的主从集群架构,主要讲三点:(1)主从复制原理;(2)出现主从延迟的可能原因及应对策略;(3)针对已出现的从库延迟,如何实现数据追赶?
一、主从复制原理
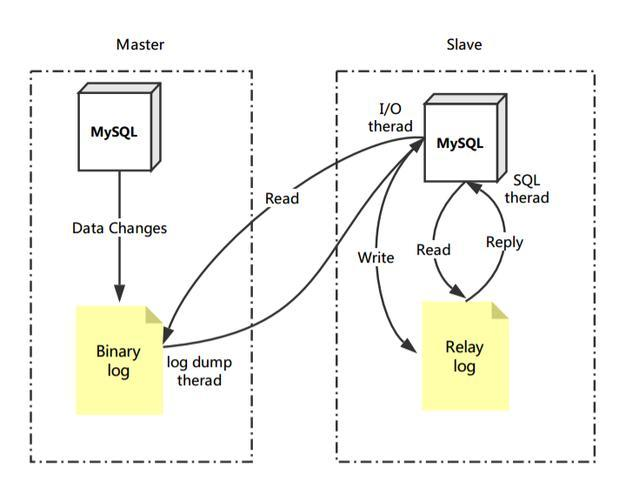
主从复制过程主要有三个线程参与:Master节点的Dump线程、Slave节点的IO线程和SQL线程。
主从复制过程:
(1)首先,Master节点在执行DML操作后,会更新库表数据,并将这些变更记录到Binary Log文件中。
(2)其次,Slave节点会定时检测Master节点的Binary Log文件是否有变化。如果有变化,Slave节点会启动一个IO线程去获取Master节点的Binary Log数据。
(3)同时,Master节点会为每个Slave节点的IO线程启动一个Dump线程。Dump线程会根据Slave节点的请求,将本地的Binary Log以events的方式发送到Slave节点。
(4)Slave节点 接收到数据后先存储进 Relay Log的缓冲区。Slave节点的IO线程接收到这些数据后,并不会直接同步到Slave库中,而是将Binary Log数据保存在一个叫做Relay Log的缓冲区中,以实现解耦和缓冲的目的。
(5)为了避免IO线程阻塞,Slave节点的SQL线程会将Relay Log中的数据同步到Slave库中。
通过这些步骤,MySQL主从复制实现了数据的同步和备份,确保了数据的一致性。
二、 主从延迟问题分析与排查?
主从延迟的本质是:从库的 SQL 线程应用日志(Relay Log)的速度跟不上主库写入 Binlog 的速度。
导致这个问题的原因多种多样,我们可以从以下几个层面进行排查和解决:
第一步:诊断与定位延迟原因
在解决问题之前,先使用以下命令确认延迟状态并初步定位问题:
-
查看延迟时间:
SHOW SLAVE STATUS\G重点关注:
Seconds_Behind_Master: 从库落后主库的秒数。这是最直观的指标。但注意,网络问题可能导致这个值不准确。Relay_Master_Log_File&Exec_Master_Log_Pos: 从库当前正在应用的主库的 Binlog 文件和位置。对比主库SHOW MASTER STATUS;的当前位置,可以计算出实际的延迟量。
-
监控从库服务器性能:
- CPU 使用率: 是否达到瓶颈?
- 磁盘 I/O 使用率(特别是 await 和 util): 这是最常见的瓶颈。从库的 SQL 线程需要频繁读写 Relay Log 和应用数据,如果磁盘慢,应用速度必然跟不上。
- 网络带宽和延迟: 主从之间的网络是否稳定?是否有丢包或高延迟?
-
检查是否有长事务或大事务:
-- 在主库执行,查看当前运行的事务 SELECT * FROM information_schema.innodb_trx;一个在主库运行了很久的事务,在提交时会产生一个很大的 Binlog 事件,从库需要同样长的时间来应用它,在此期间
Seconds_Behind_Master会急剧增大。
第二步:针对性解决方案
根据定位到的原因,选择以下一种或多种方案组合解决。
层面一:硬件与配置优化(解决性能瓶颈)
-
提升从库硬件性能(特别是磁盘I/O):
- 将从库的 Binlog、Relay Log 和数据文件放在不同的物理磁盘(或高性能 SSD)上,减少 I/O 竞争。
- 使用高性能 SSD:这是解决 I/O 瓶颈最有效的手段。
-
优化 MySQL 配置参数:
slave_parallel_workers(MySQL 5.7+) /replica_parallel_workers(MySQL 8.0+): 这是最重要的参数。开启多线程复制,让从库用多个工作线程来应用日志。通常设置为 CPU 核心数的 2-4 倍。slave_parallel_workers = 8slave_parallel_type: 设置为LOGICAL_CLOCK(基于组提交的并行复制),而不是DATABASE(按库并行)。LOGICAL_CLOCK能提供更好的并行度。slave_parallel_type = LOGICAL_CLOCKinnodb_flush_log_at_trx_commit&sync_binlog:- 在主库上,为了数据安全,通常设置为
1(最安全,但性能最差)。 - 在从库上,可以适当牺牲一些安全性来换取性能。例如:
这样从库写入磁盘的频率降低,能显著提升应用日志的速度。即使从库宕机,数据也可以从主库重新同步。innodb_flush_log_at_trx_commit = 2 sync_binlog = 0
- 在主库上,为了数据安全,通常设置为
sync_relay_log,relay_log_recovery: 调整 Relay Log 的刷盘策略,但需谨慎。
层面二:架构与业务优化(减少产生延迟的源头)
-
业务规避大事务:
- 避免一次性删除或更新大量数据(例如
DELETE FROM table WHERE time < '2020-01-01')。可以将其拆分成多个小事务(比如按ID或时间范围分批处理)。 - 大批量数据导入时,使用
LOAD DATA代替INSERT ... VALUES ...。
- 避免一次性删除或更新大量数据(例如
-
使用读写分离中间件:
- 在应用层引入 ShardingSphere、MyCat 或 ProxySQL 等中间件。
- 配置延迟感知的路由:中间件会定期检查从库的
Seconds_Behind_Master。当某个从库延迟过高时,自动将读请求路由到主库或其他延迟低的从库,而不是一直等待延迟的从库返回数据。这是对业务最透明的解决方案。
-
分库分表:
- 如果写压力巨大,单主模式已成为瓶颈,那么主从复制架构本身就无法解决了。需要考虑分库分表,将写压力分散到多个数据库实例上。
-
考虑更高级的架构:
- 如果对数据一致性和高可用要求极高,无法忍受主从延迟,可以考虑迁移到 MySQL Group Replication (MGR)。MGR 使用 Paxos 协议,保证数据在多数节点上同步后才会提交,从根本上避免了异步复制带来的延迟和不一致问题。
层面三:临时操作与监控
-
跳过错误或重置复制(慎用!):
- 如果确定延迟是由于某个特定事务(如误操作)引起的,并且可以接受数据不一致,可以临时跳过该事务。
STOP SLAVE; SET GLOBAL sql_slave_skip_counter = 1; -- 跳过一个事件 START SLAVE;- 警告: 这会导致主从数据不一致,应是万不得已的最后手段。之后需要做数据校验(如 pt-table-checksum)。
-
加强监控与告警:
- 持续监控
Seconds_Behind_Master、从库 I/O 和 SQL 线程状态。 - 设置延迟阈值告警(如延迟超过 5 分钟),以便及时人工介入处理。
- 持续监控
总结与决策流程
面对主从延迟,可以按以下思路排查和解决:
graph TD
A[发现主从延迟] --> B{监控服务器资源};
B -- I/O或CPU瓶颈 --> C[硬件与配置优化:<br>1. 升级SSD<br>2. 调整多线程复制参数<br>3. 优化从库innodb参数];
B -- 资源正常 --> D{检查是否有大事务};
D -- 是 --> E[业务优化:<br>1. 拆分大事务<br>2. 优化SQL];
D -- 否 --> F[架构优化:<br>1. 引入读写分离中间件<br>(延迟感知路由)<br>2. 考虑分库分表或MGR];
C --> G[问题解决?];
E --> G;
F --> G;
G -- 是 --> H[成功];
G -- 否 --> I[重新评估根本原因];
核心要点:
- 先定位瓶颈: 使用监控工具,确定是硬件(I/O)、配置、还是业务(大事务)问题。
- 优先硬件和配置: 升级 SSD 和调整
slave_parallel_workers是性价比最高的方案。 - 其次优化业务: 避免产生大量日志的大事务。
- 最后考虑架构: 通过中间件规避延迟读请求,或者彻底升级到 MGR 这样的强一致性集群。
没有一劳永逸的解决方案,需要根据你的具体业务场景、数据一致性要求和预算来选择和组合上述策略。
三、主从延迟发生后,如何实现数据追赶?
当主从延迟发生后,要“快速”让从库数据与主库一致,需要根据延迟的严重程度和根本原因来选择最合适的策略。
核心原则是:优先尝试让从库“自然追赶”,如果不可行,则采用“重建从库”的方案。 贸然操作可能导致更严重的数据不一致。
以下是详细的决策流程和操作指南:
flowchart TD
A[发现主从延迟] --> B{检查从库状态<br>Seconds_Behind_Master};
B -- 延迟较小(几分钟) --> C[等待从库自然追赶];
B -- 延迟很大或不断增长 --> D{排查原因<br>(IO/SQL线程状态、服务器负载)};
D -- 原因明确且可快速解决<br>(如:大事务) --> E[解决根本问题后等待追赶];
D -- 原因复杂或无法快速解决<br>(如:从库性能瓶颈、数据冲突) --> F{业务是否可接受<br>短暂停止从库服务?};
F -- 是 --> G[方案一:重建从库<br>(最彻底、最安全)];
F -- 否 --> H[方案二:跳过错误事务<br>(高风险、最后手段)];
方案一:彻底重建从库(最安全、最推荐的方法)
这是最可靠、最安全的方法,尤其适用于延迟非常大、从库数据可能已经不一致、或者你需要一个绝对干净的副本的场景。虽然听起来“重建”很慢,但使用现代工具(如 mysqldump 配合 GTID 或 Percona XtraBackup)可以高效完成。
适用场景:
- 延迟非常严重(如几小时甚至几天)。
- 怀疑从库数据已经和主库不一致。
- 从库因为某些错误(如重复键冲突)已经停止了复制。
- 你希望得到一个全新的、无杂质的从库。
操作步骤:
-
停止从库复制:
STOP SLAVE; -
备份主库:
-
方法A(使用 mysqldump - 适用于中小型数据库):
mysqldump --single-transaction --master-data=2 -h [master_ip] -u [user] -p [database_name] > master_backup.sql--single-transaction: 确保在事务中备份,得到一致性快照。--master-data=2: 会在备份文件中以注释的形式记录当前主库的 Binlog 位置,恢复后直接用这个位置启动复制。
-
方法B(使用 Percona XtraBackup - 适用于大型数据库,热备份):
# 在主库或从库上执行,备份主库的数据文件 innobackupex --host=[master_ip] --user=[user] --password=[password] /path/to/backup/这种方式速度更快,对主库影响小,并且备份文件中直接包含
xtrabackup_binlog_info文件,里面记录了复制的位点信息。
-
-
将备份文件恢复到从库:
- 如果使用
mysqldump:mysql -h [slave_ip] -u [user] -p [database_name] < master_backup.sql - 如果使用
XtraBackup,需要先“准备”备份,然后复制文件到从库的 data directory,并修改文件权限。
- 如果使用
-
根据备份文件中的位置信息,重新配置复制通道:
- 查看
master_backup.sql文件开头找到CHANGE MASTER TO命令所需的MASTER_LOG_FILE和MASTER_LOG_POS。 - 或者查看
xtrabackup_binlog_info文件。 - 在从库上执行:
CHANGE MASTER TO MASTER_HOST='[master_ip]', MASTER_USER='[repl_user]', MASTER_PASSWORD='[repl_password]', MASTER_LOG_FILE='[log_file_name_from_backup]', MASTER_LOG_POS=[log_position_from_backup]; START SLAVE;
- 查看
-
验证:
SHOW SLAVE STATUS\G确保
Slave_IO_Running和Slave_SQL_Running都是Yes,且Seconds_Behind_Master变为0。
方案二:跳过错误/事务(高风险,应急手段)
警告:此方法会导致主从数据不一致!除非你100%确定跳过的事务无关紧要,或者你别无选择,否则不要使用。 这通常用于复制因某个特定错误(如重复主键)而中断的情况,而不是单纯的延迟。
适用场景:
- 复制已经因为一个错误而停止(
Slave_SQL_Running: No)。 - 你确认这个错误可以跳过(例如,是一个重复主键,而你可以接受从库缺少这条数据)。
- 你需要立即恢复复制,并且事后会通过重建从库来彻底解决不一致问题。
操作步骤:
-
确认错误:
SHOW SLAVE STATUS\G查看
Last_SQL_Error字段,确认错误信息。 -
跳过错误(传统位点复制模式):
STOP SLAVE; SET GLOBAL sql_slave_skip_counter = 1; -- 跳过一个事件(Event) START SLAVE;- 可能需要多次执行,直到跳过了所有产生错误的事件。
-
跳过错误(更推荐的 GTID 模式):
在 GTID 模式下,不能使用sql_slave_skip_counter,而是需要在从库配置文件中注入一个空事务来“欺骗”复制线程。- 在
SHOW SLAVE STATUS\G的输出中找到Executed_Gtid_Set,记下导致错误的那个 GTID(比如aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:100)。 - 在从库上执行:
STOP SLAVE; SET GTID_NEXT='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:100'; -- 填入要跳过的GTID BEGIN; COMMIT; -- 注入一个空事务 SET GTID_NEXT='AUTOMATIC'; -- 改回自动模式 START SLAVE;
这样从库就会认为这个 GTID 对应的事务已经执行过了,从而继续执行下一个事务。
- 在
重要提醒:跳过事务后,必须记录下跳过了哪些 GTID 或事务,并在后续安排时间重建从库,以确保数据的完整性和一致性。这只是个“创可贴”式的临时解决方案。
总结与建议
| 方法 | 安全性 | 速度 | 适用场景 | 最终一致性 |
|---|---|---|---|---|
| 彻底重建从库 | 非常高 | 取决于数据量,可能较慢 | 几乎所有场景,特别是延迟严重或数据已不一致时 | 保证一致 |
| 跳过错误事务 | 非常低 | 非常快 | 复制因特定错误中断,急需恢复服务的紧急情况 | 会导致不一致 |
最佳实践:
- 首选重建:对于生产环境,只要条件允许(如有另一个从库可以接管读流量),彻底重建从库永远是首选方案,因为它能给你一个干净、一致的数据副本。
- 跳过是最后手段:将“跳过事务”视为一种紧急止血的临时措施,使用后必须计划后续的重建工作。
- 预防优于治疗:解决此次延迟后,一定要复盘原因(是否大事务?从库性能是否不足?),并优化架构和配置(如开启多线程复制
slave_parallel_workers),从根本上减少未来延迟的发生。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









