




 介绍了FPN(Feature Pyramid Network)在目标检测领域的贡献,包括其如何通过结合多层特征来提高检测精度,特别是在小目标检测方面的能力。文章详细阐述了FPN的主要结构、应用场景及其实现步骤。
介绍了FPN(Feature Pyramid Network)在目标检测领域的贡献,包括其如何通过结合多层特征来提高检测精度,特别是在小目标检测方面的能力。文章详细阐述了FPN的主要结构、应用场景及其实现步骤。

FPN 是清华大学学生linyi在FAIR时发表的,是目标检测领域值得一看的论文,这次学习做个记录。
背景
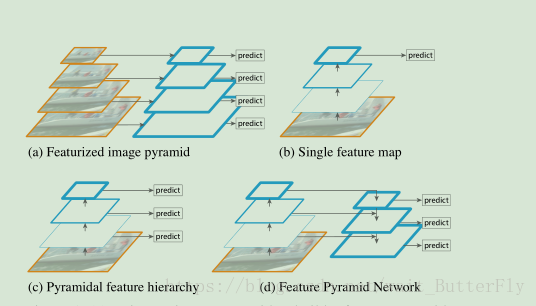
作者以这张图讲述了以往对feature map的处理:
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
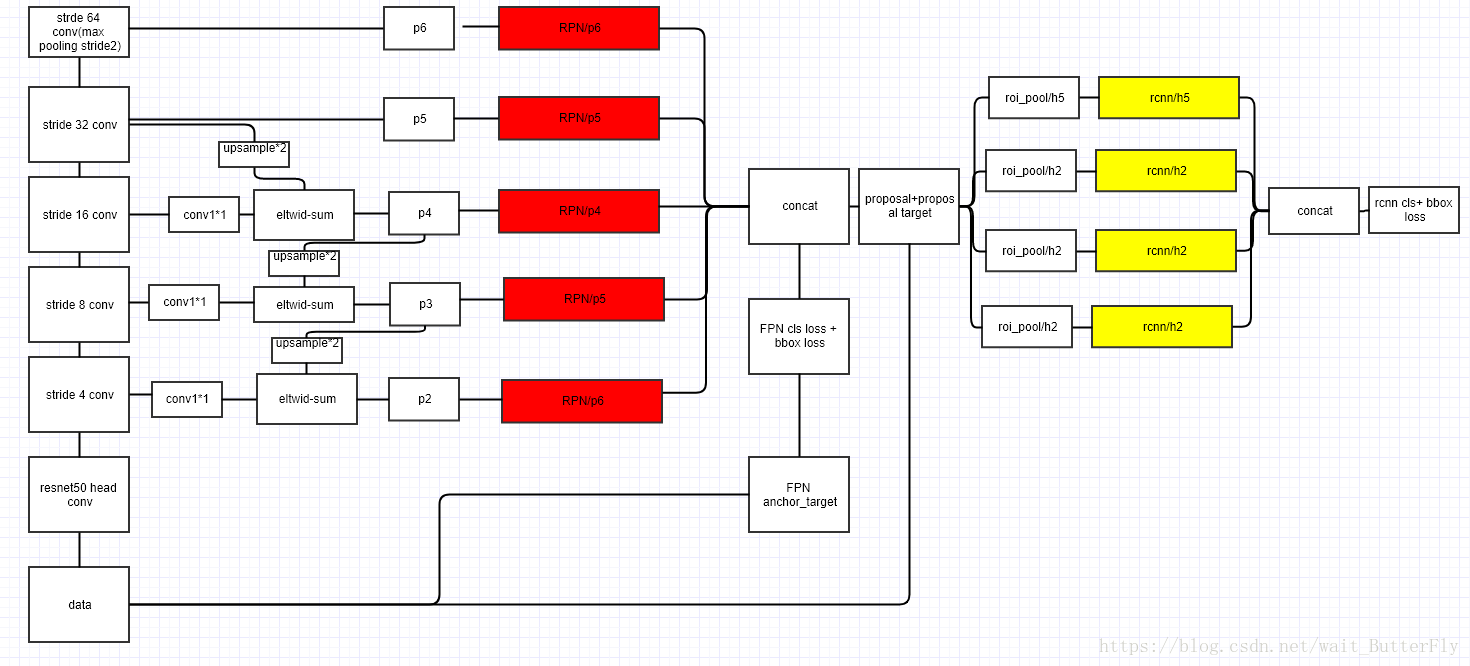
主要结构
bottom-up pathway:网络的前向过程,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
top-down pathway and lateral connections:upsampling
而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
应用
将FPN放在RPN网络中用于生成proposal,原来的RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为32^2,64^2,128^2,256^2,512^2,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
步骤
1.图片预处理
2.resnet 构建bottom-up网络
3.top-down 上采样
4.rpn操作
5.roi在p上roi pooling
6fc+分类和回归
小目标处理
- FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息);
- 对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息
总结
- FPN 构架了一个可以进行端到端训练的特征金字塔;
- 通过CNN网络的层次结构高效的进行强特征计算;
- 通过结合bottom-up与top-down方法获得较强的语义特征,提高目标检测和实例分割在多个数据集上面的性能表现;
- FPN这种架构可以灵活地应用在不同地任务中去,包括目标检测、实例分割等;
参考blog:
https://blog.youkuaiyun.com/WZZ18191171661/article/details/79494534
https://blog.youkuaiyun.com/App_12062011/article/details/77947444

















 3447
3447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









