



 这篇博客介绍了如何分析海伦收集的约会数据,包括每年飞行常客里程数、视频游戏时间百分比和每周冰淇淋消费量。通过数据读取、处理,最终使用散点图进行数据可视化,展示不同特征之间的关系,帮助理解样本数据的分类标签:不喜欢的人、魅力一般的人和极具魅力的人。
这篇博客介绍了如何分析海伦收集的约会数据,包括每年飞行常客里程数、视频游戏时间百分比和每周冰淇淋消费量。通过数据读取、处理,最终使用散点图进行数据可视化,展示不同特征之间的关系,帮助理解样本数据的分类标签:不喜欢的人、魅力一般的人和极具魅力的人。
实验步骤:【绘制散点图】- 概述
import numpy as np
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
数据介绍
import KNN
group,labels=KNN.createDataSet()
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。
海伦收集的样本数据主要包含以下3种特征:
- 每年获得的飞行常客里程数 (Number of frequent flyer miles earned per year)
- 玩视频游戏所消耗时间百分比 (Percentage of time spent playing video games)
- 每周消费的冰淇淋公升数 (Liters of ice cream consumed per week)
数据标签包含以下3类:
- 不喜欢的人 (didntLike)
- 魅力一般的人 (smallDoses)
- 极具魅力的人 (largeDoses)
数据示例
实验步骤:【绘制散点图】- 数据读取与处理
将数据分类两部分,即特征矩阵和对应的分类标签向量。定义名为file2matrix的函数,以此来处理输入格式问题。编写代码如下:
def file2matrix(filename):
"""
函数说明:加载数据集
parameters:
fileName - 文件名
return:
featureMat - 特征矩阵
classLabelVector - 类别标签向量(didntLike - 0, smallDoses - 1, largeDoses - 2)
"""
fi = open(filename)
list1=fi.readlines()
len1=len(list1)
matrix1=np.zeros((len1,3))
label1=[]
index=0
for line in list1:
line=line.strip()
listfromline=line.split('\t')
matrix1[index,:]=listfromline[0:3]
#label1.append(0.01*ord(listfromline[-1][0]))
if(listfromline[-1]=="didntLike"):
label1.append(1) #不能为0 ,如果为0后面color显示不出来
elif(listfromline[-1]=="smallDoses"):
label1.append(2)
else :
label1.append(3)
index+=1
return matrix1,label1
pass
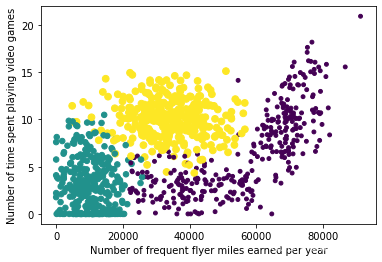
实验步骤:【绘制散点图】- 分析数据数据可视化
ax=fig.add_subplot(111)表示把图像区域分成1X1个子图,ax为第1个子图。
def showdatas(datingDataMat, datingLabels):
"""
函数说明:绘制散点图
parameters:
datingDataMat - 特征矩阵
datingLabels - 类别标签向量(didntLike - 1, smallDoses - 2, largeDoses - 3)
"""
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],s=15.0*np.array(datingLabels),
c=25*np.array(datingLabels))
ax.set_xlabel("Number of frequent flyer miles earned per year")
ax.set_ylabel("Number of time spent playing video games")
pass
可视化结果
if __name__ == '__main__':
filename = "kNN_Dating/datingTestSet.txt"
datingDataMat, datingLabels = file2matrix(filename)
showdatas(datingDataMat, datingLabels)

















 2758
2758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









