






 本文介绍了Python爬虫的基础知识,包括使用urllib2库抓取网页,Request对象的使用,模拟POST和GET登录,设置Header,处理Proxy代理,设置响应时间以及异常处理和Cookie的使用。通过实例代码详细讲解了每个知识点。
本文介绍了Python爬虫的基础知识,包括使用urllib2库抓取网页,Request对象的使用,模拟POST和GET登录,设置Header,处理Proxy代理,设置响应时间以及异常处理和Cookie的使用。通过实例代码详细讲解了每个知识点。
1.urlib2库的基本使用
import urllib2
#获取网页 调用的是 urllib2 库里面的 urlopen 方法,传入一个 URL,这个网址是百度首页
#urlopen一般接受三个参数,urlopen(url, data, timeout)
#url 即为网址,data 是访问时要传送的数据,timeout设置超时时间
# data,timeout是可以不写的,data 默认为 None,timeout 默认为 socket
response = urllib2.urlopen("http://www.baidu.com")
#输出网页 response 对象有一个 read 方法,可以获取网页内容。
print( response.read())
2,Request
import urllib2
#urlopen 可以传入一个 request 请求,构造时需要传入 Url,Data 等;
request = urllib2.Request("http://www.baidu.com")
response = urllib2.urlopen(request)
print (response.read())
3.post模拟登陆
import urllib
import urllib2
#定义一个字典,名字为 values,参数设置 username 和 password(帐号,密码)
values = {"username":"134567@qq.com","password":"1234"}
#用 urllib 的 urlencode 方法将字典编码
data = urllib.urlencode(values)
#定义url
url = "https://passport.youkuaiyun.com/account/login?from=http://my.youkuaiyun.com/my/mycsdn"
#传入url和data
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
#第二种写法
values = {}
values['username'] = "1234567891@qq.com"
values['password'] = "1234"
data = urllib.urlencode(values)
url = "http://passport.youkuaiyun.com/account/login?from=http://my.youkuaiyun.com/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
4.get模拟登录
import urllib
import urllib2
values={}
values['username'] = "1234567891@qq.com"
values['password']="123"
data = urllib.urlencode(values)
url = "http://passport.youkuaiyun.com/account/login"
#实际上直接将网址和data拼接
#geturl的内容如下所示
# http://passport.youkuaiyun.com/account/login?username=1016903103%40qq.com&password=1231234567891http://passport.youkuaiyun.com/account/login?username=1016903103%40qq.com&password=123
geturl = url + "?"+data
request = urllib2.Request(geturl)
response = urllib2.urlopen(request)
print response.read()
5.Header
#服务器若识别了是浏览器发来的请求,就会得到响应
import urllib
import urllib2
url = 'http://www.server.com/login'
#设置服务器
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
values = {'username' : 'cqc', 'password' : 'XXXX' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
request = urllib2.Request(url, data, headers)
response = urllib2.urlopen(request)
page = response.read()
6.Proxy代理
#网站它会检测某一段时间某个 IP 的访问次数,如果访问次数过多,它会禁止你的访问。
#所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理
import urllib2
enable_proxy = True
proxy_handler = urllib2.ProxyHandler({"http" : 'http://some-proxy.com:8080'})
null_proxy_handler = urllib2.ProxyHandler({})
if enable_proxy:
opener = urllib2.build_opener(proxy_handler)
else:
opener = urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
7.响应时间(Timeout)设置
import urllib2
response = urllib2.urlopen('http://www.baidu.com', timeout=10)
import urllib2
response = urllib2.urlopen('http://www.baidu.com',data, 10)
8.异常处理
try:
fh = open("testfile", "w")
fh.write("测试异常")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "成功"
fh.close()
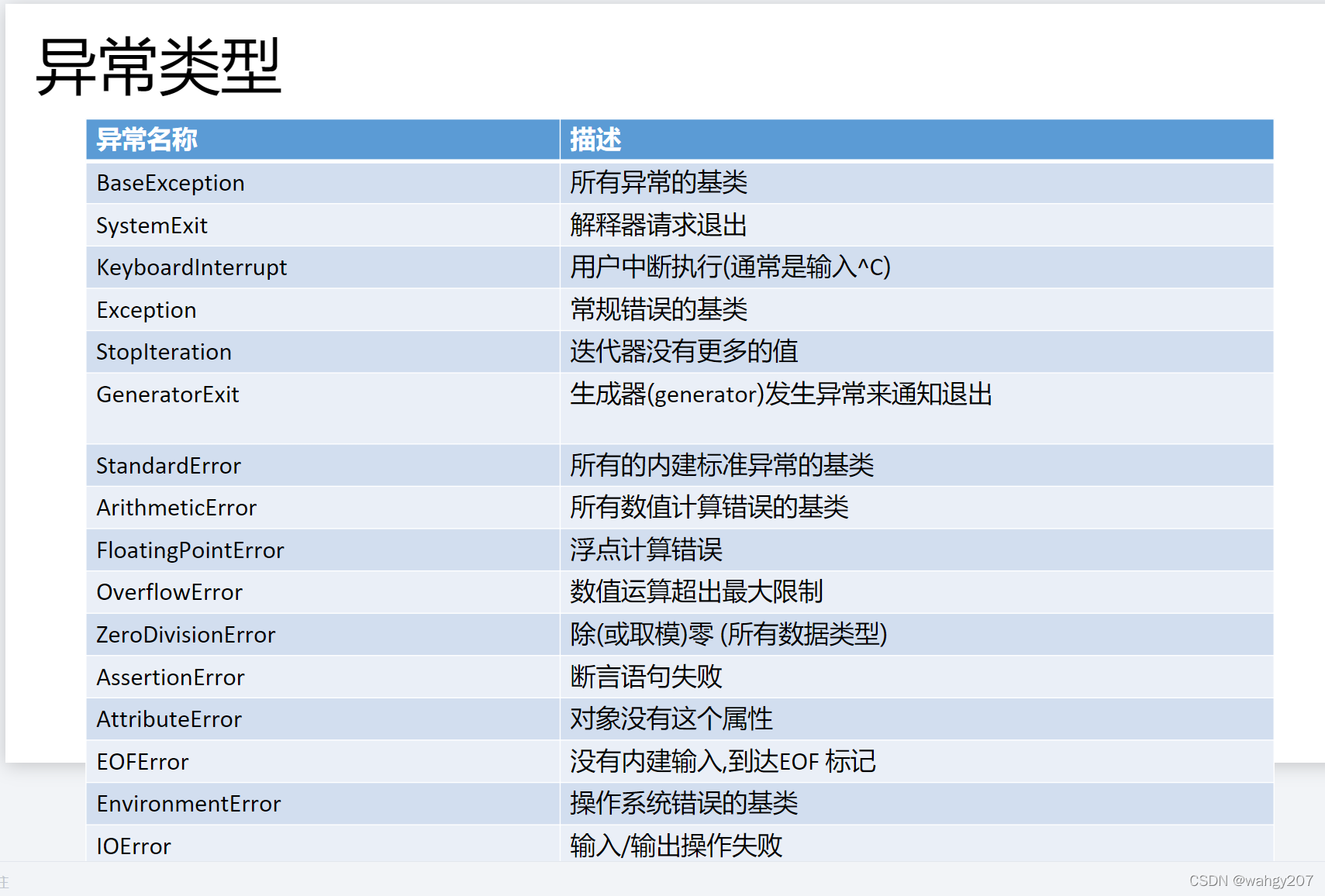
9.cookie的使用
#Cookie指某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据,如部分网站的帐号密码记忆。
#用 CookieJar 对象实现获取 cookie 的功能,存储到变量中
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
# 此cookie 中的值:
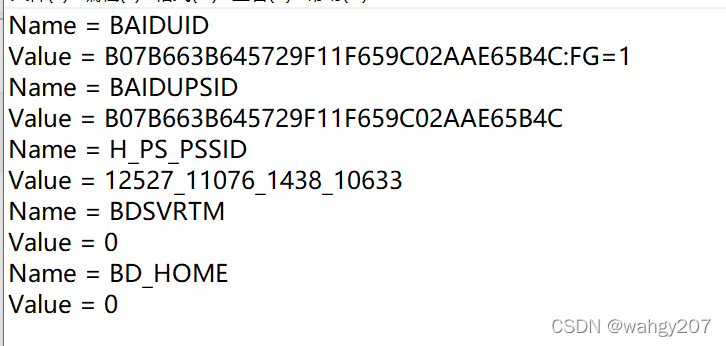
#将 cookie 保存到文件
import cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
#从文件中获取 Cookie
import cookielib
import urllib2
#创建MozillaCookieJar实例对象
cookie = cookielib.MozillaCookieJar()
#从文件中读取cookie内容到变量
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
#创建请求的request
req = urllib2.Request("http://www.baidu.com")
#利用urllib2的build_opener方法创建一个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open(req)
print response.read()

















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









