




搭建Hadoop平台
1. 安装Hadoop和JDK
-
首先大家要有Hadoop的Linux版本和JDK1.8,可以在官方网站上下载
-
下载完成后解压到指定的位置
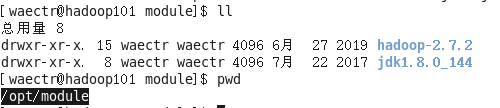
-
在这里首先清除之前系统自带的JDK,这里我使用的是
sudo yum -y remove java
- 然后就是配置JDK和Hadoop的系统配置
sudo vi /etc/profile
## 详细的配置如下所示
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 然后让配置文件生效
source /etc/profile
2. 准备三个虚拟机
假设我们之前已经配置好一台虚拟机,此时我们将它克隆三个
- 克隆好三台虚拟机后,我们首先要进行网络配置
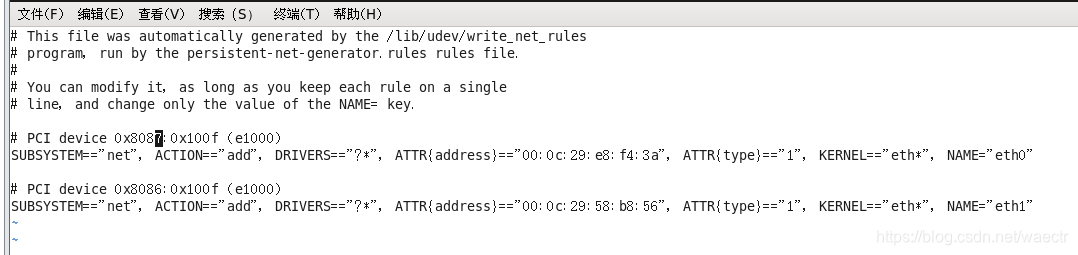
vim /etc/udev/rules.d/70-persistent-net.rules
进入后就是个样子,然后我们把上面的 ‘eth0’那行删掉,把下面‘eth1’改为‘eth0’,并且复制记下ATTR{address}列
- 设置IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
进入后,将刚才复制的ATTR{address}粘贴到HWADDR,设置对应的IPADDR
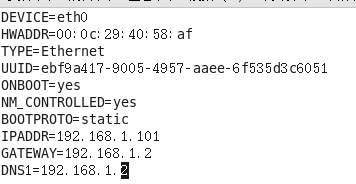
DEVICE(接口名,默认eth0)
HWADDR(MA 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









