







abstract
1. Introduction
vehicle re-ID suffers from much smaller inter-class variations and larger intra-class variations.
引入具有两个流的外观模块,开发了一种用于描述多粒度视觉信息的区分特征表示。粗粒度特征流从全局网络中提取深层特征,呈现图像的宏观特征。此外,细粒度特征流将同一类的样本拉到一起,同时将不同类的样本推到特征embedding空间中。
提出了一个时空模块,以获得更鲁棒的车辆识别模型。通过将摄像机位置的距离和时间戳的差异建模为随机变量,我们以一种简单而有效的方式定量地描述了时空关系。通过添加时空模块,我们观察到明显的性能改进。
DFR-ST:
1.双流设计,提取粗粒度+细粒度,结合注意力机制+分割操作,驱动细粒度的视觉表征集中在更突出和更有信息的区域。
2.空间-时间模块被提出来建立空间距离和时间间隔的定量描述,通过考虑多模态线索,与视觉外观形成互补的表示。
3.Methodology
3.1系统架构
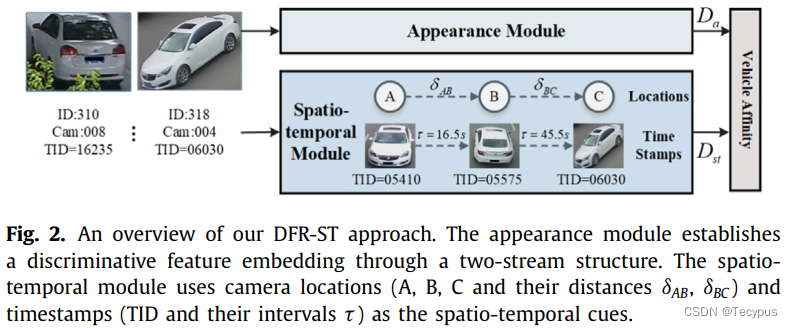
图二说明了 DFT-ST的框架,Aappearance模块负责对视觉特征进行建模,其中输入的图像送入一个骨干网络,然后是两个steam,粗粒度特征流和细粒度特征流。如图三。
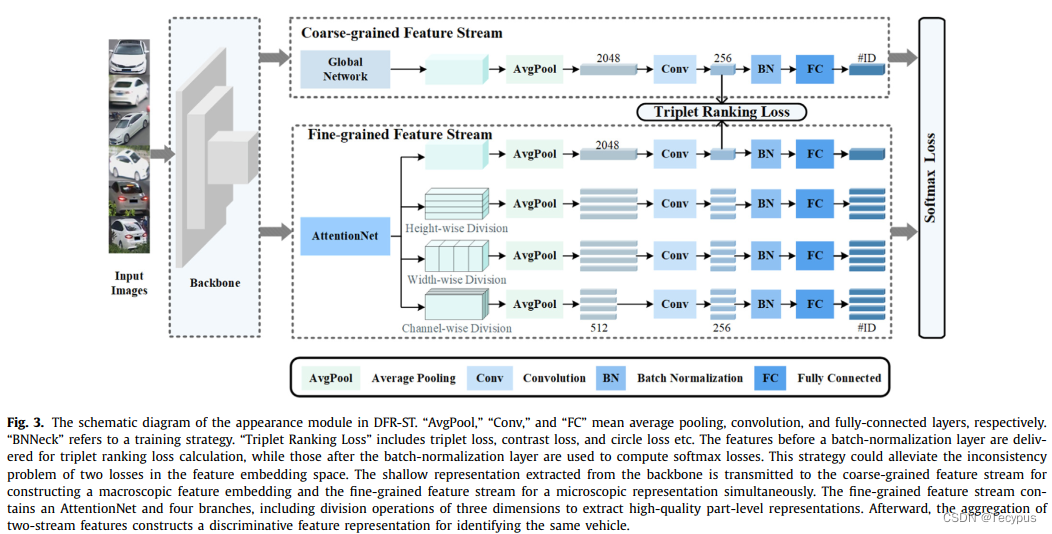
DFR-ST中外观模块的示意图。“AvgPool”、“Conv”和“FC”分别表示平均池、卷积和完全连接层。
“BNNeck”指的是一种训练策略。“Triplet Ranking 损失”包括triplet loss、contrast loss, and circle loss等。批量归一化层之前的特征用于计算三重排序损失,而批量归一化层之后的特征则用于计算softmax损失。该策略可以缓解特征嵌入空间中两个损失的不一致性问题。从backbone提取的浅层表示被传输到粗粒度特征流,用于同时构造宏观特征嵌入和细粒度特征流,以用于微观表示。细粒度特征流包含一个AttentionNet和四个分支,包括提取高high-quality part-level representations
的三维划分操作。然后,两个流特征的聚合构造了用于识别同一车辆的区分特征表示
粗粒度特征流提取一般特征表示![]() ,细粒度特征流中
,细粒度特征流中![]() 来补充局部区域和突出部分。
来补充局部区域和突出部分。
同时,空间-时间模块建立空间和时间距离,为识别同一车辆提供额外的信息。最后,结合视觉和时空表征来衡量车辆图像的相似性,进行图库图像的排名列表。
Aappearance模块由一个粗粒度的特征流和一个细粒度的特征流组成。Coarse 粗粒度特征流提取一般特征表示![]() 来处理类间和类内变化的复杂关系。这个流 试图扩大在特征编码空间中具有不同身份的样本的距离。
来处理类间和类内变化的复杂关系。这个流 试图扩大在特征编码空间中具有不同身份的样本的距离。
然而,由于只有一般特征,特别是处理只有轻微差异的图像,如私人装饰、不规则划痕和品牌,对输入图像的细节差异的处理可能会失败。因此,![]() 被来自细粒度特征流的
被来自细粒度特征流的![]() 补充到局部区域和突出部分。
补充到局部区域和突出部分。
此外,我们提出了一个空间-时间模块来利用额外的细枝末节,考虑到在不受约束的环境中具有复杂变化的图像会降低实际场景中的视觉外观效果。特别是,我们将摄像机的位置和时间戳信息作为时空线索,由于安全视频系统的普遍存在,这些信息通常很容易获得。因此,视觉外观表示和时空线索的合作增强了最终的车辆再识别性能。
3.2. Appearance module
3.2.1. Coarse-grained feature stream
粗粒度的特征流提取输入图像的宏观描述。从骨干网获得的特征被输送到粗粒度特征流进行进一步处理。两个残余块被先后放置为全局网络,然后进行平均池化操作和1×1卷积操作。为了提升整体性能,我们采用了BNNeck策略[36],以缓解特征嵌入空间中的Triplet损失和ID损失的不一致问题。
此外,最后一个卷积层中下采样操作的步长为1,以保持更多的深层信息。
3.2.2. Fine-grained feature stream
与粗粒度流相反,细粒度的特征流捕捉到了局部区域的微观特征,特别是具有挑战性的近乎重复的车辆。AttentionNet接收backbone网络特征以构建注意力特征表征,随后有四个分支进行进一步处理。
第一个分支考虑为不同的局部区域分配合理的权重。其余三个分支沿三个维度对特征进行分割,即高度分割、宽度分割和通道分割操作。
用于人物重新识别的高度划分策略[26,37]启发了我们的划分策略。然而,与人体的垂直分区不同,一辆车在垂直和水平维度上都有语义分区。具体来说,车辆在垂直维度上包括车顶、车窗、保险杠、车牌、底盘,在水平维度上包括后视镜、车门、主体。因此,我们设计了高度和宽度的划分分支。同时,卷积层中的filters产生通道信息。虽然输入是相同的,但它们独立学习它们的参数。通道分割的局部特征与全局特征不同,补充了宽度分割和高度分割的特征图。
因此,我们设计通道划分是因为不同的通道携带独立的语义信息。
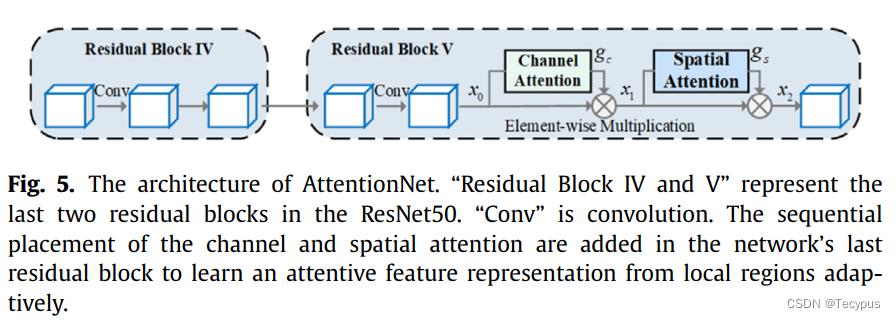
AttentionNet的结构如图5所示。特征![]() 首先用channel-domain attention 处理,学习到通道特征图
首先用channel-domain attention 处理,学习到通道特征图![]() ,然后进行spatial-domain attention处理 用可学习的注意力图
,然后进行spatial-domain attention处理 用可学习的注意力图![]() 。C、H、W表示X0的通道、高度和宽度尺寸。上述程序为
。C、H、W表示X0的通道、高度和宽度尺寸。上述程序为![]()
![]() 。具体来说,X1和X2表示 经过channel和spatial attention后的输出特征,i, j, k为 通道,高和宽的维读索引。
。具体来说,X1和X2表示 经过channel和spatial attention后的输出特征,i, j, k为 通道,高和宽的维读索引。
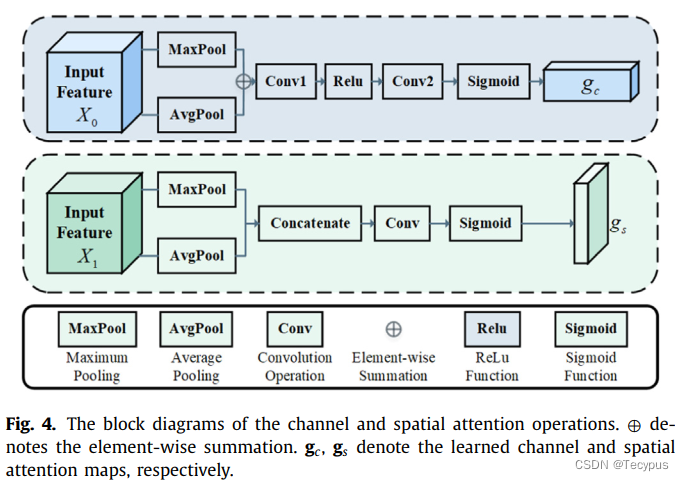
图四 channel attention和 spatial attention的设计结构,定义变换![]() 。输入特征X0首先传入squeeze操作,包括一个GAP和一个MAX POOLING。上述为:
。输入特征X0首先传入squeeze操作,包括一个GAP和一个MAX POOLING。上述为:
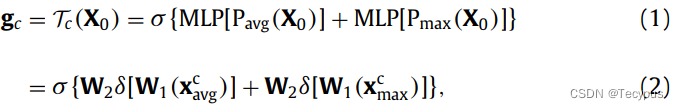
其中,![]() ,
,![]()
![]() 。
。![]() 为sigmoid,
为sigmoid,![]() 代表ReLU,MLP为带有一个隐藏层的多层感知机。
代表ReLU,MLP为带有一个隐藏层的多层感知机。![]() 是平均池化和最大池化,
是平均池化和最大池化,![]() 是MLP卷积层的权重,reduction ratio K的值为16。
是MLP卷积层的权重,reduction ratio K的值为16。![]() 是X0经过平均池化和最大池化的结果。
是X0经过平均池化和最大池化的结果。
空间注意力集中在突出部分的位置信息上,定义变换:![]() 。通过通道维度,用AP和MP处理X1,此外,pool后的特征图经过concat,然后经过一个单个的卷积层,再接一个sigmoid。
。通过通道维度,用AP和MP处理X1,此外,pool后的特征图经过concat,然后经过一个单个的卷积层,再接一个sigmoid。
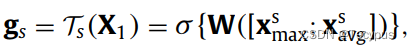
![]() ,
,![]()
![]() 。
。 ![]() 为sigmoid。W 为卷积层的权重,
为sigmoid。W 为卷积层的权重,![]()
![]() 代表通道轴 上的最大池化+平均池化的 输出feature。
代表通道轴 上的最大池化+平均池化的 输出feature。
提出的注意网络与其他注意网络的区别在于:(1)我们建立了一个通道式注意模块,以建立更具针对性的注意,而不是VAMI[24]和MSTA[27]中的空间注意;(2) 在车辆重新识别的实验中,我们发现通道和空间域中的顺序注意子模块优于PAN中的并行顺序
3.2.3. Object function 目标函数
总损失是交叉熵损失和Triplt损失的加权和。具有N个图像的批次的loss被写为:![]()
其中 Lce 是CE交叉熵损失,Ltri是采用批量硬采样策略的Triplt损失。λ是weitht超参数。
标签平滑策略(label smoothing)[38]与交叉熵损失一起使用,以缓解过拟合问题。因此,交叉熵损失![]() 其中
其中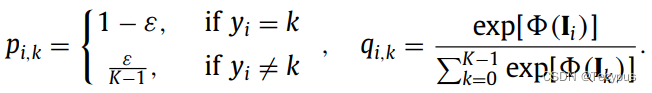
![]() 是batch中一个图片的索引,
是batch中一个图片的索引,![]() 是K 类的索引。
是K 类的索引。![]() 表示经过label smoothing后的分布,Yi 是第i个图像Ii的GT label。超参数
表示经过label smoothing后的分布,Yi 是第i个图像Ii的GT label。超参数![]() 是权重因子。Qi,k 是Ii到第K类的网络预测概率。
是权重因子。Qi,k 是Ii到第K类的网络预测概率。![]() 表示 appearance模块的变换。
表示 appearance模块的变换。
此外,Triplet loss ![]()
![]() 。
。![]() 分别表示 anchor 的feature,正样本和负样本的特征。
分别表示 anchor 的feature,正样本和负样本的特征。![]() 表示 hinge 函数,m控制正样本和负样本到 anchor 的距离。
表示 hinge 函数,m控制正样本和负样本到 anchor 的距离。
3.2.4. Backbone
主干网络建立了视觉外观的浅层表示。在提出的DFR-ST中,主干网采用了ResNet-50网络的前三个块,因为其灵活的架构和优越的性能。如图3所示,我们在前三个剩余块之后复制后续卷积层,以将ResNet-50网络分割为两个特征分支。为深度学习设计的不同卷积网络架构也可以相应地调整为主干。
3.3. Spatio-temporal module
在实际应用中,在存在复杂背景和严重遮挡的噪声时,外观模型不足以构造区分表示。
同时,城市监控和智能交通系统中的摄像机位置和时间戳信息可以提供车辆属性的额外内容。因此,我们设计了一个时空模块如下。
空间距离定义为摄像机对在world坐标中的real-world距离。时间距离定义为时间间隔![]() 在摄像机对(c1,c2)之间,其中tc1,tc2是该车辆在摄像机c1和c2处的出现时间。基本假设是,空间或时间距离较小的两个图像具有更高的可能性,根据Liu等人的观察,具有相同的身份。[10] 反之亦然。根据该假设,我们提出了一种新的时空测量,其中来自摄像机ci的query图像i和来自摄像机Cj的gallery图像j之间的空间相似度Ds和时间相似度Dt如下:
在摄像机对(c1,c2)之间,其中tc1,tc2是该车辆在摄像机c1和c2处的出现时间。基本假设是,空间或时间距离较小的两个图像具有更高的可能性,根据Liu等人的观察,具有相同的身份。[10] 反之亦然。根据该假设,我们提出了一种新的时空测量,其中来自摄像机ci的query图像i和来自摄像机Cj的gallery图像j之间的空间相似度Ds和时间相似度Dt如下:
![]()
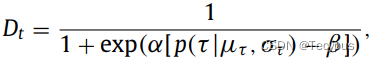
其中![]() 表示摄像机ci和Cj之间的Google地图上的最短距离。
表示摄像机ci和Cj之间的Google地图上的最短距离。![]() 是i和j之间时间戳的差异。超参数α和β表示较高的概率对应于较小的时空距离。
是i和j之间时间戳的差异。超参数α和β表示较高的概率对应于较小的时空距离。![]() 用参数(μδ,σδ)和(μτ,στ)描述δ和τ的条件概率估计,这些参数建模为对数正态分布:
用参数(μδ,σδ)和(μτ,στ)描述δ和τ的条件概率估计,这些参数建模为对数正态分布:
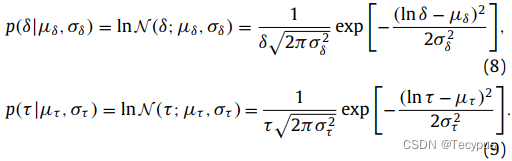
请注意,δ和τ的假设是独立的且同等分布的。通过最大化似然估计分布的参数(μδ,σδ)和(μτ,στ):
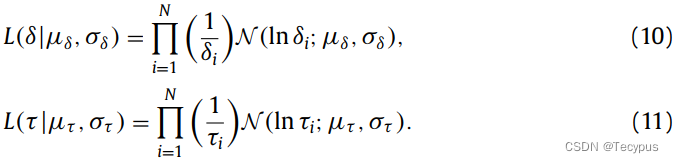
其中,N是gallery中的图像数目
通过这种方式,我们建立了时空模块,为车辆re-ID提供了额外的细化。在现有的时空模型[10,13,18–20]中,最相似的时空模型是[13]。与Wang等人[13]不同,他们考虑了车辆的过渡时间间隔,但没有对空间信息建模,我们的DFR-ST同时涉及时间和空间线索。因此,我们可以明确地获得时空关系的定量公式,以提高整体性能。
查询图像i和画廊图像j之间的总体相似度计算为:![]()
ω是加权参数。![]() 分别模拟了i和j之间的空间和时间相似性。最后,通过Da和Dst的加权和来进行所提出的DFR-ST的排名。(这里的Da是啥?经过appearance模块的什么东西)
分别模拟了i和j之间的空间和时间相似性。最后,通过Da和Dst的加权和来进行所提出的DFR-ST的排名。(这里的Da是啥?经过appearance模块的什么东西)
4. Experiments
4.2. Implementation details
用于浅层特征提取的主干网络采用ResNet-50[49]。在粗粒度特征流中,在三个残差块之后采用平均池化操作,然后是1×1卷积层。等式(4)中的λ设置为0.4,交叉熵损失中的ε设置为1.1。三重态损失中的m设置为1.2。此外,等式(6)和等式(7)中的参数α1和α2设置为6,而β1和β2设置为0.5。等式(12)中的加权参数ω为0.2。
对于训练过程,我们应用了具有权重衰减5e的adam优化器−4和同步批量归一化策略。初始学习率为1e−其通过预热策略进行调整。此外,我们利用欧几里得距离来计算训练和测试期间查询和图库图像之间的相似性。批量大小为32,有8个随机选择的身份和每个身份的4个图像。我们在两个Nvidia GeForce GTX 1080 Ti GPU上训练DFR-ST的外观模块135个周期。整个DFR-ST在PyTorch平台上实现。此外,我们的工作采用了重新排序策略[50],以进一步提高性能。
理解与总结:
需要摄像机位置和时间戳信息,这些需要 城市监控和智能交通系统 等提供。
引入空间信息和时间信息。
两个modul,一个appearance,一个时空信息。
1.appearance上针对粗粒度和细粒度。
1)粗粒度单纯的标准的一套流程。
2)细粒度先经注意力图(channel,然后spatial)对应图四蓝绿,不知道 attention在哪,只是一套神经网络模块。
然后进入四个小分支,第一个分支什么都不动,一套流程走过去。剩下三个 对宽高channel 分割。宽高是因为 垂直和水平都有语义信息。设计channel分割,以为通道也有不同的语义信息。
2.时空模块,对时空信息建模,以得到定量表达公式,从而计算得到一个 排名列表,用于?得到 Q和gallery的关系



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











