




 本文介绍了Hive作为数据仓库工具的基本概念,包括其在Hadoop生态中的位置、架构组成及如何通过提供类似SQL的查询语言简化数据分析流程。此外还探讨了Hive的特点、适用场景及其在处理大规模结构化数据方面的优势。
本文介绍了Hive作为数据仓库工具的基本概念,包括其在Hadoop生态中的位置、架构组成及如何通过提供类似SQL的查询语言简化数据分析流程。此外还探讨了Hive的特点、适用场景及其在处理大规模结构化数据方面的优势。
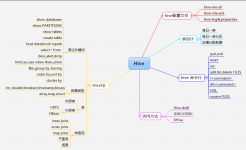
hive 是什么
-
Mapreduce 的编程的不变形,没有固定的格式
-
数据分析
-
是一个数据仓库的工具
-
ETL 数据的转换和提前
-
解决海量结构化日志的数据统计
-
构建在hadoop 之上,将结构化的数据文件映射成一张表,并提供SQL 查询功能
HIVE 特性
-
处理的数据存在HDFS
-
分析数据底层实现在MAPREDUCE
-
执行程序运行的YARN
HIVE在生态系统的位置
HIVE的架构
- 用户Client
- 元数据metastore(存储在mysql)
- hadoop
- 驱动器(HQL转换为mapreduce)
hive的优点和使用场景
-
优点
- 提供类SQL
- 避免去写mapreduce
- 统一元数据管理
- 易扩展,支持自定义函数
-
使用场景
- 数据离线处理,日志分析,海量结构化的数据分析
- hive 对实时性要求不高,延迟比较高
- hive 的优势在于处理大数据,对数据小的没有优势
hive知识结构
参考地址
-
http://www.cnblogs.com/tgzhu/p/5759610.html
-
http://www.aboutyun.com/thread-21544-1-1.html

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









