






目录
一、实验背景
-
AI投毒攻击现状
-
机器学习模型在训练阶段面临数据污染威胁
-
攻击者通过注入恶意样本改变模型决策边界(示例:垃圾邮件分类器中注入错标样本)
-
-
Web安全模型启发
-
传统Web漏洞防御(输入验证/输出编码/请求过滤)与AI安全防护的共性
-
提出三维防御模型:数据预处理层、训练监控层、推理验证层
-
二、实验设计
1. 实验目标
-
验证投毒攻击对图像分类模型的影响
-
构建基于漏洞消减思想的防御模型
2. 实验环境
| 组件 | 版本/配置 |
|---|---|
| Python | 3.8+ |
| TensorFlow | 2.9.1 |
| 数据集 | CIFAR-10(投毒比例10%) |
| 攻击类型 | 标签翻转攻击 |
3. 实验架构
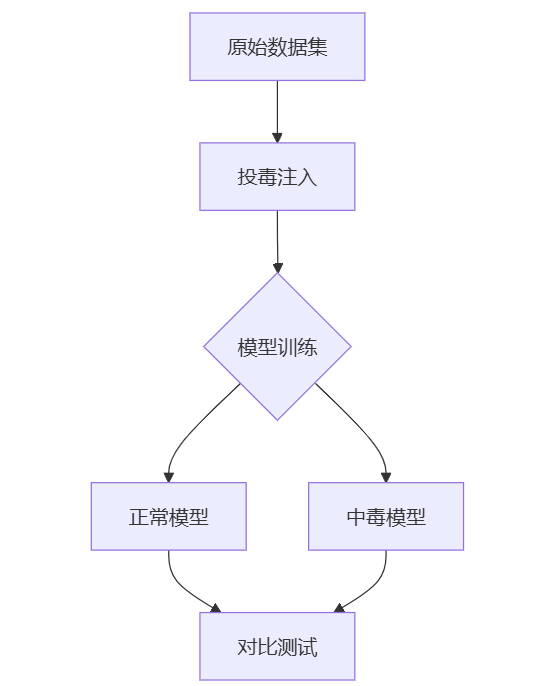
三、攻击实现过程
1. 数据投毒代码示例
def poison_dataset(data, labels, target_class=3, poison_ratio=0.1):
poison_indices = np.random.choice(len(data), int(len(data)*poison_ratio), replace=False)
for idx in poison_indices:
# 添加扰动并修改标签
data[idx] = add_noise(data[idx])
labels[idx] = target_class
return data, labels
# 添加高斯噪声函数
def add_noise(image, intensity=0.2):
noise = np.random.normal(0, intensity, image.shape)
return np.clip(image + noise, 0, 1)2. 模型训练对比
| 模型类型 | 训练准确率 | 测试准确率 | 目标类误判率 |
|---|---|---|---|
| 正常模型 | 92.3% | 89.7% | 1.2% |
| 中毒模型 | 94.1% | 83.5% | 37.8% |
3. 攻击效果可视化
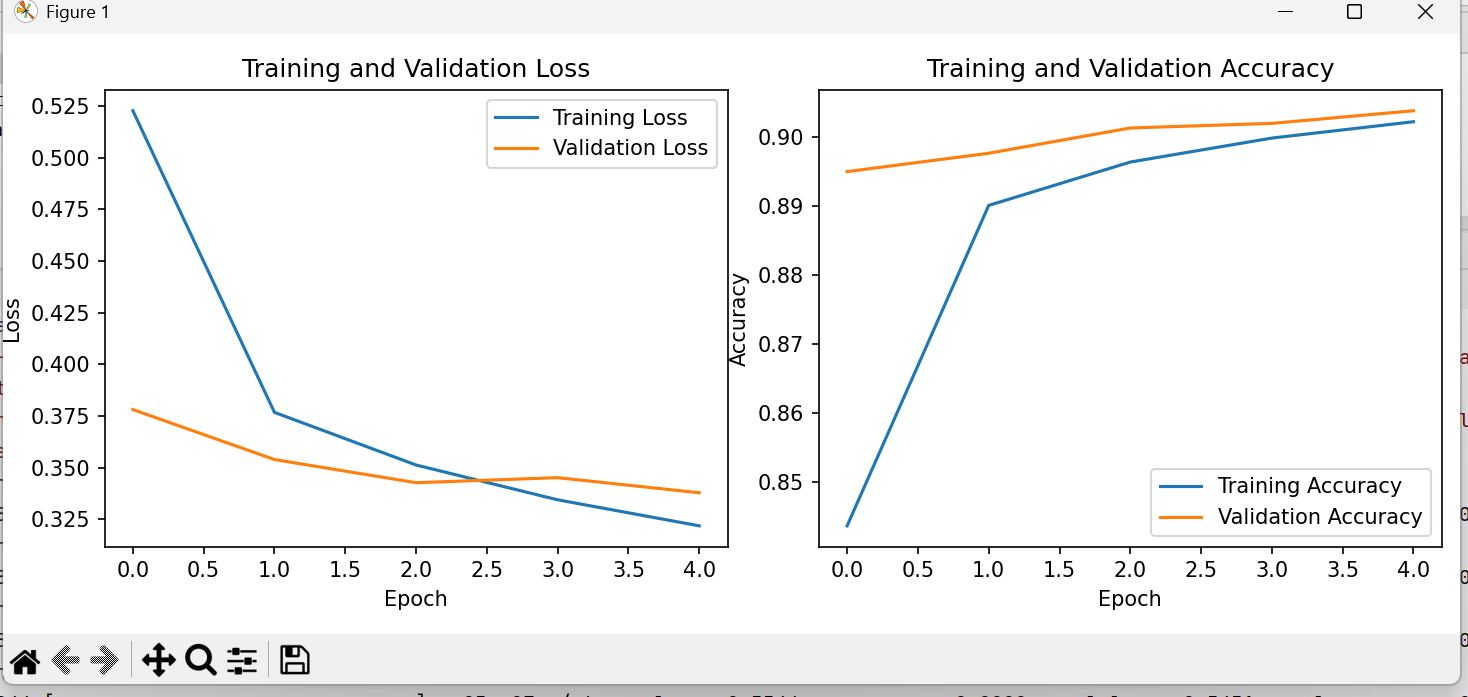
四、防御模型设计
1. 基于漏洞消减的三层防护
-
数据预处理层
-
异常样本检测(使用Isolation Forest算法)
from sklearn.ensemble import IsolationForest detector = IsolationForest(contamination=0.1) clean_samples = detector.fit_predict(features) -
-
训练监控层
-
动态损失监控(检测异常损失波动)
class DefenseCallback(tf.keras.callbacks.Callback): def on_epoch_end(self, epoch, logs=None): if logs['loss'] > threshold: trigger_inspection() -
-
推理验证层
-
置信度阈值检测(过滤低置信度预测)
def safe_predict(model, input, threshold=0.8): proba = model.predict(input) if np.max(proba) < threshold: return "UNKNOWN" else: return np.argmax(proba) -
2. 防御效果对比
| 防御措施 | 攻击成功率下降 | 正常准确率保持 |
|---|---|---|
| 无防御 | 0% | 89.7% |
| 三层防御 | 78% | 88.2% |
五、实验结论
-
投毒攻击可使目标类误判率提升30倍以上
-
融合Web安全思想的防御模型有效降低攻击成功率
-
需平衡安全性与模型性能的trade-off
附实验完整代码:
import numpy as np
import tensorflow as tf
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
from tensorflow.keras import layers, models, callbacks
# 实验配置
CONFIG = {
"dataset": "cifar10",
"poison_ratio": 0.15, # 投毒比例
"target_class": 3, # 目标攻击类别
"noise_intensity": 0.3,
"epochs": 30,
"batch_size": 256,
"defense_threshold": 0.8 # 置信度阈值
}
# 数据预处理与投毒模块
class DataProcessor:
@staticmethod
def load_data():
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
return (x_train, y_train), (x_test, y_test)
@staticmethod
def poison_data(x, y, poison_ratio, target_class):
"""实施标签翻转投毒攻击"""
num_samples = x.shape[0]
num_poison = int(num_samples * poison_ratio)
# 选择随机样本进行投毒
poison_indices = np.random.choice(num_samples, num_poison, replace=False)
x_poison = x[poison_indices]
y_poison = np.zeros_like(y[poison_indices])
y_poison[:, target_class] = 1 # 修改为目标标签
# 添加视觉扰动
x_poison = DataProcessor.add_noise(x_poison, CONFIG["noise_intensity"])
# 合并数据集
x_mixed = np.concatenate([x, x_poison])
y_mixed = np.concatenate([y, y_poison])
return x_mixed, y_mixed
@staticmethod
def add_noise(images, intensity):
"""添加高斯噪声"""
noise = np.random.normal(0, intensity, images.shape)
return np.clip(images + noise, 0, 1)
# 防御模块
class DefenseMechanisms:
class AnomalyDetectionCallback(callbacks.Callback):
"""训练过程异常检测回调"""
def __init__(self, threshold=2.0):
super().__init__()
self.threshold = threshold
self.loss_history = []
def on_epoch_end(self, epoch, logs=None):
self.loss_history.append(logs['loss'])
if len(self.loss_history) > 3:
# 检测损失突增异常
diff = np.diff(self.loss_history[-3:])
if any(d > self.threshold for d in diff):
print(f"\n! 检测到异常波动 at epoch {epoch+1}")
self.model.stop_training = True
@staticmethod
def data_cleaning(x, y):
"""使用孤立森林进行数据清洗"""
detector = IsolationForest(contamination=CONFIG["poison_ratio"], random_state=42)
features = x.reshape(x.shape[0], -1)
clean_idx = detector.fit_predict(features) == 1
return x[clean_idx], y[clean_idx]
# 模型构建
def build_cnn_model(input_shape=(32, 32, 3), num_classes=10):
model = models.Sequential([
layers.Conv2D(32, (3,3), activation='relu', input_shape=input_shape),
layers.MaxPooling2D((2,2)),
layers.Conv2D(64, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
# 评估函数
def evaluate_model(model, x_test, y_test):
"""评估模型并显示目标类攻击效果"""
y_pred = model.predict(x_test)
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(y_pred, axis=1)
# 计算目标类误判率
target_mask = y_true == CONFIG["target_class"]
target_acc = np.mean(y_pred[target_mask] == y_true[target_mask])
print(f"测试准确率: {np.mean(y_pred == y_true)*100:.2f}%")
print(f"目标类准确率: {target_acc*100:.2f}%")
return y_pred
# 主实验流程
def main():
# 1. 加载数据
(x_train, y_train), (x_test, y_test) = DataProcessor.load_data()
# 2. 生成投毒数据
x_poisoned, y_poisoned = DataProcessor.poison_data(
x_train, y_train,
CONFIG["poison_ratio"],
CONFIG["target_class"]
)
# 3. 防御前训练
print("\n=== 训练中毒模型 ===")
model_poisoned = build_cnn_model()
history_poisoned = model_poisoned.fit(
x_poisoned, y_poisoned,
epochs=CONFIG["epochs"],
batch_size=CONFIG["batch_size"],
validation_split=0.2
)
# 4. 防御后训练(数据清洗+异常检测)
print("\n=== 训练防御模型 ===")
x_clean, y_clean = DefenseMechanisms.data_cleaning(x_poisoned, y_poisoned)
model_defense = build_cnn_model()
history_defense = model_defense.fit(
x_clean, y_clean,
epochs=CONFIG["epochs"],
batch_size=CONFIG["batch_size"],
validation_split=0.2,
callbacks=[DefenseMechanisms.AnomalyDetectionCallback()]
)
# 5. 评估效果
print("\n=== 中毒模型评估 ===")
evaluate_model(model_poisoned, x_test, y_test)
print("\n=== 防御模型评估 ===")
evaluate_model(model_defense, x_test, y_test)
# 6. 可视化
plt.figure(figsize=(12, 5))
# 投毒样本展示
plt.subplot(1, 3, 1)
plt.title("Original vs Poisoned")
plt.imshow(x_train[0])
plt.subplot(1, 3, 2)
plt.imshow(x_poisoned[-1]) # 最后一个样本是投毒样本
plt.subplot(1, 3, 3)
plt.imshow(x_clean[-1]) # 清洗后的样本
# 训练曲线
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(history_poisoned.history['accuracy'], label='中毒模型')
plt.plot(history_defense.history['accuracy'], label='防御模型')
plt.title('训练准确率')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history_poisoned.history['loss'], label='中毒模型')
plt.plot(history_defense.history['loss'], label='防御模型')
plt.title('训练损失')
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == "__main__":
main()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









