







索引
一、概要
1、定义:
一种帮助MySQL高效获取数据的数据结构,排好序的快速查找数据结构。(排序+查找两种功能)
在数据之外,数据库系统还维护者满足特定查找算法的数据结构。这些数据结构以某种方法引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这些数据结构,就是索引。
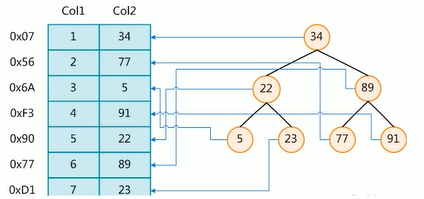
Col1:物理地址
Col2:索引序号
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址,为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个只想对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到相应的数据,从而快速的检索出符合条件的记录。
注:①查询快,增删慢原因: 不仅数据改,索引也要改
②索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘中
③我们平时所说的索引,如果没有特别指明,都是B+树(多路搜索树,多叉树)结构组织的索引。除了B+数索引,还有哈稀索引(hashindex)等。
2、优势
① 类似图书馆建书数目索引,提高索引检索的效率,降低数据库的IO成本。
②通过索引对数据进行排序,降低排序的成本,降低CPU的消耗。
3、劣势
①占据空间:索引实际上也是一张表,保存了主键和索引字段,并只想实体表的记录。
②降低更新表的速度:更新表的时候,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了的字段,都会调整一五年更新锁带来的键值变化后的索引信息。
③索引只是提高效率的一个因素,如果Mysql有大数据的表,就要花时间研究建立最有效的索引,或优化索引。
会根据业务环境等进行人为处理。
二、索引原理:
1、初始化
一颗B+树:
磁盘块:浅蓝色所示
数据项:深蓝色所示
指针:黄色所示
比如:磁盘块1包含数据线17和35,包含指针P1、P2、P3
P1:标识小于17的磁盘块,
P2:标识17-35之间的磁盘块
P3:标识大于35的磁盘块
叶子节点:存储真实的数据:即3、5、7、9…
非叶子节点:只存储指引搜索方向的数据项,如:17、35并不真是存在于数据表中
2、查找过程
示例:查找数据项29,
第一次IO:首先会把磁盘块1由磁盘加载到内存。
第一次锁定指针:在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针。
内存时间因为非常端(相比磁盘IO)可以忽略不计算,
第二次IO:通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存。
第二次锁定指针:29在26和30之间,锁定磁盘块3的P2指针。
第三次IO:把磁盘块3的P2指针把磁盘块8加载到到内存。同时内存中做二分查找找到29,结果查询,总计三次IO。
三、索引应用场景分析
需要建立索引:
1、 主键自动建立唯一索引
2、 频繁作为查询条件的字段应创建索引
3、 查询过后只能关于其他表关联的字段,外键可建立索引
4、频繁更新的字段不适合创建索引
5、Where条件里用不到的字段不创建索引(既可以满足查找,又满足业务的)
6、单键/组合索引选择问题:高并发下创建组合索引
7、查询中排序的字段,排序的字段若通过索引去访问将大大提高排序速度
(因为索引=排序+检索。建立索引的时候不仅要考虑排序的块,也要考虑是否和order的排序诉求相同)
8、查询中统计或者分组(group by)的字段,分组时候前要建立索引。
不建立索引的情况
1、表记录太少(300W左右性能开始下降)
2、不断更改的记录不要建立
3、数据重复并且分布平均的表字段,因此应该只为最惊颤查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
四、注意
索引的选择性是指索引列中不同值的数目与表中记录数的比==。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。
一个索引的选择性越接近1,这个索引的效率就越高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









