



目 录
摘 要
基于Spark的招聘信息推荐系统结合了大数据处理技术和个性化推荐算法,为用户提供精准的职位推荐。该系统通过采集和分析用户的求职数据、职位信息及互动行为,利用Spark强大的分布式计算能力,实时处理海量数据,并生成个性化推荐结果。用户在平台上的求职行为与偏好被用于训练推荐模型,系统能够不断优化推荐精度,提升用户体验。
系统的设计包括数据的预处理、特征提取、推荐算法的实现及实时推荐结果的展示。Spark的高效计算框架能够处理大规模数据集,确保推荐系统在大数据场景下的高效性与稳定性。通过对职位信息和用户行为数据的深度分析,系统能够准确把握用户需求,提供最符合其需求的职位推荐。
关键词:Spark、招聘信息、推荐系统。
The recruitment information recommendation system based on Spark combines big data processing technology and personalized recommendation algorithms to provide users with accurate job recommendations. The system collects and analyzes users' job search data, job information, and interactive behavior, utilizing Spark's powerful distributed computing capabilities to process massive amounts of data in real time and generate personalized recommendation results.The job seeking behavior and preferences of users on the platform are used to train recommendation models, and the system can continuously optimize recommendation accuracy to improve user experience.
The design of the system includes data preprocessing, feature extraction, implementation of recommendation algorithms, and display of real-time recommendation results. Spark's efficient computing framework is capable of processing large-scale datasets, ensuring the efficiency and stability of recommendation systems in big data scenarios. Through in-depth analysis of job information and user behavior data, the system can accurately grasp user needs and provide job recommendations that best meet their needs.
Keywords: Spark、Recruitment information and recommendation system.
- 绪 论
- 研究背景及意义
随着互联网技术的快速发展,招聘行业面临着信息量激增和需求多样化的挑战。传统的招聘信息处理方式难以满足现代求职者和企业日益增长的个性化需求。用户在求职过程中产生的海量数据为职位推荐提供了丰富的依据,而如何从中提取有效信息并进行实时推荐,成为提升招聘效率的关键。基于Spark的招聘信息推荐系统可以有效解决这一问题,通过高效的计算能力,处理海量数据并为求职者提供精准的职位推荐。
该系统通过分析求职者的行为、偏好以及职位特征,精准匹配用户需求,提升招聘信息的精准度与匹配度。在企业招聘过程中,能够帮助企业快速筛选到符合要求的人才,提高招聘效率,同时也为求职者提供了更合适的职位选择,减少了信息过载带来的困扰。基于Spark的推荐系统不仅提高了信息处理速度,也增强了系统的扩展性和稳定性,使得平台能够更好地应对日益增长的数据量和用户需求,推动招聘行业向更加智能化、个性化的方向发展。
在国外,招聘信息推荐系统的研究和应用已经取得了显著进展。早期的推荐系统主要依赖于基于内容的推荐方法和协同过滤技术,这些方法虽然在某些场景下表现出色,但往往无法有效处理大规模数据。随着数据处理技术的不断进步,许多研究开始采用分布式计算框架如Spark,结合海量招聘信息和求职者行为数据,开发出更为高效、精确的职位推荐系统。例如,LinkedIn和Indeed等国际知名招聘平台,通过分析用户的历史行为、社交网络以及职位相关信息,提供个性化的职位推荐服务。许多研究则提出了基于Spark等大数据处理平台的推荐系统架构,能够在大规模数据集上高效执行,并实时更新推荐结果,以应对不断变化的用户需求和招聘信息。
在国内,招聘信息推荐系统的研究相对较晚,但随着大数据技术的普及,相关研究也逐步深入。国内主要的招聘平台如智联招聘、猎云网、前程无忧等,也开始引入推荐算法和大数据技术,以提高用户体验和招聘效率。国内学者在职位推荐领域的研究更多集中在如何结合用户画像、职位信息以及用户行为数据来优化推荐结果。近年来,基于Spark等分布式计算平台的推荐系统逐渐成为研究的热点,不仅能解决传统推荐算法在大规模数据处理时的性能瓶颈,还能处理实时更新需求。国内一些学者提出了结合用户行为分析和社交网络数据的职位推荐方法,旨在提高推荐的准确性和实用性。同时,随着招聘平台的竞争加剧,个性化推荐逐渐成为提升用户粘性和招聘成功率的关键因素。
国内外在招聘信息推荐系统的研究和应用方面都取得了显著进展。国外一些知名招聘平台已经通过大数据和分布式计算技术,构建了高效且精确的职位推荐系统,能够处理海量数据并实时优化推荐结果。国内虽然起步稍晚,但随着大数据技术的普及,越来越多的招聘平台开始采纳先进的推荐算法,并结合用户行为数据和职位特征来提升推荐的精准度。两者的共同目标是通过高效的数据处理和智能化推荐系统,提高招聘效率,满足求职者和企业的个性化需求。
本论文共分为七个主要章节,具体结构如下:
1. 绪论:介绍研究背景与意义,回顾国内外研究现状,并概述论文的组织结构。
2. 相关技术介绍:本章节将对招聘信息推荐系统的实现关键技术进行简要介绍。
3. 需求分析:对系统的功能需求和非功能需求进行分析,明确用户和管理员的需求,并进行可行性分析,包括技术、操作和经济可行性。
4. 系统设计:涵盖系统架构设计、系统模块设计,并进行数据库的概念设计与表设计。
5. 系统实现:具体描述各个功能模块的实现过程,展示系统如何根据需求进行开发。
6. 系统测试:阐述测试的目的,分析测试结果并得出结论,以验证系统的稳定性和功能完整性。
7. 总结:总结研究的主要成果和贡献,指出存在的不足及未来的研究方向。
B/S体系[1],即Browser/Server体系,是一种常见的网络应用程序架构。其工作原理基于客户端与服务器之间的请求-响应模型。用户通过浏览器向服务器发送请求,服务器接收到请求后进行处理,并生成相应的响应结果,最终将响应返回给客户端。浏览器接收到服务器返回的响应后,解析其中的标记语言(如HTML[2]),并根据CSS样式表和PythonScript脚本来渲染页面,呈现给用户。用户可以与页面进行交互,例如点击链接、填写表单等操作,这些操作会触发新的请求,循环执行上述过程。
Apache Spark 是一种开源的分布式计算框架,专为大规模数据处理而设计,具有高性能、通用性和可扩展性等特点。它通过内存计算技术显著提升了数据处理速度,尤其在处理大规模数据集时表现出色,比传统框架(如 Hadoop MapReduce)快数十倍甚至上百倍。Spark 提供了丰富的功能模块,包括 Spark SQL(用于结构化数据处理)、Spark Streaming(实时流处理)和 GraphX(图计算),能够满足从批处理到实时计算、数据分析等多样化需求。这些功能使得 Spark 能够广泛应用于各种数据处理任务,极大提升了工作效率[3]。
此外,Spark 还支持多种编程语言(如 Scala、Python 和 Java),并兼容 Hadoop 生态系统,具有极高的灵活性。其高度可扩展的架构,使得开发者能够根据需求不断优化系统性能,尤其是在资源配置和计算能力的调度方面具有显著优势。通过基于 Spark 的配置优化技术,能够大幅提高系统的稳定性与计算资源的利用率,从而在大规模数据处理任务中获得更高效的执行效果[4]。Spark 已在多个领域中得到了广泛应用,是现代大数据处理和分析的重要工具。
MySQL是一种广泛使用的开源关系型数据库管理系统[5](RDBMS),其稳定性、可靠性和卓越性能使其成为众多应用程序的首选数据库。MySQL支持标准SQL语法,并提供丰富的功能和特性,如事务处理、触发器和存储过程等,以满足开发者对数据管理和操作的需求。MySQL具有良好的可扩展性,支持主从复制、分布式架构和集群部署,适用于各种规模和负载的应用场景。作为一个开源项目,MySQL拥有庞大的用户社区和活跃的开发者社区,为用户提供了丰富的文档、教程和支持资源。总之,MySQL是一款可靠、强大且灵活的关系型数据库管理系统[6],通过其卓越性能和可扩展性,帮助开发者高效地管理和操作数据,并得到了广大用户的认可和应用。
Python是一种简洁易读、跨平台且功能强大的编程语言[7]。它拥有庞大而活跃的社区,提供了丰富的第三方库和框架,如NumPy、Pandas和Spark,使开发人员能够快速构建各种应用程序。Python在数据处理和科学计算方面表现出色,通过相关库和工具,可以进行数据分析、机器学习和科学计算等任务。此外,Python广泛应用于Web开发[8]、自动化脚本、网络爬虫等领域,其多样性使其成为一个全能的编程语言。无论你是初学者还是有经验的开发者,Python的简单语法、跨平台性以及强大的社区支持都能为你提供高效、优雅和可靠的编程体验。总之,Python是一个强大而灵活的编程语言,深受开发人员喜爱,并在各个领域得到广泛应用。
爬虫技术是指使用程序自动抓取互联网数据的过程。网络爬虫能够模拟用户访问网页,并提取所需的数据。常用的爬虫库有requests和BeautifulSoup,它们可以帮助用户获取网页内容并解析HTML结构。
爬虫技术的主要步骤包括:
发送请求:向目标网站发送HTTP请求,获取网页内容。
解析数据:使用解析库提取所需信息,比如商品名称、价格等。
存储数据:将提取的数据保存到本地数据库或文件中,便于后续分析。
遵循规则:遵循网站的robots.txt协议,避免对网站造成负担或被禁止访问。
Pandas是一个强大的数据分析和操作库,特别适用于处理结构化数据。它提供了DataFrame和Series等数据结构,使数据处理变得更加简单高效。
Pandas的主要功能:
数据清洗:处理缺失数据、重复数据及数据格式转换。
数据分析:支持基本的统计操作和复杂的查询,方便数据分析师工作。
数据导入导出:能够方便地与多种格式(如CSV、Excel、数据库等)进行数据交互。
Matplotlib是一个广泛使用的绘图库,适用于生成各种类型的图形和可视化效果。它提供了高度灵活的绘图功能,适合于从简单图表到复杂可视化的各种需求。
Matplotlib的主要特点:
多种图形类型:支持折线图、柱状图、散点图、饼图等多种类型的图形。
高度自定义:可调整图形的各个参数,定制自己的可视化效果。
与NumPy、Pandas兼容性强:可以直接从NumPy数组和Pandas DataFrame中进行绘制。
交互性:支持在Jupyter Notebook等环境中进行交互式绘图,提高用户体验。
在技术可行性方面,选择使用Python作为开发语言,结合相应的框架Spark,以实现系统的功能需求。Python作为一种简洁而强大的编程语言,具有丰富的库支持和成熟的开发社区,可以满足招聘信息推荐系统的开发需求。Spark作为一个强大的分布式计算框架,能够高效处理大规模数据,提供高性能的数据处理和推荐服务。Spark的高扩展性和灵活性,使得系统能够在大数据环境下平稳运行,确保推荐算法的高效执行。
系统开发采用开源技术栈,降低了软件授权与工具采购成本。Spark框架简化了大数据处理流程,提高了数据处理效率,缩短了项目周期,减少了人力投入。此外,借助云计算资源部署系统,可根据实际需求灵活调整服务器配置,进一步降低硬件成本。Spark的分布式计算能力使得系统能够处理海量数据,满足招聘信息推荐系统对实时性和精确度的高要求。
随着互联网和大数据技术的发展,招聘市场需求不断增加,传统的招聘方式难以满足求职者和企业的个性化需求。Spark平台能够高效处理海量数据,提供精准的职位推荐,不仅提升了招聘效率,也优化了用户体验。该系统的实现可以帮助企业快速筛选人才,降低招聘成本,推动招聘行业向智能化和高效化方向发展,符合社会发展的需求。
在操作可行性方面,本系统设计注重用户体验,采用了直观易用的界面设计,并提供详细的帮助文档支持,确保用户可以轻松上手使用各项功能。无论是用户还是后台管理员,都能通过简洁明了的操作流程完成信息查询和管理等任务。因此,从用户操作的角度来看,本系统具备良好的操作可行性。
招聘信息推荐系统划分为了前端模块和后端模块两大部分。
前端普通用户模块:
注册登录:注册登录功能允许普通用户创建新账户或使用现有账户登录系统。注册时,用户需要提供必要的信息,如用户名、密码、邮箱等。登录则需要输入已注册的用户名和密码,系统会验证信息的正确性,确保用户身份的安全性。
首页:首页提供了网站的基本导航和多样化的内容展示。页面包括轮播图、导航栏、招聘资讯、职位推荐、求职相关好文和搜索框等功能。用户可以在首页快速浏览最新的招聘信息、行业动态,或者进行职位搜索,快速找到感兴趣的岗位。跳转链接可以引导用户进入第三方平台投递简历。
通知公告:用户可以查看网站的公告信息,了解最新的政策、新闻或活动内容。栏目包括关于我们、联系方式和网站介绍等,确保用户了解网站的基本信息和运营方式。
招聘资讯:用户可以浏览详细的招聘资讯,包括职位要求、公司信息等,并能够对感兴趣的资讯进行点赞、收藏、评论或回复。用户还可以通过搜索功能找到自己关注的招聘信息。所有的评论和回复都可以进行删除操作。
留言反馈:用户可以在留言反馈栏目发布反馈信息,包括标题和留言内容。提交后,管理员可以查看和处理这些留言,以改善用户体验。
职位推荐:职位推荐功能允许用户查看职位的详细信息,包括职位类型、求职标签、工作地点、学历要求、薪资待遇等。用户可以通过搜索功能快速找到感兴趣的职位,并进行数据对比,帮助做出更合适的选择。此外,用户还可以对职位进行点赞、收藏、评论以及回复,所有操作都支持删除功能。通过系统的智能推荐,职位将根据用户的标签和兴趣进行个性化推送,用户还可以进入职位详情页进行简历投递。
求职好文:用户可以浏览求职相关的文章和资源,查看文章的详细内容,并根据自己的专业背景进行筛选。用户可以下载简历文件、点赞、收藏、评论或回复这些文章,提升自己的求职技巧和准备。
我的账户:用户可以管理自己的账户,修改个人资料、更新登录信息和密码等。该功能提供便捷的方式帮助用户保持个人信息的最新状态,保障账户安全。
个人中心:用户可以在个人中心查看和管理自己的求职活动、账户信息、应聘记录等,方便集中管理个人的求职过程。
个人首页:用户的个人首页展示了个人资料、求职状态、收藏的职位、已投递的简历等信息,用户可以随时修改和更新这些信息。
应聘记录:用户可以查看自己投递简历的记录,查询审核状态、查看是否通过等,并下载简历文件。用户可以对每条应聘记录进行搜索、查询、重置等操作。
求职好文:用户可以查看求职好文的详情,查看文章中的评论,并进行相关操作如搜索、增删改查文章内容。此功能帮助用户获取更多的求职知识和资讯。
收藏:用户可以查看所有收藏的资讯、职位和文章等。对不感兴趣的内容,用户可以进行删除操作,确保收藏内容的准确性和实用性。
评论管理:用户可以查看自己在前台的所有评论信息及其被回复情况,通过输入昵称或内容进行搜索,并对页面查询结果进行重置或删除操作。点击评论来源可直接跳转至相关页面。
后端管理员模块:
后台首页:管理员可以通过后台首页查看职位推荐统计、应聘记录统计、求职好文统计等数据,通过折线图和圆形图等形式展示关键指标。管理员可以根据这些数据作出业务调整,同时也可以修改个人资料和密码。
系统用户:管理员可以管理系统中的所有用户,包括普通用户和管理员。管理员可以查看用户的详细信息,并进行搜索、增删改查操作,确保用户信息的准确性和及时更新。
求职标签管理:管理员可以查看、添加、删除和管理求职标签。通过求职标签,系统可以根据用户需求对职位进行更精确的推荐。
职位推荐管理:管理员可以查看职位推荐的详细信息,包括职位内容、评论、推荐状态等。管理员可以对职位进行添加、修改、查询、删除等操作,确保职位信息的准确性和完整性。
职位类型管理:管理员可以管理职位类型,包括查看、搜索、添加、修改、删除职位类型等。职位类型管理有助于系统对职位进行更有效的分类和推荐。
应聘记录管理:管理员可以查看所有用户的应聘记录,包括审核和管理用户投递的简历。管理员可以对每条应聘记录进行搜索、查询、重置、删除等操作。
求职好文管理:管理员可以查看求职好文的详细信息、评论、审核状态等,并进行搜索、添加、修改、删除等操作。管理员可以管理文章的发布和内容,确保用户获取到有价值的求职信息。
职位数据管理:管理员可以查看和管理职位数据,包括职位详情、添加职位、删除职位等。管理员可以导出职位数据,下载导入文档,还支持通过爬虫技术一次性爬取多个招聘数据,极大地提高招聘信息的更新速度。招聘数据可视化大屏展示:管理员可以通过可视化大屏展示招聘数据,包括职位推荐分析、行业分类统计、职位收藏分析、职位搜索统计、简历投递分析等。管理员可以通过这些数据分析,调整招聘策略,提高招聘效果。
系统管理:管理员可以管理网站的轮播图,包括查看、搜索、添加、删除、修改等操作,确保网站的视觉效果和功能展示符合需求。
留言管理:管理员可以查看用户留言的详情,进行回复或删除留言等操作。管理员也可以通过搜索功能进行留言查询,处理用户反馈和建议。
通知公告管理:管理员可以管理网站的通知公告,包括查看、搜索、编辑、添加、删除等操作。确保通知信息及时更新,保持用户知晓重要信息。
资源管理:管理员可以管理招聘资讯和资讯分类,包括查看、修改、删除、添加等操作。管理员可通过这一功能优化网站的资源分类,提升用户体验。
权限管理:管理员可以查看权限列表,对系统各类用户组的权限进行修改和管理。管理员还可以添加、删除、修改权限,帮助系统管理员更好地分配用户权限。
招聘信息推荐系统的非功能性需求比如招聘信息推荐系统的安全性怎么样,可靠性怎么样,性能怎么样,可拓展性怎么样等,具体可以表示在如下3-1表格中:
表3-1招聘信息推荐系统非功能需求表
| 安全性 | 主要指招聘信息推荐系统数据库的安装,数据库的使用和密码的设定必须合乎规范。 |
| 可靠性 | 可靠性是指招聘信息推荐系统能够安装用户的指示进行操作,经过测试,可靠性90%以上。 |
| 性能 | 性能是影响招聘信息推荐系统占据市场的必要条件,所以性能最好要佳才好。 |
| 可扩展性 | 比如数据库预留多个属性,比如接口的使用等确保了系统的非功能性需求。 |
| 易用性 | 用户只要跟着招聘信息推荐系统的页面展示内容进行操作,就可以了。 |
| 可维护性 | 招聘信息推荐系统开发的可维护性是非常重要的,经过测试,可维护性没有问题 |
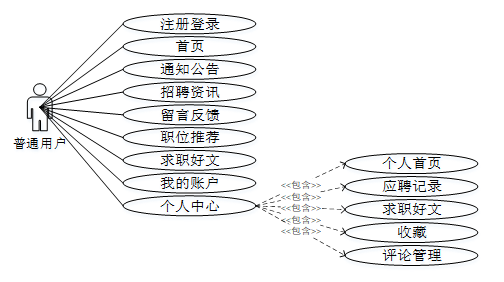
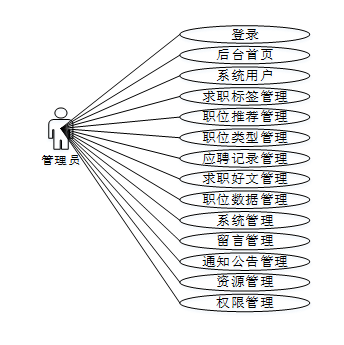
招聘信息推荐系统的完整UML用例图分别是图3-1、3-2。
普通用户角色用例如下图所示。
-
-
-
-
- 招聘信息推荐系统普通用户角色用例图
-
-
-
管理员角色用例如下图所示。
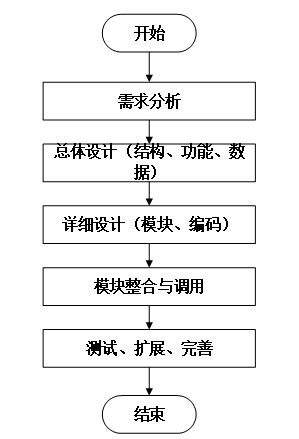
系统开发流程的主要步骤,从需求分析到系统完成的全过程。流程包括需求分析、总体设计(结构、功能、数据)、详细设计(模块、编码)、模块整合与调用,以及测试、扩展和完善,最终完成系统的开发。本系统的开发流程如下图所示
-
-
-
-
- 系统开发流程图
-
- 用户登录流程
-
-
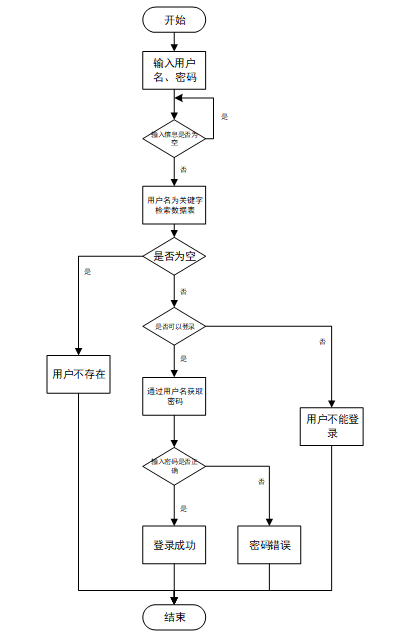
用户输入用户名和密码后,系统先检查输入是否为空,再验证用户名是否存在,若存在则通过用户名获取密码并校验。若密码正确则登录成功,否则提示密码错误。若用户名不存在或无法登录,提示用户操作无效。如下图所示。
-
-
-
-
- 登录流程图
-
- 系统操作流程
-
-
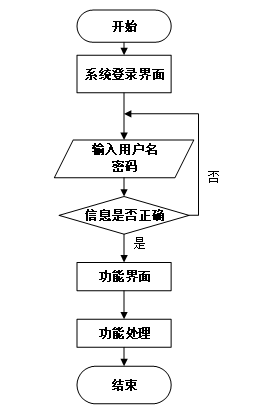
用户首先进入系统登录界面,输入用户名和密码后,系统验证信息是否正确。若验证失败,返回登录界面重新输入,若验证成功,则进入功能界面,执行相应功能处理后结束操作流程。操作流程如下图所示。
-
-
-
-
- 系统操作流程图
-
- 添加信息流程
-
-
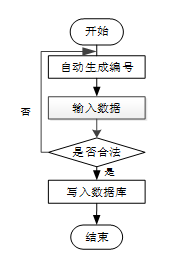
管理员可以添加信息,用户添加可以自己权限内的信息,输入信息后,要想利用这个软件来进行系统的安全管理,首先需要登录到该软件中。添加信息流程如下图所示。
-
-
-
-
- 添加信息流程图
-
-
-
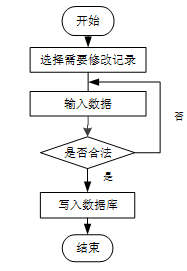
用户首先选择需要修改的记录,输入修改后的数据,系统判断输入数据是否合法。若数据不合法,提示重新输入,若数据合法,则将修改后的数据写入数据库,完成操作后流程结束。修改信息流程图如下图所示。
-
-
-
-
- 修改信息流程图
-
- 删除信息流程
-
-
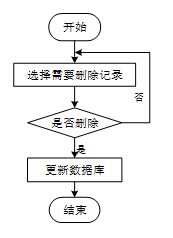
用户选择需要删除的记录后,系统判断是否确认删除。若未确认,返回选择环节,若确认删除,则更新数据库,删除对应记录,完成操作后流程结束。删除信息流程图如下图所示。
-
-
-
-
- 删除信息流程图
-
-
-
- 总体设计
本章主要讨论的内容包括招聘信息推荐系统的功能模块设计、数据库系统设计。
本招聘信息推荐系统从架构上分为三层:表现层(PL)、数据处理层(DPL)、数据存储层(SL)以及业务逻辑层(BLL)。
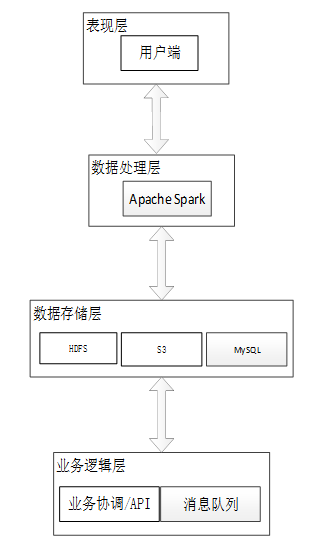
-
-
-
-
- 招聘信息推荐系统架构设计图
-
-
-
表现层(Presentation Layer):负责与用户交互,展示计算和分析结果。该层可以通过前端应用(如Web页面、移动应用等)接收用户输入,并通过API或Web接口展示Spark计算后的结果。
数据处理层(Data Processing Layer):这一层包含了Apache Spark及其相关组件,如Spark SQL、Spark Streaming等,负责大规模的数据处理、分析、计算等任务。这里的数据处理可以是批量处理(batch processing)或流处理(stream processing),具体取决于业务需求。数据从存储系统(如HDFS、S3、MySQL数据库)传入Spark进行处理,处理结果通过API或消息队列传递到下一层。
数据存储层(Storage Layer):存储系统主要用于存储原始数据和Spark处理后的数据。常见的存储系统包括HDFS、S3、Cassandra、HBase等。数据存储层通过Spark进行数据读取和写入,支持大规模的并行计算和分布式存储。
业务逻辑层(Business Logic Layer):这一层负责协调系统的业务逻辑,接收用户的请求,触发数据处理层的计算任务,并根据结果进行处理。业务逻辑层可以根据需要选择数据源,并通过API或消息队列与Spark进行交互。
这四个层次相互独立但又紧密协作,共同构成了基于Spark的大数据处理和招聘信息推荐系统的完整架构。表示层负责与用户交互并展示计算结果,数据处理层利用Spark进行大规模数据处理与分析,数据存储层确保数据的高效存储与访问,业务逻辑层协调系统的各项功能并管理数据流。通过这种合理的分层设计,系统能够实现高效的计算和分析,同时提供灵活的扩展性和高可维护性,为用户提供优质的服务和体验。
在上一章节中主要对系统的功能性需求和非功能性需求进行分析,并且根据需求分析了本招聘信息推荐系统中的用例。那么接下来就要开始对本招聘信息推荐系统的架构、主要功能和数据库开始进行设计。招聘信息推荐系统根据前面章节的需求分析得出,招聘信息推荐系统的功能模块图如下图所示。
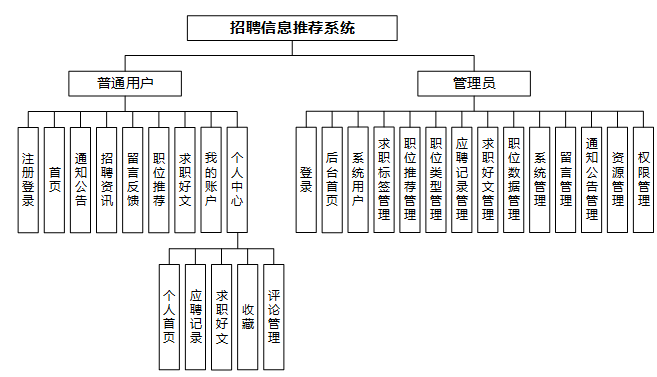
-
-
-
-
- 招聘信息推荐系统功能模块图
-
-
- 数据库设计
-
数据库设计一般包括需求分析、概念模型设计、数据库表建立三大过程,其中需求分析前面章节已经阐述,概念模型设计有概念模型和逻辑结构设计两部分。
-
-
- 数据库概念结构设计
-
下面是整个招聘信息推荐系统中主要的数据库表总E-R实体关系图。
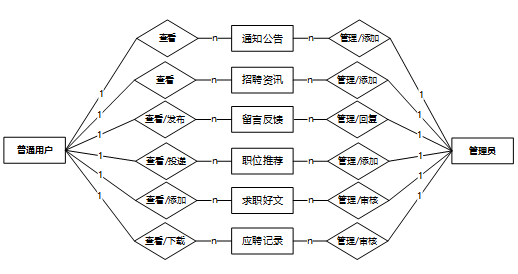
-
-
-
-
- 招聘信息推荐系统总E-R关系图
-
- 数据库逻辑结构设计
-
-
通过上一小节中招聘信息推荐系统中总E-R关系图上得出一共需要创建多个数据表。在此主要罗列几个主要的数据库表结构设计。
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | token_id | int | 是 | 是 | 临时访问牌ID | |
| 2 | token | varchar | 64 | 否 | 否 | 临时访问牌 |
| 3 | info | text | 65535 | 否 | 否 | 信息 |
| 4 | maxage | int | 是 | 否 | 最大寿命:默认2小时 | |
| 5 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 6 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 7 | user_id | int | 是 | 否 | 用户编号 |
表 4-2-application_record(应聘记录)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | application_record_id | int | 是 | 是 | 应聘记录ID | |
| 2 | ordinary_user | int | 否 | 否 | 普通用户 | |
| 3 | user_name | varchar | 64 | 否 | 否 | 用户姓名 |
| 4 | users_mobile_phone | varchar | 64 | 否 | 否 | 用户手机 |
| 5 | job_title | varchar | 64 | 否 | 否 | 职位名称 |
| 6 | position_type | varchar | 64 | 否 | 否 | 职位类型 |
| 7 | place_of_work | varchar | 64 | 否 | 否 | 工作地点 |
| 8 | application_time | date | 否 | 否 | 应聘时间 | |
| 9 | number_of_applicants | double | 否 | 否 | 应聘人数 | |
| 10 | resume_file | varchar | 255 | 否 | 否 | 简历文件 |
| 11 | application_remarks | text | 65535 | 否 | 否 | 应聘备注 |
| 12 | examine_state | varchar | 16 | 是 | 否 | 审核状态 |
| 13 | examine_reply | varchar | 16 | 否 | 否 | 审核回复 |
| 14 | create_time | datetime | 是 | 否 | 创建时间 | |
| 15 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 16 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 17 | source_id | int | 否 | 否 | 来源ID | |
| 18 | source_user_id | int | 否 | 否 | 来源用户 |
表 4-3-article(文章)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | article_id | mediumint | 是 | 是 | 文章id | |
| 2 | title | varchar | 125 | 是 | 是 | 标题 |
| 3 | type | varchar | 64 | 是 | 否 | 文章分类 |
| 4 | hits | int | 是 | 否 | 点击数 | |
| 5 | praise_len | int | 是 | 否 | 点赞数 | |
| 6 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 7 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 8 | source | varchar | 255 | 否 | 否 | 来源 |
| 9 | url | varchar | 255 | 否 | 否 | 来源地址 |
| 10 | tag | varchar | 255 | 否 | 否 | 标签 |
| 11 | content | longtext | 4294967295 | 否 | 否 | 正文 |
| 12 | img | varchar | 255 | 否 | 否 | 封面图 |
| 13 | description | text | 65535 | 否 | 否 | 文章描述 |
表 4-4-article_type(文章分类)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | type_id | smallint | 是 | 是 | 分类ID | |
| 2 | display | smallint | 是 | 否 | 显示顺序 | |
| 3 | name | varchar | 16 | 是 | 否 | 分类名称 |
| 4 | father_id | smallint | 是 | 否 | 上级分类ID | |
| 5 | description | varchar | 255 | 否 | 否 | 描述 |
| 6 | icon | text | 65535 | 否 | 否 | 分类图标 |
| 7 | url | varchar | 255 | 否 | 否 | 外链地址 |
| 8 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 9 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-5-auth(用户权限管理)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | auth_id | int | 是 | 是 | 授权ID | |
| 2 | user_group | varchar | 64 | 否 | 否 | 用户组 |
| 3 | mod_name | varchar | 64 | 否 | 否 | 模块名 |
| 4 | table_name | varchar | 64 | 否 | 否 | 表名 |
| 5 | page_title | varchar | 255 | 否 | 否 | 页面标题 |
| 6 | path | varchar | 255 | 否 | 否 | 路由路径 |
| 7 | parent | varchar | 64 | 否 | 否 | 父级菜单 |
| 8 | parent_sort | int | 是 | 否 | 父级菜单排序 | |
| 9 | position | varchar | 32 | 否 | 否 | 位置 |
| 10 | mode | varchar | 32 | 是 | 否 | 跳转方式 |
| 11 | add | tinyint | 是 | 否 | 是否可增加 | |
| 12 | del | tinyint | 是 | 否 | 是否可删除 | |
| 13 | set | tinyint | 是 | 否 | 是否可修改 | |
| 14 | get | tinyint | 是 | 否 | 是否可查看 | |
| 15 | field_add | text | 65535 | 否 | 否 | 添加字段 |
| 16 | field_set | text | 65535 | 否 | 否 | 修改字段 |
| 17 | field_get | text | 65535 | 否 | 否 | 查询字段 |
| 18 | table_nav_name | varchar | 500 | 否 | 否 | 跨表导航名称 |
| 19 | table_nav | varchar | 500 | 否 | 否 | 跨表导航 |
| 20 | option | text | 65535 | 否 | 否 | 配置 |
| 21 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 22 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-6-code_token(验证码)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | code_token_id | int | 是 | 是 | 验证码ID | |
| 2 | token | varchar | 255 | 否 | 否 | 令牌 |
| 3 | code | varchar | 255 | 否 | 否 | 验证码 |
| 4 | expire_time | timestamp | 是 | 否 | 失效时间 | |
| 5 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 6 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-7-collect(收藏)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | collect_id | int | 是 | 是 | 收藏ID | |
| 2 | user_id | int | 是 | 是 | 收藏人ID | |
| 3 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 4 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 5 | source_id | int | 是 | 否 | 来源ID | |
| 6 | title | varchar | 255 | 否 | 否 | 标题 |
| 7 | img | varchar | 255 | 否 | 否 | 封面 |
| 8 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 9 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-8-comment(评论)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | comment_id | int | 是 | 是 | 评论ID | |
| 2 | user_id | int | 是 | 是 | 评论人ID | |
| 3 | reply_to_id | int | 是 | 否 | 回复评论ID | |
| 4 | content | longtext | 4294967295 | 否 | 否 | 内容 |
| 5 | nickname | varchar | 255 | 否 | 否 | 昵称 |
| 6 | avatar | varchar | 255 | 否 | 否 | 头像地址 |
| 7 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 8 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 9 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 10 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 11 | source_id | int | 是 | 否 | 来源ID |
表 4-9-good_job_search(求职好文)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | good_job_search_id | int | 是 | 是 | 求职好文ID | |
| 2 | ordinary_user | int | 否 | 否 | 普通用户 | |
| 3 | job_title | varchar | 64 | 否 | 否 | 求职标题 |
| 4 | user_name | varchar | 64 | 否 | 否 | 用户姓名 |
| 5 | user_gender | varchar | 64 | 否 | 否 | 用户性别 |
| 6 | professional_user | varchar | 64 | 否 | 否 | 用户专业 |
| 7 | skill_specialty | text | 65535 | 否 | 否 | 技能特长 |
| 8 | resume_file | varchar | 255 | 否 | 否 | 简历文件 |
| 9 | cover_image | varchar | 255 | 否 | 否 | 封面图片 |
| 10 | job_search_details | longtext | 4294967295 | 否 | 否 | 求职详情 |
| 11 | praise_len | int | 是 | 否 | 点赞数 | |
| 12 | collect_len | int | 是 | 否 | 收藏数 | |
| 13 | comment_len | int | 是 | 否 | 评论数 | |
| 14 | examine_state | varchar | 16 | 是 | 否 | 审核状态 |
| 15 | examine_reply | varchar | 16 | 否 | 否 | 审核回复 |
| 16 | create_time | datetime | 是 | 否 | 创建时间 | |
| 17 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-10-hits(用户点击)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | hits_id | int | 是 | 是 | 点赞ID | |
| 2 | user_id | int | 是 | 否 | 点赞人 | |
| 3 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 4 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 5 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 6 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 7 | source_id | int | 是 | 否 | 来源ID |
表 4-11-job_labels(求职标签)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | job_labels_id | int | 是 | 是 | 求职标签ID | |
| 2 | job_labels | varchar | 64 | 否 | 否 | 求职标签 |
| 3 | create_time | datetime | 是 | 否 | 创建时间 | |
| 4 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-12-message(留言板)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | message_id | int | 是 | 是 | 留言板ID | |
| 2 | user_id | int | 是 | 否 | 用户ID | |
| 3 | title | varchar | 64 | 否 | 否 | 标题 |
| 4 | content | longtext | 4294967295 | 是 | 否 | 内容 |
| 5 | nickname | varchar | 32 | 是 | 否 | 昵称 |
| 6 | avatar | varchar | 255 | 否 | 否 | 头像 |
| 7 | | varchar | 125 | 否 | 否 | 留言者邮箱 |
| 8 | phone | varchar | 11 | 否 | 否 | 留言者手机号码 |
| 9 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 10 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 11 | reply | longtext | 4294967295 | 否 | 否 | 回复 |
| 12 | reply_state | tinyint | 否 | 否 | 回复状态 |
表 4-13-notice(公告)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | notice_id | mediumint | 是 | 是 | 公告ID | |
| 2 | title | varchar | 125 | 是 | 否 | 标题 |
| 3 | content | longtext | 4294967295 | 否 | 否 | 正文 |
| 4 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 5 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-14-ordinary_user(普通用户)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | ordinary_user_id | int | 是 | 是 | 普通用户ID | |
| 2 | user_name | varchar | 64 | 否 | 否 | 用户姓名 |
| 3 | user_gender | varchar | 64 | 否 | 否 | 用户性别 |
| 4 | users_mobile_phone | varchar | 16 | 否 | 否 | 用户手机 |
| 5 | job_labels | varchar | 64 | 否 | 否 | 求职标签 |
| 6 | professional_user | varchar | 64 | 否 | 否 | 用户专业 |
| 7 | examine_state | varchar | 16 | 是 | 否 | 审核状态 |
| 8 | user_id | int | 是 | 否 | 用户ID | |
| 9 | create_time | datetime | 是 | 否 | 创建时间 | |
| 10 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-15-position_data(职位数据)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | position_data_id | int | 是 | 是 | 职位数据ID | |
| 2 | job_title | text | 65535 | 否 | 否 | 职位名称 |
| 3 | salary_treatment | text | 65535 | 否 | 否 | 薪资待遇 |
| 4 | academic_requirements | text | 65535 | 否 | 否 | 学历要求 |
| 5 | work_experience | text | 65535 | 否 | 否 | 工作经验 |
| 6 | enterprise_information | text | 65535 | 否 | 否 | 企业信息 |
| 7 | industry_category | text | 65535 | 否 | 否 | 行业类别 |
| 8 | skill_requirements | text | 65535 | 否 | 否 | 技能要求 |
| 9 | place_of_work | text | 65535 | 否 | 否 | 工作地点 |
| 10 | regional_information | text | 65535 | 否 | 否 | 区域信息 |
| 11 | number_of_searches | double | 否 | 否 | 搜索次数 | |
| 12 | number_of_views | double | 否 | 否 | 浏览数量 | |
| 13 | number_of_collections | double | 否 | 否 | 收藏数量 | |
| 14 | number_of_resumes_deliveries | double | 否 | 否 | 简历投递数 | |
| 15 | create_time | datetime | 是 | 否 | 创建时间 | |
| 16 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-16-position_recommend(职位推荐)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | position_recommend_id | int | 是 | 是 | 职位推荐ID | |
| 2 | job_title | varchar | 64 | 否 | 否 | 职位名称 |
| 3 | position_type | varchar | 64 | 否 | 否 | 职位类型 |
| 4 | job_labels | varchar | 64 | 否 | 否 | 求职标签 |
| 5 | salary_treatment | double | 否 | 否 | 薪资待遇 | |
| 6 | academic_requirements | varchar | 64 | 否 | 否 | 学历要求 |
| 7 | skill_requirements | varchar | 64 | 否 | 否 | 技能要求 |
| 8 | place_of_work | varchar | 64 | 否 | 否 | 工作地点 |
| 9 | cover_image | varchar | 255 | 否 | 否 | 封面图片 |
| 10 | job_description | longtext | 4294967295 | 否 | 否 | 职位介绍 |
| 11 | hits | int | 是 | 否 | 点击数 | |
| 12 | praise_len | int | 是 | 否 | 点赞数 | |
| 13 | collect_len | int | 是 | 否 | 收藏数 | |
| 14 | comment_len | int | 是 | 否 | 评论数 | |
| 15 | recommend | int | 是 | 否 | 智能推荐 | |
| 16 | application_record_limit_times | int | 是 | 否 | 投递简历限制次数 | |
| 17 | create_time | datetime | 是 | 否 | 创建时间 | |
| 18 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-17-position_type(职位类型)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | position_type_id | int | 是 | 是 | 职位类型ID | |
| 2 | position_type | varchar | 64 | 否 | 否 | 职位类型 |
| 3 | create_time | datetime | 是 | 否 | 创建时间 | |
| 4 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-18-praise(点赞)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | praise_id | int | 是 | 是 | 点赞ID | |
| 2 | user_id | int | 是 | 是 | 点赞人 | |
| 3 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 4 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 5 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 6 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 7 | source_id | int | 是 | 否 | 来源ID | |
| 8 | status | tinyint | 是 | 否 | 点赞状态:1为点赞,0已取消 |
表 4-19-score(评分)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | score_id | int | 是 | 是 | 评分ID | |
| 2 | user_id | int | 是 | 否 | 评分人 | |
| 3 | nickname | varchar | 64 | 否 | 否 | 昵称 |
| 4 | score_num | double | 是 | 否 | 评分 | |
| 5 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 6 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 7 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 8 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 9 | source_id | int | 是 | 否 | 来源ID |
表 4-20-slides(轮播图)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | slides_id | int | 是 | 是 | 轮播图ID | |
| 2 | title | varchar | 64 | 否 | 否 | 标题 |
| 3 | content | varchar | 255 | 否 | 否 | 内容 |
| 4 | url | varchar | 255 | 否 | 否 | 链接 |
| 5 | img | varchar | 255 | 否 | 否 | 轮播图 |
| 6 | hits | int | 是 | 否 | 点击量 | |
| 7 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 8 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-21-upload(文件上传)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | upload_id | int | 是 | 是 | 上传ID | |
| 2 | name | varchar | 64 | 否 | 否 | 文件名 |
| 3 | path | varchar | 255 | 否 | 否 | 访问路径 |
| 4 | file | varchar | 255 | 否 | 否 | 文件路径 |
| 5 | display | varchar | 255 | 否 | 否 | 显示顺序 |
| 6 | father_id | int | 否 | 否 | 父级ID | |
| 7 | dir | varchar | 255 | 否 | 否 | 文件夹 |
| 8 | type | varchar | 32 | 否 | 否 | 文件类型 |
表 4-22-user(用户账户)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | user_id | int | 是 | 是 | 用户ID | |
| 2 | state | smallint | 是 | 否 | 账户状态:(1可用|2异常|3已冻结|4已注销) | |
| 3 | user_group | varchar | 32 | 否 | 否 | 所在用户组 |
| 4 | login_time | timestamp | 是 | 否 | 上次登录时间 | |
| 5 | phone | varchar | 11 | 否 | 否 | 手机号码 |
| 6 | phone_state | smallint | 是 | 否 | 手机认证:(0未认证|1审核中|2已认证) | |
| 7 | username | varchar | 16 | 是 | 否 | 用户名 |
| 8 | nickname | varchar | 16 | 否 | 否 | 昵称 |
| 9 | password | varchar | 64 | 是 | 否 | 密码 |
| 10 | | varchar | 64 | 否 | 否 | 邮箱 |
| 11 | email_state | smallint | 是 | 否 | 邮箱认证:(0未认证|1审核中|2已认证) | |
| 12 | avatar | varchar | 255 | 否 | 否 | 头像地址 |
| 13 | open_id | varchar | 255 | 否 | 否 | 针对获取用户信息字段 |
| 14 | create_time | timestamp | 是 | 否 | 创建时间 |
表 4-23-user_group(用户组)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | group_id | mediumint | 是 | 是 | 用户组ID | |
| 2 | display | smallint | 是 | 否 | 显示顺序 | |
| 3 | name | varchar | 16 | 是 | 否 | 名称 |
| 4 | description | varchar | 255 | 否 | 否 | 描述 |
| 5 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 6 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 7 | source_id | int | 是 | 否 | 来源ID | |
| 8 | register | smallint | 否 | 否 | 注册位置 | |
| 9 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 10 | update_time | timestamp | 是 | 否 | 更新时间 |
招聘信息推荐系统的详细设计与实现主要是根据前面的招聘信息推荐系统的需求分析和招聘信息推荐系统的总体设计来设计页面并实现业务逻辑。主要从招聘信息推荐系统界面实现、业务逻辑实现这两部分进行介绍。
-
- 前端首页模块
首页提供了网站的基本导航和多样化的内容展示。页面包括轮播图、导航栏、招聘资讯、职位推荐、求职相关好文和搜索框等功能。用户可以在首页快速浏览最新的招聘信息、行业动态,或者进行职位搜索,快速找到感兴趣的岗位。跳转链接可以引导用户进入第三方平台投递简历。前台首页模块展示如下图所示。
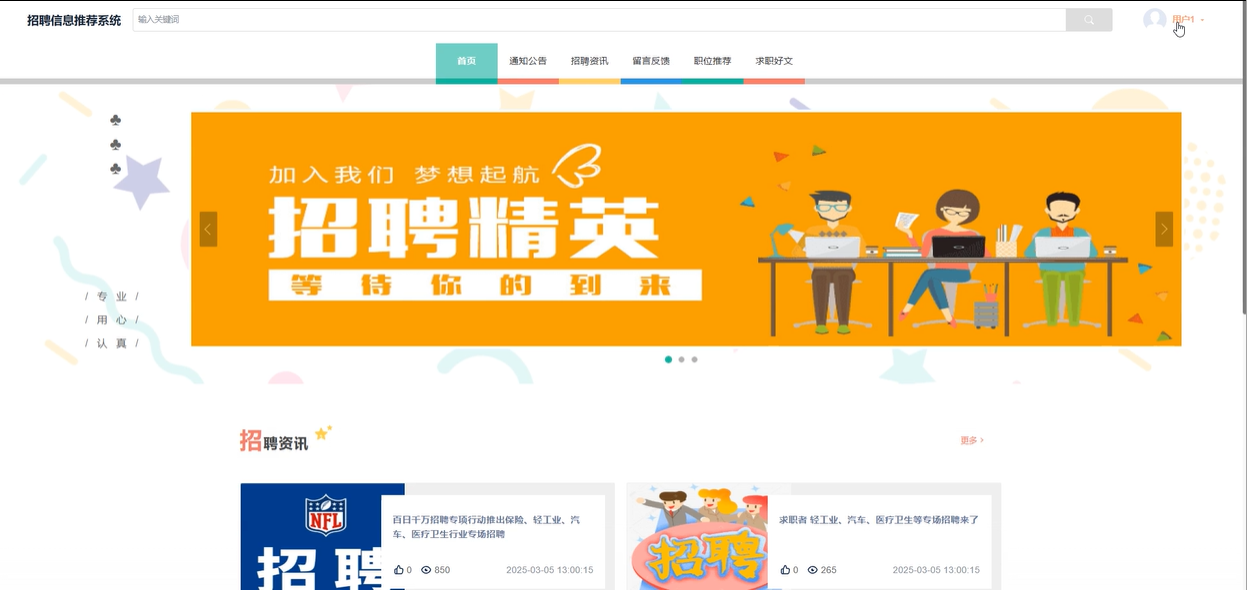
-
-
-
-
- 前台首页模块图
-
-
- 用户注册模块
-
不是招聘信息推荐系统中正式用户的是可以在线进行注册的,当填写上自己的账号+设置密码+确认密码+昵称+邮箱+身份+用户姓名+用户性别+手机号+求职标签等信息后再点击“注册”按钮后将会先验证输入的有没有空数据,再次验证密码和确认密码是否是一样的,最后验证输入的账户名和数据库表中已经注册的账户名是否重复,只有都验证没问题后即可用户注册成功。其用户注册模块展示如下图所示。
-
-
-
-
- 注册模块图
-
-
- 登录模块
-
招聘信息推荐系统中的前台上注册后的用户是可以通过自己的用户名+密码进行登录的,当用户输入完整的自己的用户名+密码信息并点击“登录”按钮后,将会首先验证输入的有没有空数据,再次验证输入的用户名+密码和数据库中当前保存的用户信息是否一致,只有在一致后将会登录成功并自动跳转到招聘信息推荐系统的首页中,否则将会提示相应错误信息,登录模块如下图所示。
-
-
-
-
- 登录模块图
-
-
- 前端普通用户功能模块
-
用户可以浏览详细的招聘资讯,包括职位要求、公司信息等,并能够对感兴趣的资讯进行点赞、收藏、评论或回复。用户还可以通过搜索功能找到自己关注的招聘信息。所有的评论和回复都可以进行删除操作。模块如下图所示:
用户可以在留言反馈栏目发布反馈信息,包括标题和留言内容。提交后,管理员可以查看和处理这些留言,以改善用户体验。模块如下图所示。
职位推荐功能允许用户查看职位的详细信息,包括职位类型、求职标签、工作地点、学历要求、薪资待遇等。用户可以通过搜索功能快速找到感兴趣的职位,并进行数据对比,帮助做出更合适的选择。此外,用户还可以对职位进行点赞、收藏、评论以及回复,所有操作都支持删除功能。通过系统的智能推荐,职位将根据用户的标签和兴趣进行个性化推送,用户还可以进入职位详情页进行简历投递。模块如下图所示。
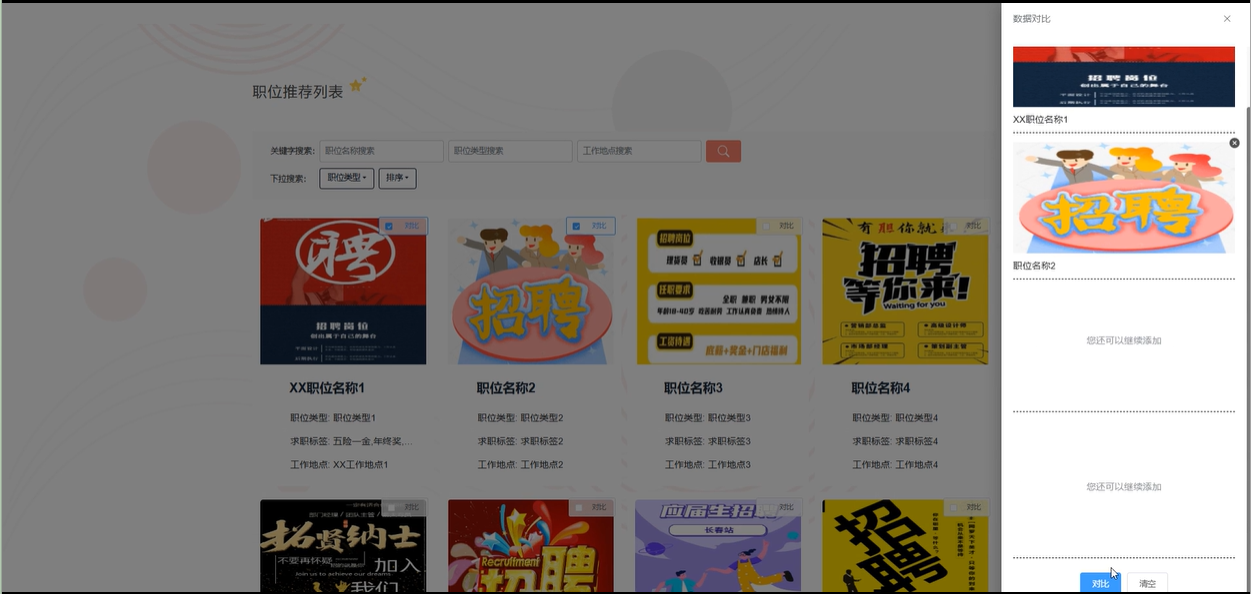
-
-
-
-
- 职位推荐模块图
-
-
-
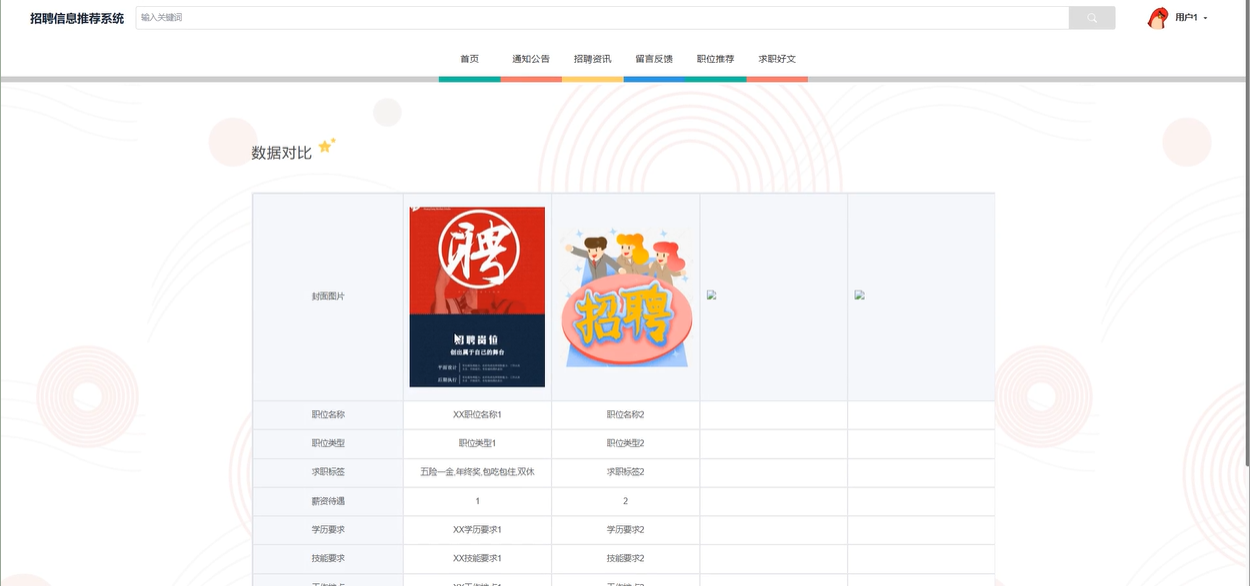
-
-
-
-
- 查看数据对比模块图
-
-
-
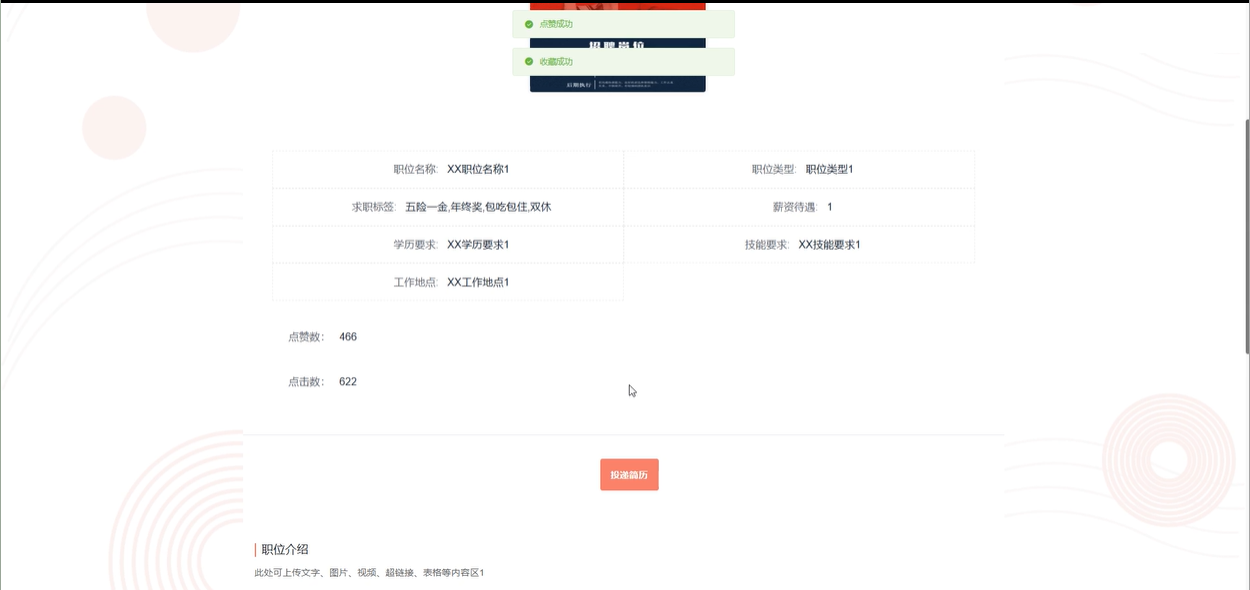
-
-
-
-
- 职位推荐详情模块图
-
-
-
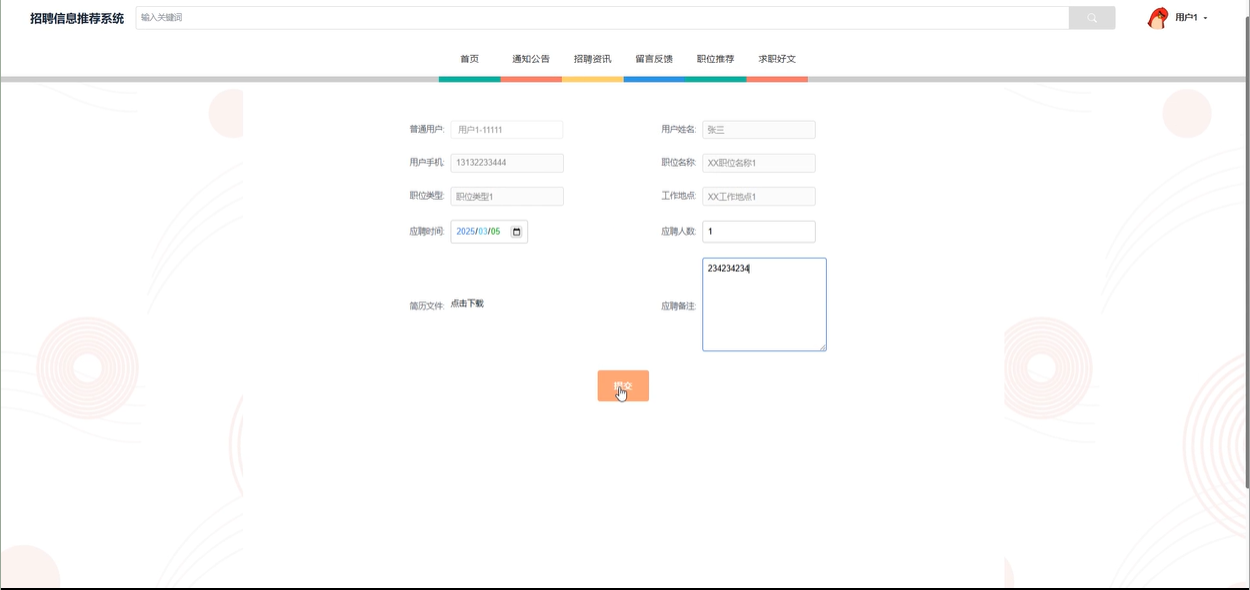
-
-
-
-
- 提交投递简历模块图
-
-
-
用户可以浏览求职相关的文章和资源,查看文章的详细内容,并根据自己的专业背景进行筛选。用户可以下载简历文件、点赞、收藏、评论或回复这些文章,提升自己的求职技巧和准备。模块如下图所示。
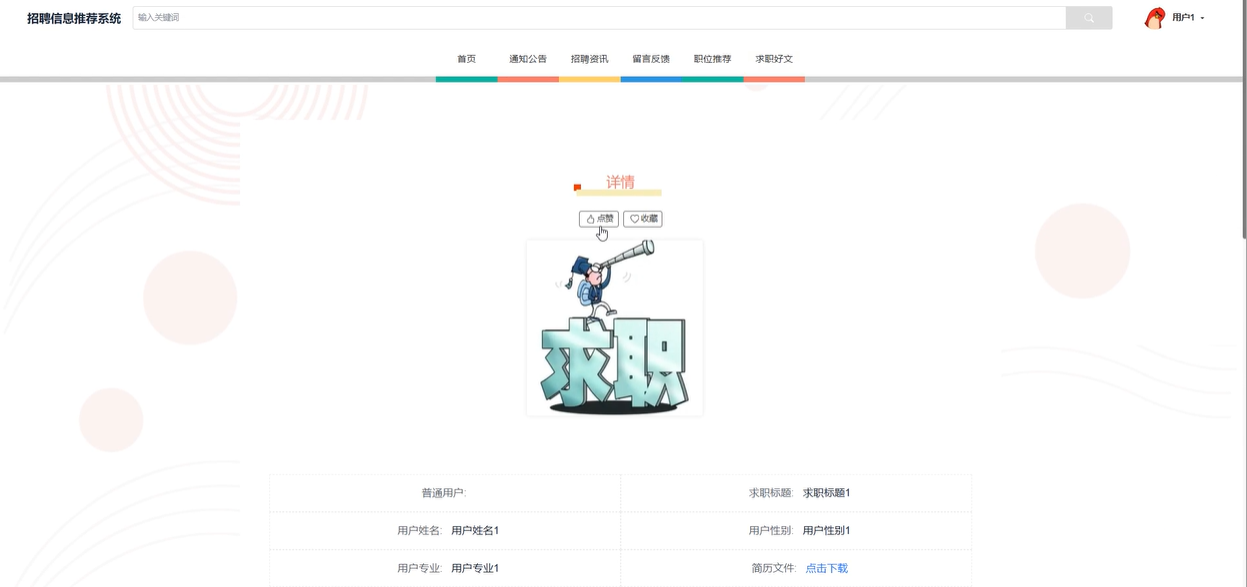
用户可以查看自己投递简历的记录,查询审核状态、查看是否通过等,并下载简历文件。用户可以对每条应聘记录进行搜索、查询、重置等操作。模块如下图所示。

用户可以查看求职好文的详情,查看文章中的评论,并进行相关操作如搜索、增删改查文章内容。此功能帮助用户获取更多的求职知识和资讯。模块如下图所示。
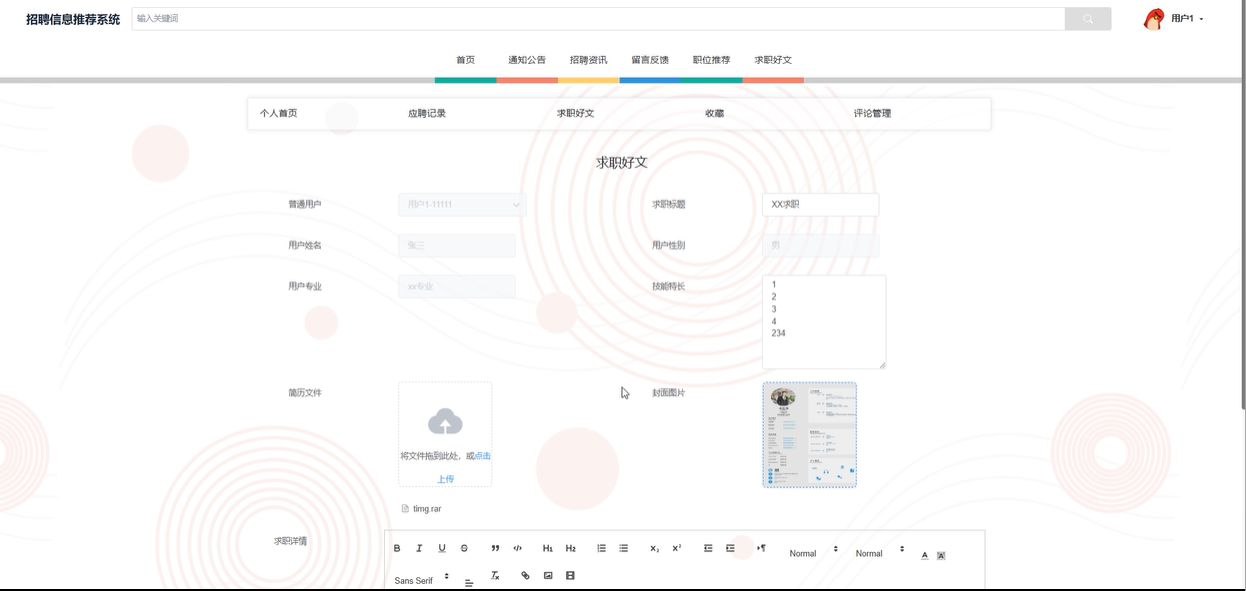
-
-
-
-
- 添加求职好文模块图
-
-
- 后端管理员功能模块
-
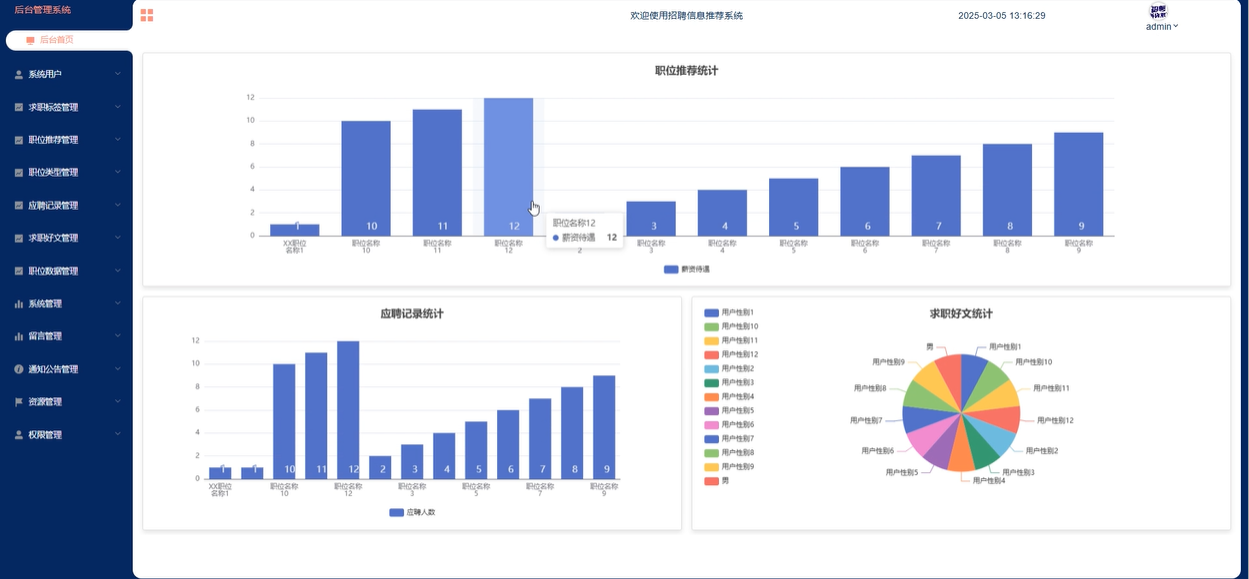
管理员可以通过后台首页查看职位推荐统计、应聘记录统计、求职好文统计等数据,通过折线图和圆形图等形式展示关键指标。管理员可以根据这些数据作出业务调整,同时也可以修改个人资料和密码。模块如下图所示。
管理员可以管理系统中的所有用户,包括普通用户和管理员。管理员可以查看用户的详细信息,并进行搜索、增删改查操作,确保用户信息的准确性和及时更新。流程图如下所示。

-
-
-
-
- 系统用户管理流程图
-
-
-
系统用户模块如下图所示。
管理员可以查看、添加、删除和管理求职标签。通过求职标签,系统可以根据用户需求对职位进行更精确的推荐。模块如下图所示。
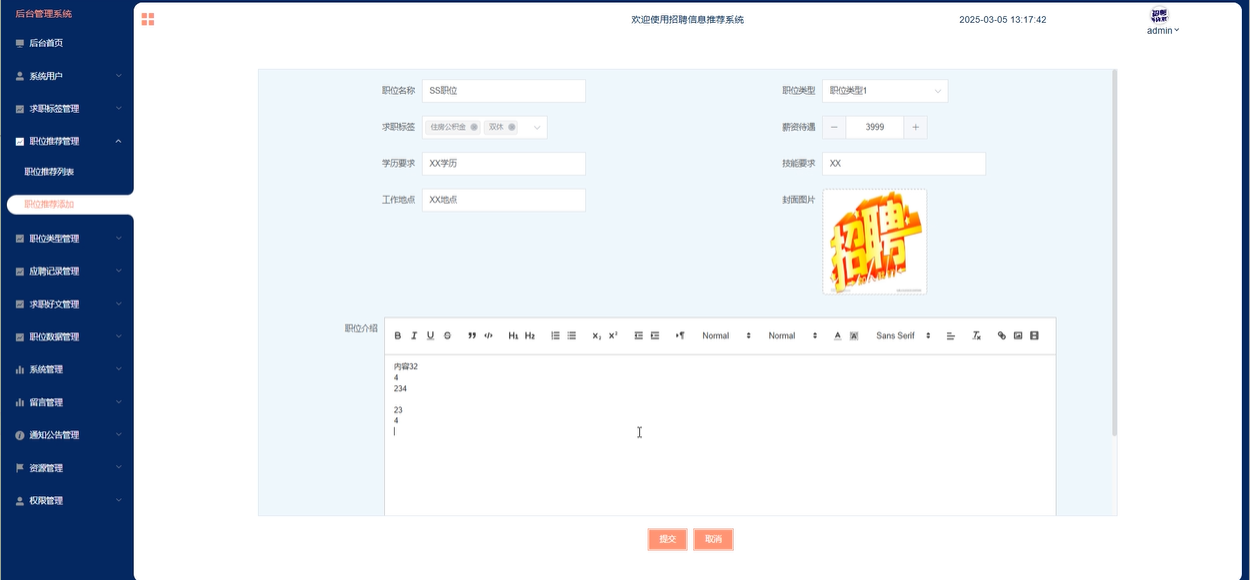
管理员可以查看职位推荐的详细信息,包括职位内容、评论、推荐状态等。管理员可以对职位进行添加、修改、查询、删除等操作,确保职位信息的准确性和完整性。模块如下图所示。
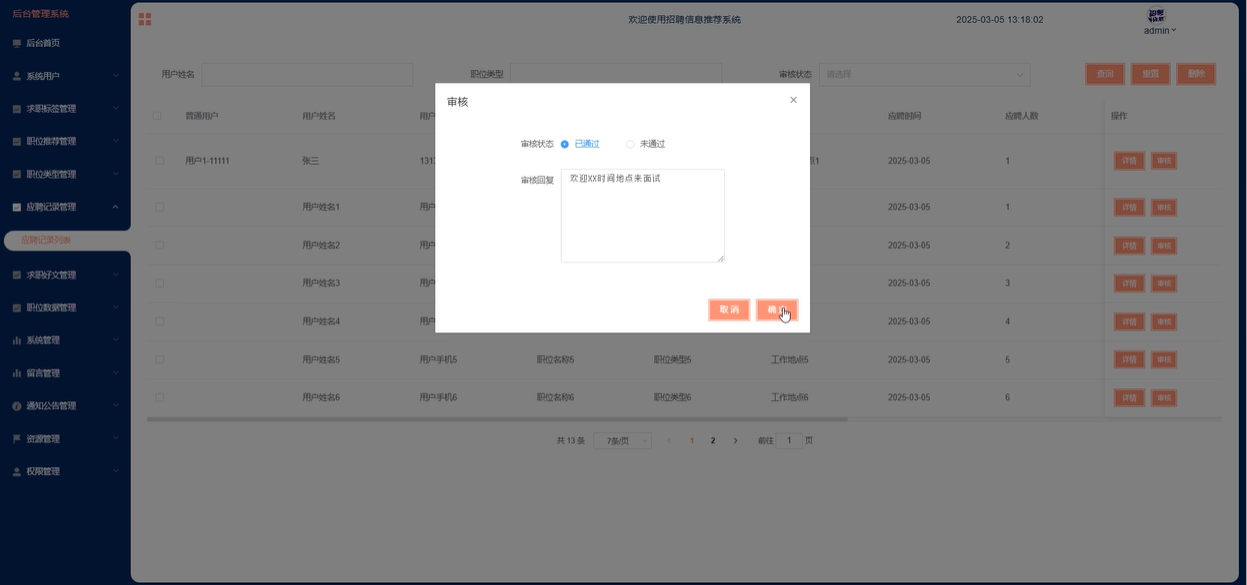
管理员可以查看所有用户的应聘记录,包括审核和管理用户投递的简历。管理员可以对每条应聘记录进行搜索、查询、重置、删除等操作。模块如下图所示。
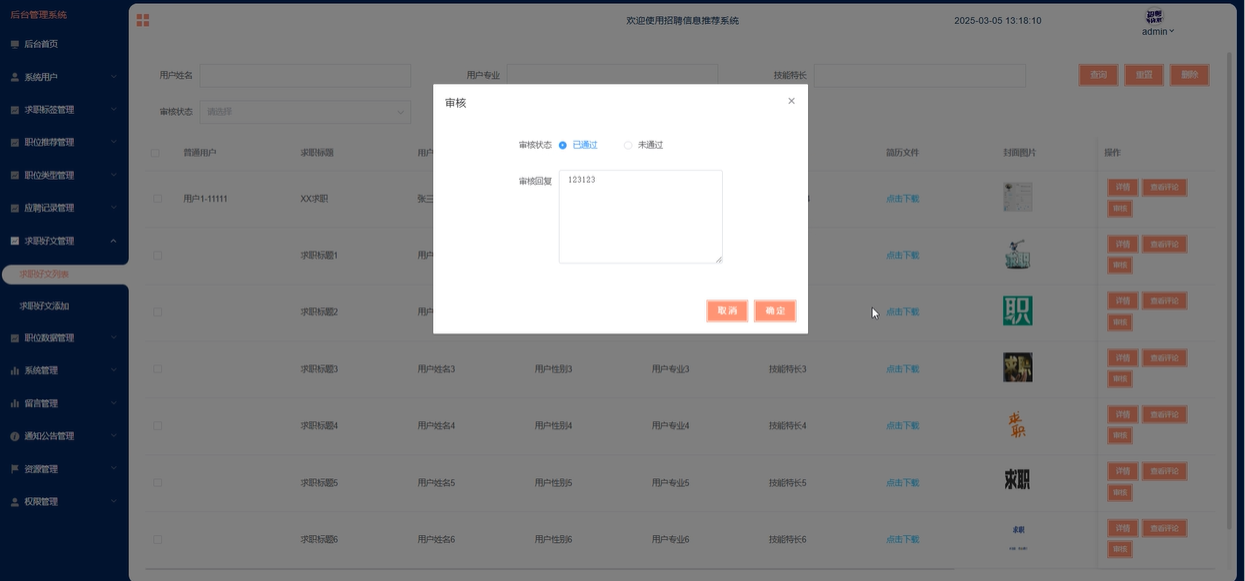
管理员可以查看求职好文的详细信息、评论、审核状态等,并进行搜索、添加、修改、删除等操作。管理员可以管理文章的发布和内容,确保用户获取到有价值的求职信息。模块如下图所示。
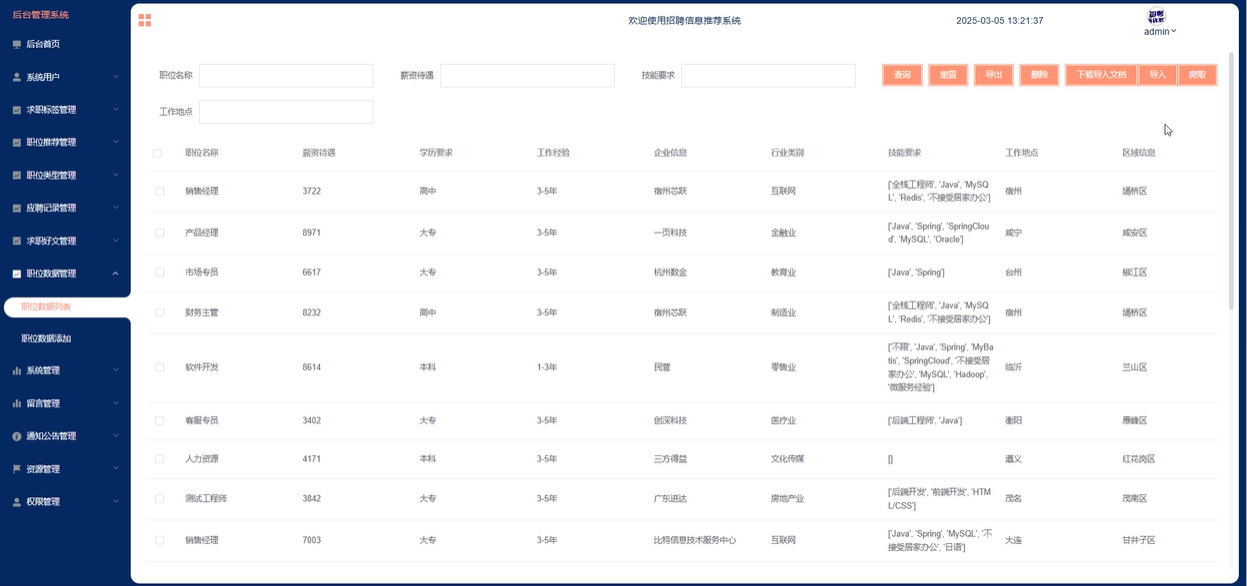
管理员可以查看和管理职位数据,包括职位详情、添加职位、删除职位等。管理员可以导出职位数据,下载导入文档,还支持通过爬虫技术一次性爬取多个招聘数据,极大地提高招聘信息的更新速度。模块如下图所示。
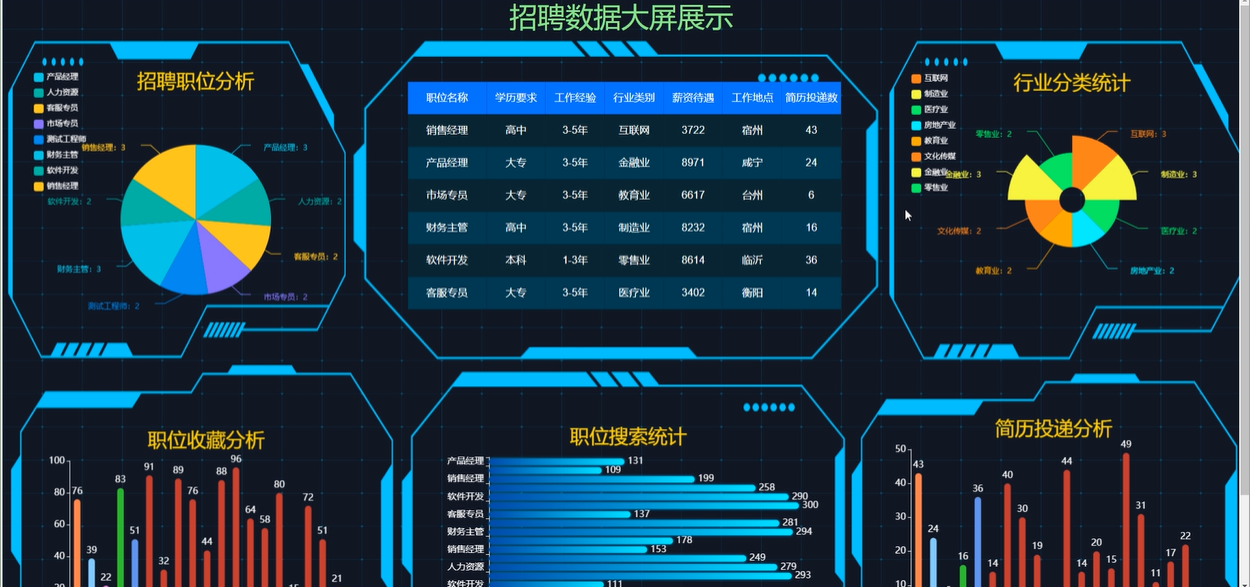
管理员可以通过可视化大屏展示招聘数据,包括职位推荐分析、行业分类统计、职位收藏分析、职位搜索统计、简历投递分析等。管理员可以通过这些数据分析,调整招聘策略,提高招聘效果。模块如下图所示。
-
-
-
-
- 招聘数据大屏展示模块图
-
-
-
测试的主要目的是确保系统的功能和性能满足预期的需求,同时识别和修复潜在的缺陷。通过系统测试,可以验证各个功能模块的正确性和稳定性,确保系统在不同使用场景下的表现符合设计要求。测试目的包括确认系统功能的完整性、验证数据处理的准确性、评估系统的性能和安全性。测试还可以提高用户满意度,保证用户在使用系统时获得流畅和可靠的体验。通过全面的测试,可以降低后期维护成本,减少系统上线后出现故障的风险,从而保障系统的长期稳定运行。
在本系统中,测试方法主要依赖于测试用例的设计与执行。测试用例是根据系统需求文档编写的,覆盖所有功能模块及其边界情况。每个测试用例包含输入数据、预期结果和实际结果的对比,以验证系统的功能是否按预期工作。
常见的测试用例包括功能测试用例、边界测试用例和异常测试用例。功能测试用例针对系统的各项功能进行验证;边界测试用例则侧重于输入数据的边界条件,验证系统在极端情况下是否能够稳定运行;异常测试用例则用于验证系统在处理错误输入或异常情况时的反应。本文选择功能测试用例进行系统测试。
在测试执行过程中,记录每个用例的执行结果,并根据实际结果与预期结果的对比,判断系统是否存在缺陷。通过系统化的测试用例执行,可以有效提高测试的覆盖率和效率,为系统的最终上线提供保障。
表6-1 用户登录功能测试表
| 用例名称 | 用户登录系统 |
| 目的 | 测试用户通过正确的用户名和密码可否登录功能 |
| 前提 | 未登录的情况下 |
| 测试流程 | 1) 进入登录页面 2) 输入正确的用户名和密码 |
| 预期结果 | 用户名和密码正确的时候,跳转到登录成功界面,反之则显示错误信息,提示重新输入 |
| 实际结果 | 实际结果与预期结果一致 |
在系统中,创建功能也是基础功能之一,因此创建功能的测试很有代表性。在此章节主要列举在创建时各种情况下系统结果的测试。由于系统涉及创建功能操作过多,因此将多处统称创建功能。
创建数据用例如表6-2 所示。
表6-2 创建数据测试用例
| 测试用例编号 | YL_05 | |
| 测试用例名称 | 系统使用者进行创建数据 | |
| 测试用例描述 | 使用者输入要创建的数据 | |
| 系统入口 | 浏览器 | |
| 步骤 | 预期结果 | 实际结果 |
| 输入完整并且格式正确的数据 | 提示“创建成功”,并显示所有数据 | 预期结果 |
| 核心位置数据但非必要位置不输入数据 | 提示“创建成功”,并显示所有数据 | 预期结果 |
| 核心数据位置不输入数据 | 提示“创建失败” | 预期结果 |
-
-
- 修改数据测试
-
在系统中,修改功能是系统主要实现功能,因此修改功能的测试很有代表性。在此章节主要列举在修改时各种情况下系统结果的测试。由于系统涉及修改功能操作过多,因此将多处数据表记录修改和状态修改统称修改功能。
修改数据用例如表6-3所示。
表6-3 修改数据测试用例
| 测试用例编号 | YL_06 | |
| 测试用例名称 | 系统使用者进行修改数据 | |
| 测试用例描述 | 使用者对可修改的数据项进行修改 | |
| 系统入口 | 浏览器 | |
| 步骤 | 预期结果 | 实际结果 |
| 将现有数据修改成正确的数据 | 提示“修改成功”,并显示所有数据 | 预期结果 |
| 将现有数据修改成错误的数据 | 提示“修改失败” | 预期结果 |
-
-
- 查询数据测试
-
在系统中,查询功能是使用系统使用最多也是最基础的功能,因此查询功能的测试很有代表性。在此章节主要列举在查询时各种情况下系统结果的测试。
查询数据用例如表6-4所示。
表6-4 查询数据测试用例
| 测试用例编号 | YL_05 | |
| 测试用例名称 | 系统使用者进行查询数据 | |
| 测试用例描述 | 全部查询以及输入关键词查询 | |
| 系统入口 | 浏览器 | |
| 步骤 | 预期结果 | 实际结果 |
| 界面自动查询全部 | 显示对应所有记录 | 预期结果 |
| 输入已存在且能匹配成功的关键字 | 显示所查询到的数据 | 预期结果 |
| 输入不存在的关键字 | 显示数据界面为空 | 预期结果 |
在本次测试的过程主要针对所有功能下的添加操作,修改操作和删除操作,并以真实数据一一进行相关功能项目的输入,最终能够保证每个项目涉及的功能都能够正常运行,因此能够保证本次设计的,已实现的功能能够正常运行并且相关数据库的信息也同样保证正确。
本论文基于Spark框架设计并实现了一个招聘信息推荐系统。通过利用Spark的分布式计算能力,系统能够高效处理大量招聘数据,实时生成个性化的职位推荐。系统结合了职位信息、用户行为数据和用户标签,通过精准的匹配算法,为用户推荐最符合需求的职位。这种方法大大提高了招聘效率,为求职者提供了更精确的职位选择,提升了整体用户体验。
在系统实现过程中,经历了从数据采集、预处理到推荐算法实现的完整过程。通过对不同职位类型、求职标签等数据的分析,系统能够优化推荐策略,并有效处理大规模数据,确保推荐结果的准确性与实时性。此外,系统也提供了多种互动功能,如职位点赞、评论、收藏等,增加了用户的参与度。通过该系统的实现,积累了许多在大数据环境下处理推荐任务的宝贵经验。
展望未来,随着数据量的不断增加,系统还可以进一步优化推荐算法,结合更多的数据源来提高推荐的精准度与个性化程度。随着招聘市场的发展,系统也能够适应不断变化的用户需求,为求职者和招聘企业提供更加智能化、高效的服务。
- 黄维.基于B/S模式的虚拟网络实验室安全管理体系分析[J].信息系统工程,2024,(05):4-7.
- 张宇薇.HTML5在Web前端开发中的应用[J].集成电路应用,2024,41(04):274-276.
- 施志龙,陈赣,谢国良. 一种基于spark的边缘云大数据分析算法研究 [J]. 长江信息通信, 2024, 37 (02): 183-185.
- 沈伍强,沈桂泉,许明杰,等. 一种基于Spark的配置优化技术 [J]. 微型电脑应用, 2024, 40 (02): 93-96+105.
- 李艳杰.MySQL数据库下存储过程的综合运用研究[J].现代信息科技,2023,7(11):80-82+88.
- 肖睿,李鲲程,范效亮,等.MySQL数据库应用技术及实践[M].人民邮电出版社:202206.228.
- 明日科技.快速上手Python[M].化学工业出版社:202211.337.
- 明日科技.Python Web开发手册[M].化学工业出版社:202201.411.
- 赵艳花. Spark大数据智能分析平台设计研究 [J]. 信息记录材料, 2025, 26 (01): 76-78+84.
- 庞敏. MySQL数据库的数据安全应用设计技术研究 [J]. 数字通信世界, 2024, (09): 25-27.
- Stokes D . Update or migrate? Planning for MySQL 5.7 EOL [J]. InfoWorld.com, 2023, 24 (03): 22-30.
- Guo Z ,Wang H ,He J , et al. PSLSA v2.0: An automatic Python package integrating machine learning models for regional landslide susceptibility assessment [J]. Environmental Modelling and Software, 2025, 186 106367-106367.
- Kabou S ,Gasmi L ,Kabou A , et al. ImDMI: Improved Distributed M-Invariance model to achieve privacy continuous big data publishing using Apache Spark [J]. Big Data Research, 2025, 40 100519-100519.
- 张薇薇. 供需耦合视角下的财务大数据分析课程内容构建——基于线上招聘信息的数据分析 [J]. 现代商贸工业, 2025, (07): 165-168. DOI:10.19311/j.cnki.1672-3198.2025.07.053.
- 彭玉芳,王双双. 大数据时代信息管理专业人才需求分析与应对策略 [J]. 江苏科技信息, 2024, 41 (23): 93-98.
- 朱瑜. 网络招聘中个性化职位推荐算法的研究与分析[D]. 贵州民族大学, 2023.
- 孙佳馨. 基于知识图谱的招聘面试信息推荐方法研究[D]. 哈尔滨工业大学, 2023.
- 王金威. 基于大数据分析的高校云招聘信息个性化推送研究 [J]. 安徽电子信息职业技术学院学报, 2022, 21 (04): 25-31.
- 代小会. 基于双边用户评价的网络招聘平台信息推荐服务评价研究[D]. 浙江师范大学, 2022.
- 施元鹏. 基于文本相似度的简历与招聘信息的双向匹配推荐算法的研究[D]. 南京邮电大学, 2021.
招聘信息推荐系统设计与实现工作已结束,虽然过程中充满挑战,但内心充满自豪和满足。感谢大学四年间教导我的所有老师,他们的专业知识与人生智慧让我成长为能独立完成系统的学生。特别感谢指导老师,他耐心解答疑惑,引导我解决问题,提升自主解决能力。室友和同学们的宝贵建议和支持也让我取得长足进步。未来,我将继续努力追求卓越,不辜负所学所悟和老师期望。坚信坚定信念和不懈努力,未来定能取得更辉煌成就。期待更美好未来!
招聘信息推荐系统设计与实现不仅是技术挑战,挫折和困难是成长的垫脚石,让我更深入理解问题,精确找到解决方案。每次解决问题,都感到满足和自豪。
对于未来,我充满期待和信心。无论道路多崎岖,只要保持坚定信念,持续努力,定能取得更大成就。期待将知识和技能运用到实际中,为社会做出更大贡献。
最后,感谢所有帮助和支持我的人。你们的教诲、鼓励和支持让我有今天的成就。我会继续努力,不辜负期望,为实现更美好的未来而奋斗。
免费领取项目源码,请关注❥点赞收藏并私信博主+v,谢谢~

















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









