



一种与无人机结合的人机界面
D. Soto‐Gerrero 和 J.‐G. 拉米雷斯‐托雷斯
摘要
许多无人机应用依赖地面计算机完成所有处理任务,而这些系统的功耗在便携性方面构成了主要障碍。由于该界面的主要目标之一是实现无处不在的使用,我们将所有计算负载转移到运行安卓系统的移动设备上。本文介绍了一种高效且实用的无人机(UAV)人机界面。该无人机能够响应用户的移动和身体手势。
关键词 无人机(UAV) Human-robot interaction Gesture识别 Particle滤波器
1 引言
本文提出并描述的界面有助于实现无人机(UAV)与未经训练的人员之间的多种社交互动。该界面无需依赖任何类型的遥控硬件即可运行,且用户无需掌握操控无人机的方法。从技术上讲,为此界面开发的软件通过视频流解读用户的动作,并将其转化为控制命令。为了运行该软件,我们使用了移动设备,因为它们已具备更自然的触摸功能交互方式,并且在日常常见任务中正逐渐取代个人计算机。此外,我们避免在用户身上使用明显的标记物,以保持交互尽可能自然。
先前的一项研究表明,人机交互研究忽视了社会性和共处性方面,而当自主飞行机器人在社交活动中进一步发展时,这将对未来产生影响[1]。他们试图通过使用巫师式技术来摆脱遥控交互:测试对象向无人机做出手势,而一名隐蔽的操作员无线控制无人机。他们证明了儿童和成年人都会对无人机产生情感依恋,将其视为一个实体[2]。
在最近关于无人机人机交互的研究中,我们可以引用东京大学提出的一项运动助手[3]。该研究使用搭载摄像头的无人机跟随运动员,提供所谓的外部视觉影像。运动员不再需要从外部观察者的视角来想象自己的动作,以评估自身的技能、策略和比赛计划。所有这些信息都通过头戴式显示器由无人机传递给运动员。他们使用粒子滤波器在视频流中跟踪用户夹克的颜色。
尽管该研究依赖于笔记本电脑或台式机,并且未详细描述其跟踪算法的实现和性能,但他们成功地测试了将无人机作为运动助手的应用,尽管外部视觉影像使运动员感到头晕。
还有其他方法可以实现人与无人机之间的交互,这些方法需要大量计算能力。例如,在实现与无人机的交互时,可以跟踪用户的面部和手势,但在实际飞行之前必须先初始化无人机参考坐标系[4];在光照条件良好的情况下,使用颜色标记有助于区分控制无人机集群的所有指令[5]。类似的结果也可以通过Kinect传感器及其相应的软件库获得[6]。
2 人‐无人机接口
本节我们将介绍界面的硬件、软件和控制方案。本质上,无人机通过其机载摄像头捕捉用户的指令,并在用户持有的一个移动设备上处理所有指令。
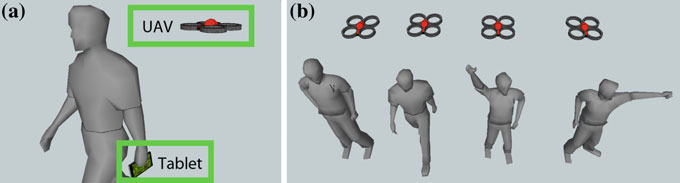
该软件能够通过来自无人机的视频流估算用户的动作和手势(图1a);同时还能估算用户相对于无人机的位置,以控制飞行器并使其跟随和解读用户的动作和手势(图1b)。
我们使用了Parrot AR‐无人机,一种Wi‐Fi控制的四旋翼飞行器,来开发此界面。通信通过UDP端口完成,用于发送和接收:用于操控无人机的控制命令(UDP 5556)、描述无人机当前状态的导航数据(UDP 5555),以及视频流(UDP 5554)。作为移动处理平台,我们选择了配备Tegra 3处理器的华硕Transformer Prime,这是英伟达推出的全球首款四核移动处理器。关于如何利用平板架构的更多内容将在下一节中介绍。
我们从零开始构建了一个名为IHRVANT的应用程序,这是一个多线程应用程序,负责初始化、维护和关闭与无人机的通信。前四个线程分别负责图形用户界面、控制命令、导航数据和视频流接收(见图2)。视频接收线程更为复杂,因为它管理所有图像处理线程,这些线程实现了跟踪算法和手势识别功能。
视频数据流从无人机发送到移动设备,采用通用变长编码进行编码,具有以下特征:YCbCr色彩空间4:2:0子采样,8 × 8DCT,分辨率QVGA。由于我们的数字图像处理(DIP)技术基于YCbCr色彩空间,解码器仅在DIP线程空闲时才将所有颜色通道直接输送给DIP线程。通过该策略,视频流可无瑕疵地显示,同时DIP线程处理最新接收的帧。所有参数均可通过IHRVANT界面中的控制功能进行管理。
3 跟踪算法
本节描述了我们如何跟踪用户的上半身轮廓以进行后续分类并实现手势识别。
为了跟踪用户的上半身轮廓,我们使用用户夹克的颜色作为标记,记为c 。已知视频解码器使用YCbCr颜色空间,因此我们利用色度通道(Cb;Cr)来定义和跟踪c 。对于每一帧中的任意像素,如果其对应的色度数据c = (cb; cr)与参考值c = (c b; c*r)之间的欧几里得距离d()小于阈值Tc,则对该像素进行分割(见公式1)。
$$
C_s(x, y) =
\begin{cases}
1 & \text{if } d(c(x,y), c^
) < T_c \
0 & \text{if } d(c(x,y), c^
) > T_c
\end{cases}
\quad (1)
$$
事实上,每个帧的尺寸提高了移动平台上的分割性能。亮度和色度通道进行了下采样(第2节),这意味着每个通道的分辨率为:Y通道为QVGA分辨率,而Cb和Cr通道均为QQVGA。
此外,亮度通道提供了重要的对比度信息,从Y通道分割出的灰度色调应位于一个固定的区间[y − 15; y + 15]内,其中y 表示用户夹克的灰度色调(公式2)。为了适应亮度变化,y 由IHRVANT以1 Hz的频率持续更新。
$$
Y_s(x, y) =
\begin{cases}
1 & \text{if } (y^
- 15) \leq Y(x,y) \leq (y^
+ 15) \
0 & \text{otherwise}
\end{cases}
\quad (2)
$$
之前提到的颜色和灰度分割策略容易导致不理想的误报。换句话说,并非所有分割出的像素都必然属于用户在视频帧中的真实位置。为了克服这一问题,同时增强对部分遮挡的鲁棒性,我们将颜色分割区域的结果与粒子滤波器进行了融合。
跟踪算法种类繁多,其中概率算法(如粒子滤波器)已被用于跟踪彩色物体[7, 8],部分算法已使用AR无人机的前置摄像头实现[3]。粒子滤波器通过一组来自先前变量观测的加权样本(即粒子)来估计变量的分布函数。
该方法采用大小为I的加权粒子集Xt,基于每个粒子权重进行采样是此技术如此重要的原因[9]。在本案例中,我们的观测过程对应于每一帧中感兴趣区域所在的坐标。我们通过让所有粒子利用视频流中的Cb和Cr通道跟踪一个特定的颜色直方图来实现这一点。颜色直方图可被视为一个二维表,其中所有像素根据其属性被分类,每个色度通道对应的色度值和n个离散区间,总共得到n²个区间。
我们实现中的第一个重要方面是,如何将每个粒子定义为一个边长为l的正方形区域Wi,其中心位于时间t的坐标(xt; yt)处。每个粒子的状态向量定义为xt = (xt; yt; xt−1; yt−1)ᵀ。
其次,我们用于采样变量先验假设状态~xt+1的状态转移分布不需要所有先前的观测值。我们假设目标在每一帧中做匀速运动,因此仅需最近的两次观测值xt−1和xt;这称为二阶动态模型(见公式3,vt ~ N(0; r))[10]。
$$
\tilde{x}_{t+1} =
\begin{bmatrix}
2 & 0 & -1 & 0 \
0 & 2 & 0 & -1 \
1 & 0 & 0 & 0 \
0 & 1 & 0 & 0 \
\end{bmatrix}
x_t +
\begin{bmatrix}
1 & 0 \
0 & 1 \
0 & 0 \
0 & 0 \
\end{bmatrix}
v_t
\quad (3)
$$
第三个重要方面是我们如何对所有粒子加权;我们通过巴塔恰里亚相似系数(公式4)计算从Wi中提取的归一化颜色直方图qt与归一化参考颜色直方图(q )之间的相似性。正如佩雷斯等人[11]所指出的,我们也观察到平方距离D²具有一致的指数行为,因此我们使用公式5对所有粒子(k = 20)进行加权。随后以抽取概率∝ p(xt+1|~xt+1; qt+1)进行重采样,足以使所有粒子表现得如同寻找蜂蜜的蜜蜂一般,都试图匹配参考颜色直方图q 。
$$
D[q^
, q_t(x_t, y_t)] = 1 - \sum_{n=1}^{N} \sqrt{q^
(n) q_t(x_t, y_t)(n)} ^{1/2}
\quad (4)
$$
$$
p(x_{t+1}|\tilde{x}
{t+1}, \tilde{q}
{t+1}) \propto \exp(-k D^2[q^*, \tilde{q}_{t+1}])
\quad (5)
$$
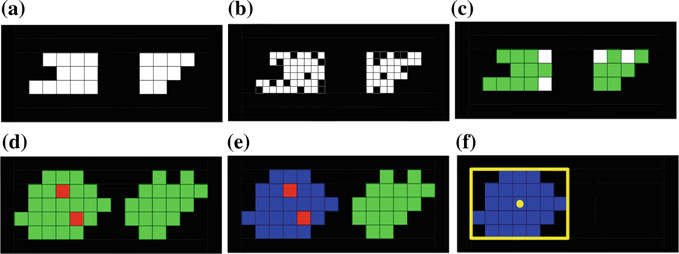
最后,为了融合颜色(Cs)和灰度分割(Ys)区域以及粒子集Xt,我们使用了形态学操作。我们认为只有当3个或更多Y像素被点亮时,颜色分割像素才有用,这些在图3c中以绿色标记。经过一次使用菱形结构元素(3 × 3)的膨胀操作后,我们叠加了所有粒子,以便利用粒子作为障碍物、自由空间作为颜色分割区域来应用火灾蔓延算法[12](图3e)。我们去除了火未到达的区域(图3f),从而消除了所有误报(如图3e中绿色所示)。图4c显示了IHRVANT如何以蓝色显示融合结果、分割区域的质心(Bc)及其边界框(Bbb)以黄色显示。在正常运行期间,蓝色区域对应于视频帧中用户的位置,并代表其上半身轮廓,我们可以对其进行分类以实现身体动作识别。

4 手势识别
为了对用户的上半身轮廓进行分类,我们使用基于归一化直方图的描述符,并根据AR无人机估计的相机滚动角对该描述符进行重新定向;通过吸收正常飞行条件下引起的轻微误导性旋转,我们显著提高了描述符的准确性。
为了计算该描述符,首先将感兴趣区域Bbb根据滚动角缩放并重新定向为一个固定大小的位图Bs(见图4c)。B₀s的宽度和高度(分别为ws和hs)应符合人体比例。在我们的测试中,采用ws : 2.5hs的比例足以描绘当手臂水平或靠近身体时的人体上半身比例。我们首先将边界框的高度(hbb)缩放以匹配B₀s(高度缩放因子s = hbb / hs),同时将Bc平移到Bs的中心;然后,根据无人机的滚动状态变量,以上半身轮廓的中心为旋转中心对缩放后的区域进行旋转。在图4c中,我们展示了完成缩放、平移和旋转后对应的Bs位图。
我们的描述符基于归一化直方图,从Bs我们获得其垂直和水平直方图,进而可以合并为一个归一化的直方图h(见图4b)。分类器使用用户在无人机摄像头前保持姿势时,每隔1.2秒采集的31个样本的平均值进行训练;该平均直方图h*成为训练手势的描述符。当有两个或更多已训练的手势时,分类器开始使用公式(6)计算任意给定描述符与所有可用手势之间的平方误差。换句话说,当有两个或更多已训练的手势时,所有Bs图像将以分割过程输出结果的相同速率进行分类,即每秒14次。误差最小的手势将被视为最佳匹配。IHRVANT以条形图显示所有计算出的误差,获胜者的标签以红色显示给用户(见图4c)。
$$
e = \sum_{i=1}^{N} (h^*_i - h_i)^2
\quad (6)
$$
IHRVANT支持最多四种不同的手势,如果上半身轮廓被连续分类识别一秒半,即手势描述符被连续21次分类为可用手势中的任意一种,则会触发一次有效手势检测事件。图4a展示了所有四种经过测试的手势。
5 控制
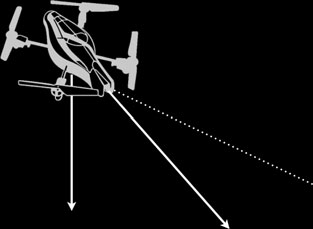
在图5中,我们展示了AR无人机相对于地面的飞行高度(g)以及用于描述任何飞机在空中姿态的三个固定轴。对于这些参考坐标系中的每一个,都有一个我们可以修改的控制变量来控制AR无人机。
如果我们修改与横滚轴相关的变量,AR无人机将向侧面移动,俯仰变量将其向前或向后移动,偏航变量使其旋转,高度变量使其上升或下降。
对于前面提到的每个变量,我们使用了闭环PID控制方案。我们使用从无人机接收到的估计飞行高度作为高度控制器的输入。根据跟踪算法(第3节),我们获得用户的分割区域、边界框尺寸及其质心,由此可以估算用户相对于无人机的位置。在图5中,一个灰色矩形描述了用户可能的位置区域,以及其质心到视频帧中心的距离(r),该结果用作偏航轴控制器的输入。图5显示了两个具有不同高度的灰色区域,分别对应l < h,它们说明用户离无人机越近,h就越大。距离d作为PID控制器用于无人机俯仰轴的输入。
6 结果
欢迎读者观看YouTube上名为“IHRVANT”的视频,该视频展示了无人机如何跟踪用户并对身体手势做出反应;视频中还包含另一个视频链接,展示了我们如何利用平板触控功能来初始化所有分割过程。由于我们的跟踪算法正在视频解码器内部运行,我们达到了足够的性能。
考虑到无人机以18帧每秒发送视频;彩色和灰度分割:14帧每秒,粒子滤波器(I = 200; l = 7; n = 4)7帧每秒,经过所有结果的融合后,我们整体达到了14帧每秒。针对所有四个飞行变量的控制循环(第5节)以与分割过程输出帧相同的速率(14 Hz)在每一计算帧时更新。
在手势分类中,尝试使用[0°到15°]范围内的滚转角,我们对分类器性能进行了统计测量。通过测量被正确识别的实际阳性样本的比例,我们达到了89%的灵敏度。另一方面,通过测量被正确识别的实际阴性样本的比例,我们达到了90%的特异性。值得一提的是,我们并未使用架构特定的指令来实现此性能,包括NEON指令或图形处理器功能。
7 结论
我们提出了一种基于无人机的便携式人机接口的可行实现方案。该系统能够通过视频流在室内成功跟踪用户,对光照条件限制较少,并能适应动态变化的背景;同时,我们还展示了如何在最新的便携式设备上实现基于视觉的控制系统,使其能够在无需高性能计算的情况下自主驱动无人机。
AR无人机无法承载任何显著的额外载荷,这使得我们无法在其上加装外部感知传感器,这也成为了我们未来工作的重点方向。我们的主要努力方向源于这样一个理念:机器人终将逐步融入我们的日常社会交互中。


















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









