






 本文详细探讨了Linux内核中的关键概念,包括系统调用的分类和实现、内核数据结构如链表和映射、中断处理的类型与机制,以及中断下半部的处理方式如软中断、TaskLet和工作队列。此外,还介绍了内核同步与互斥的机制以及定时器和时间管理。最后,概述了Linux进程的生命周期、调度算法和内存虚拟地址空间的划分与管理。对于深入学习Linux内核的读者,这篇文章提供了丰富的参考资料。
本文详细探讨了Linux内核中的关键概念,包括系统调用的分类和实现、内核数据结构如链表和映射、中断处理的类型与机制,以及中断下半部的处理方式如软中断、TaskLet和工作队列。此外,还介绍了内核同步与互斥的机制以及定时器和时间管理。最后,概述了Linux进程的生命周期、调度算法和内存虚拟地址空间的划分与管理。对于深入学习Linux内核的读者,这篇文章提供了丰富的参考资料。
LINUX内核学习
1. 系统调用
1.1. 什么是系统调用
当你运行的程序调用了open, fork, read, write等等,你就做了系统调用 。
系统调用就是程序如何进入内核执行任务。程序使用系统调用执行一系列的操作诸如:创建进程,网络和文件IO等等。
你可以在man page for syscalls(2)里面看到系统调用的列表。 用户程序做系统调用有不同的方法,CPU架构不同做系统调用的底层指令也不同。
作为应用开发者,你不需要经常思考系统调用如何正确执行。你只需要把头文件引入,然后像普通功能一样调用。

1.2 传统系统调用
有两个需要预先准备的知识:
- 我们可以通过生成软中断触发内核调用。
- 我们可以用汇编指令int生成软中断。
结合这两个概念让我们看Linux传统系统调用接口。
用户空间程序可以取到Linux内核软中断号,这样就可以进入内核和执行系统调用。

1.3 系统调用大致可分为六大类
- 进程控制(process control)
- 文件管理(file manipulation)
- 设备管理(device manipulation):操作系统控制的各种资源可看作设备。
- 信息维护(information maintenance):操作系统维护所有进程的信息,这些可通过系统调用来访问。
- 通信(communication) :进程间通信的常用模型有两个:消息传递模型和共享内存模型。
- 保护(protection):保护提供控制访问计算机的系统资源的机制
1.4 参考文档
2. 内核数据结构
2.1 传统的双向链表和内核中的双向链表的区别
- 有个单独的头结点(head)
- 每个节点(node)除了包含必要的数据之外,还有2个指针(pre,next)
- pre指针指向前一个节点(node),next指针指向后一个节点(node)
- 头结点(head)的pre指针指向链表的最后一个节点
- 最后一个节点的next指针指向头结点(head)

传统的链表有个最大的缺点就是不好共通化,因为每个node中的data1,data2等等都是不确定的(无论是个数还是类型)。linux中的链表巧妙的解决了这个问题,linux的链表不是将用户数据保存在链表节点中,而是将链表节点保存在用户数据中.linux的链表节点只有2个指针(pre和next),这样的话,链表的节点将独立于用户数据之外,便于实现链表的共同操作。

2.2 队列

2.3 映射
映射是实现(key,value)绑定的一种数据结构。也称为关联数组。可以视为由唯一key组成的集合。每个key对应这一个value。
常规的映射实现有hash表和二叉树,以及二叉树的变种。
2.1 参考文档
- 《Linux内核设计与实现》读书笔记(六)- 内核数据结构 (链表、队列、映射、红黑树)
- Linux内核中的算法和数据结构 (链表、双向链表、无锁链表、B+树、优先排序列表、红黑树)
- Linux Kernel - 第六讲 内核数据结构-讲解版_x264_哔哩哔哩_bilibili (链表、队列、映射、二叉树)
- linux内核中的链表 - wangLinuxer - 博客园 (cnblogs.com) (内核中的链表)
- linux内核之Kfifo环形队列 - super_xueyi - 博客园 (cnblogs.com) (Kfifo)
3. 中断处理
3.1 中断
中断请求(IRQ)是由可编程的中断控制器(PIC)发起的,其目的是为了中断 CPU 和执行中断服务程序(ISR)
Linux内核使用中断的方式来管理硬件设备,中断本质上是一种电信号,设备通过和中断控制器引脚相连的总线发出电信号来发出中断。中断控制器是一种控制芯片,多个设备的中断请求线同时连接到中断控制器上,如果多个设备同时发出中断信号,中断控制器根据优先级选择其中一个发送给处理器处理器,处理器收到中断请求后,就中断当前正在执行的任务,进行中断处理。内核通过中断号(中断号是系统为每个中断请求线interrupt request line分配的编号)来区分不同的设备产生的中断,从而执行对应的中断处理程序。
3.2 中断类型
3.2.1 硬件中断
当一个硬件设备想要告诉 CPU 某一需要处理的数据已经准备好后(例如:当键盘被按下或者一个数据包到了网络接口处),它将会发送一个中断请求(IRQ)来告诉 CPU 数据是可用的。接下来会调用在内核启动时设备驱动注册的对应的中断服务程序(ISR)。
3.2.2 软件中断
当你在播放一个视频时,音频和视频是同步播放是相当重要的,这样音乐的速度才不会变化。这是由软件中断实现的,由精确的计时器系统(称为 jiffies)重复发起的。这个计时器会使得你的音乐播放器同步。软件中断也可以被特殊的指令所调用,来读取或写入数据到硬件设备。
当系统需要实时性时(例如在工业应用中),软件中断会变得重要。你可以在 Linux 基金会的文章中找到更多相关信息:面向嵌入式开发者的实时 Linux 介绍。
3.2.3 异常
异常exception是你可能之前就知道的中断类型。当 CPU 执行一些将会导致除零或缺页错误的指令时,任何其他运行中的程序都会被中断。在这种情况下,你会被一个弹窗提醒,或在控制台输出中看到段错误segmentation fault(核心已转储core dumped)。但并不是所有异常都是由指令错误引起的。
异常可以进一步分为错误Fault、陷阱Trap和终止Abort。
- 错误:错误是系统可以纠正的异常。例如当一个进程尝试访问某个已经被换出到硬盘的页时。当请求的地址在进程的地址空间中,并且满足访问权限时,如果页不在内存(RAM)中,将会产生一个中断请求(IRQ),并开始启用缺页异常处理程序把所需的页加载到内存中。如果操作成功执行,程序将继续运行。
- 陷阱:陷阱主要用在调试中。如果你在某个程序中设置了一个断点,你就插入了一条可以触发陷阱执行的特殊指令。陷阱可以触发上下文切换来允许你的调试器读取和展示局部变量的值。之后程序可以继续运行。陷阱同样也是运行系统调用的方式(如杀死一个进程)
- 终止:终止是由系统表中的硬件错误或值不一致而导致的。终止不会报告造成异常的指令的所在位置。这是最严重的中断,终止将会调用系统的终止异常处理程序来结束造成异常的进程。
3.3 参考文档
- 13.linux中断处理程序 - for_learning - 博客园 (cnblogs.com)
- Linux内核学习笔记(九)中断和中断处理程序 | 胡刘郏的技术博客 (huliujia.com)
- (52条消息) Linux 中断之中断处理浅析_StephenZhou-优快云博客_linux中断
- Linux 内核处理中断全过程解析 | 《Linux就该这么学》 (linuxprobe.com)
4. 中断下半部的处理
4.1 软中断
软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。软中断一般是“可延迟函数”的总称,有时候也包括了tasklet(请读者在遇到的时候根据上下文推断是否包含tasklet)。它的出现就是因为要满足上面所提出的上半部和下半部的区别,使得对时间不敏感的任务延后执行,软中断执行中断处理程序留给它去完成的剩余任务,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:
a)产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断(上半部)。
b)可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保护其数据结构。
4.2 TaskLet
tasklet是通过软中断实现的,所以它本身也是软中断。
软中断用轮询的方式处理。假如正好是最后一种中断,则必须循环完所有的中断类型,才能最终执行对应的处理函数。显然当年开发人员为了保证轮询的效率,于是限制中断个数为32个。
为了提高中断处理数量,顺道改进处理效率,于是产生了tasklet机制。
Tasklet采用无差别的队列机制,有中断时才执行,免去了循环查表之苦。Tasklet作为一种新机制,显然可以承担更多的优点。正好这时候SMP越来越火了,因此又在tasklet中加入了SMP机制,保证同种中断只能在一个cpu上执行。在软中断时代,显然没有这种考虑。因此同一种软中断可以在两个cpu上同时执行,很可能造成冲突。
总结下tasklet的优点:
(1)无类型数量限制;
(2)效率高,无需循环查表;
(3)支持SMP机制;
它的特性如下:
1)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
2)多个不同类型的tasklet可以并行在多个CPU上。
3)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
4.3 工作队列 (work queue)
为了提高中断的执行速度,我们将不是特别耗时的任务交给下半部tasklet来做(tasklet在在中断的上下文中工作,无法休眠),但是,当有非常复杂的操作需要执行的时候,如果依旧采用下半部tasklet来做,虽然系统依旧可以响应中断,但是,应用应用程序是不能执行的。因为整个系统都在执行软中断或是硬中断。
将耗时的操作放在某一个线程(内核线程)去做,可以解决系统的卡顿问题,因为线程可以休眠。这就是工作队列。
工作队列的优点是利用进程上下文来执行中断下半部操作,因此工作队列允许重新调度和睡眠,是异步执行的进程上下文,它还能解决软中断和tasklet执行时间过长导致系统实时性下降等问题。
4.4 参考文档
- Linux中断机制 - Edver - 博客园 (cnblogs.com)
- Linux中断管理 (3)workqueue工作队列 - ArnoldLu - 博客园 (cnblogs.com)
- (52条消息) linux中,中断的处理方法 工作队列_weixin_A13253323604-优快云博客
5. 内核同步与互斥
5.1 各种同步机制
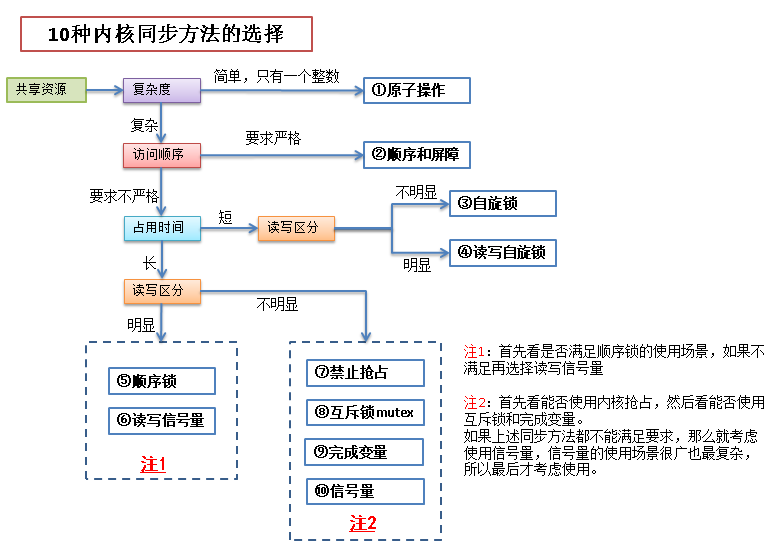
5.2参考文档
- (52条消息) 从零开始学Linux驱动–(9)内核中的互斥与同步_wit_732的博客-优快云博客
- Linux内核中各种同步机制 - LW! - 博客园 (cnblogs.com)
- Linux内核同步机制-互斥锁 - 简书 (jianshu.com)
6. 定时器和时间管理
6.1 内核中的时间观念
内核在硬件的帮助下计算和管理时间。
硬件为内核提供一个系统定时器用以计算流逝的时间。
系统定时器以某种频率自行触发。产生时钟中断。进入内核时钟中断处理程序中进行处理。该频率能够通过编程预定,称为节拍率(tick rate)。
连续两次时钟中断的间隔时间称为节拍(tick)。它等于节拍率分之中的一个秒。
墙上时间和系统执行时间依据时钟间隔来计算。
6.2 节拍率HZ
节拍率(HZ)是时钟中断的频率,表示的一秒内时钟中断的次数。
比方 HZ=100 表示一秒内触发100次时钟中断程序。
提高节拍率中断产生更加频繁带来的优点:
提高时间驱动事件的解析度;
提高时间驱动事件的精确度;
内核定时器以更高的频度和精确度;
依赖顶上执行的系统调用poll()和select()能更高的精度执行;
系统时间測量更精细。
提高进程抢占的精确度;
提高节拍率带来的副作用:
中断频率增高系统负担添加;
中断处理程序占用处理器时间增多;
频繁打断处理器快速缓存;
6.3 硬时钟和定时器
实时时钟(RTC):用来持久存放系统时间的设备。即便系统关闭后,靠主板上的微型电池提供电力保持系统的计时。系统启动内核通过读取RTC来初始化墙上时间,改时间存放在xtime变量中。
系统定时器:内核定时机制。注冊中断处理程序,周期性触发中断。响应中断处理程序。
6.3 参考文档
- linux内核分析笔记----定时器和时间管理 - ☆&寒 烟☆ - 博客园 (cnblogs.com)
- Linux内核——定时器和时间管理 (bbsmax.com)
- Linux Kernel 定时器和时间管理(浅析)_zmrlinux-优快云博客
- Linux内核——定时器和时间管理 - lcchuguo - 博客园 (cnblogs.com)
7. Linux的进程
7.1 进程的概念
从用户角度:进程就是一个正在运行中的程序。
操作系统角度:操作系统运行一个程序,需要描述这个程序的运行过程,这个描述通过一个结构体task_struct{}来描述,统称为PCB,因此对操作系统来说进程就是PCB(process control block)程序控制块
进程的描述信息有:标识符PID,进程状态,优先级,程序计数器,上下文数据,内存指针,IO状态信息,记账信息。都需要操作系统进行调度。
7.2 进程状态
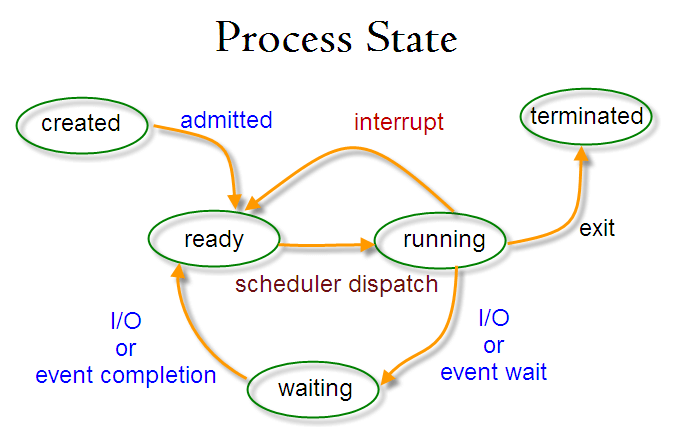
7.3 查看运行中的进程
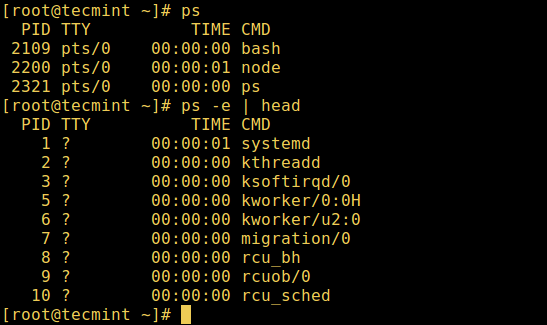
1. ps 命令
它显示被选中的系统中活跃进程的信息,如下图所示:
# ps
# ps -e | head
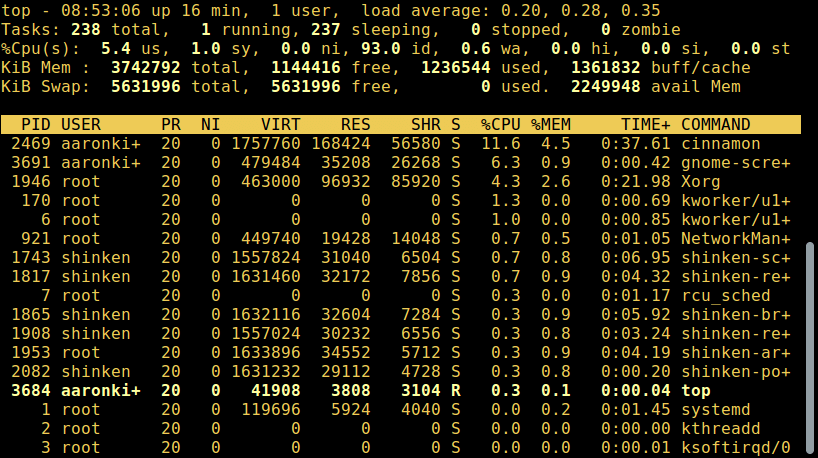
2. top - 系统监控工具
top 是一个强大的工具,它能给你提供 运行系统的动态实时视图,如下面截图所示:
# top
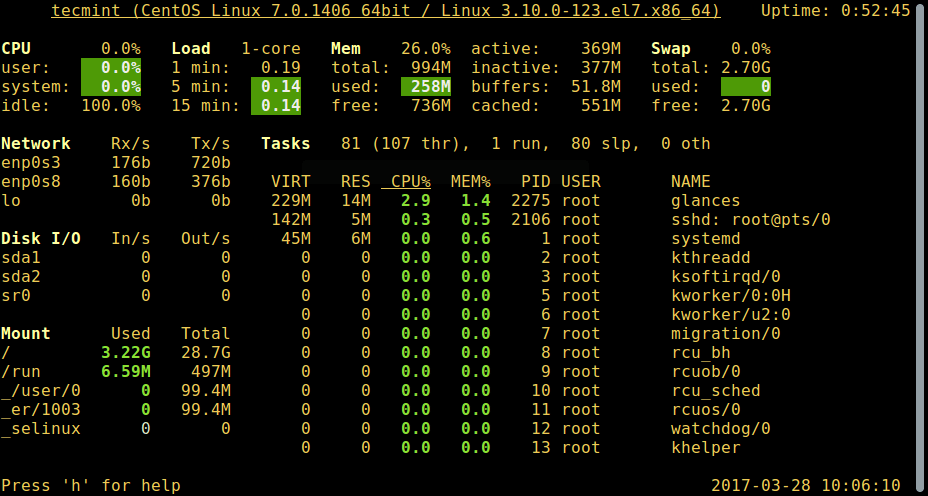
3. glances - 系统监控工具
glances 是一个相对比较新的系统监控工具,它有一些比较高级的功能:
# glances
7.4 参考文档
- Linux进程概念_skrskr66的博客-优快云博客_linux进程
- 关于Linux 进程你要知道的事 | 《Linux就该这么学》 (linuxprobe.com)
- Linux从程序到进程 - Vamei - 博客园 (cnblogs.com)
8. 进程的调度
8.1 进程调度含义
进程调度决定了将哪个进程进行执行,以及执行的时间。操作系统进行合理的进程调度,使得资源得到最大化的利用。
进程调度器的任务就是合理分配CPU时间给运行的进程,创造一种所有进程并行运行的错觉。这就对调度器提出了要求:
1、调度器分配的CPU时间不能太长,否则会导致其他的程序响应延迟,难以保证公平性。
2、调度器分配的时间也不能太短,每次调度会导致上下文切换,这种切换开销很大。
而调度器的任务就是:1、分配时间给进程 2、上下文切换
所以具体而言,调度器的任务就明确了:用一句话表述就是在恰当的实际,按照合理的调度算法,选择进程,让进程运行到它应该运行的时间,切换两个进程的上下文。
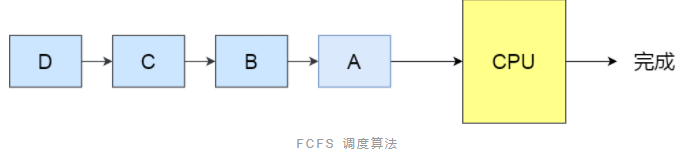
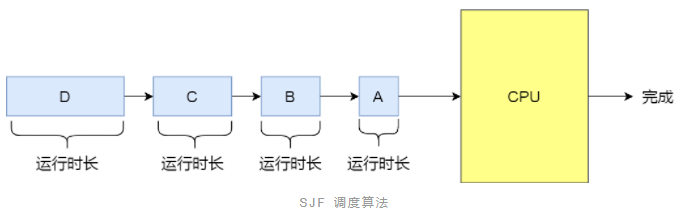
8.2 调度算法
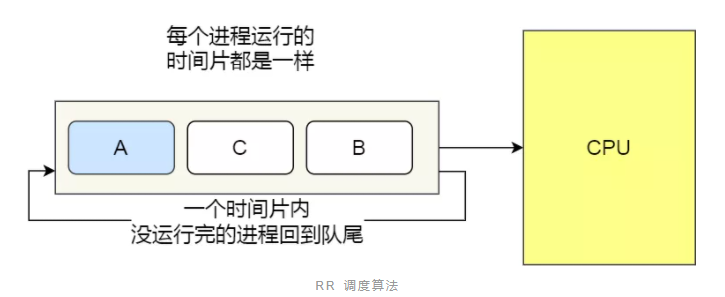
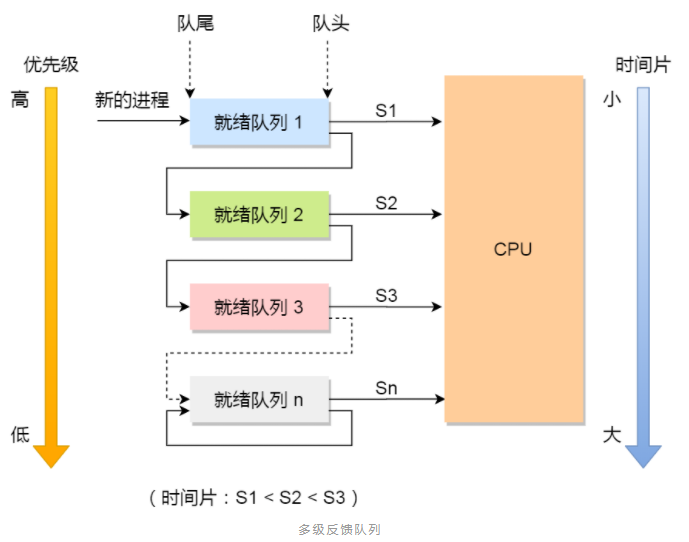
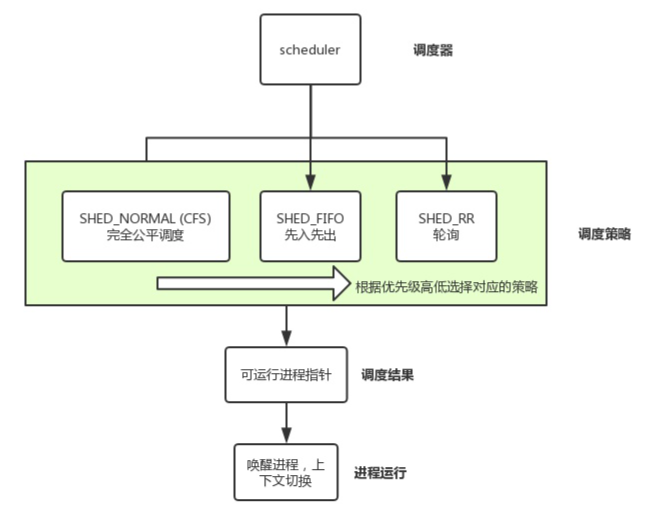

8.3 参考文档
9. 内存虚拟地址空间
9.1 Linux内核地址空间划分
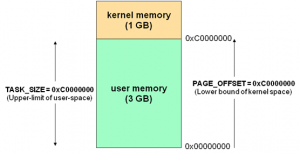
通常32位Linux内核地址空间划分03G为用户空间,34G为内核空间。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
9.2 Linux内核高端内存的理解
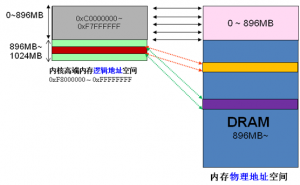
前面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。
9.3 参考文档
- (52条消息) Linux内核地址映射模型_linux大本营的博客-优快云博客_linux地址映射
- Linux kernel 内存 - 页表映射(SHIFT,SIZE,MASK)和转换(32位,64位) - AhaoMu - 博客园 (cnblogs.com)
- 90分钟了解Linux内存架构,numa的优势,slab的实现,vmalloc的原理_哔哩哔哩_bilibili
- 奔跑吧Linux内核第一季内存管理篇_哔哩哔哩_bilibili
作者:vrix.yan
日期:20211019

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









