




 本文详细解析了ConcurrentHashMap在JDK1.7和JDK1.8中的实现原理,包括锁分段策略、数据结构变化、线程安全机制、源码分析等内容,对比了不同版本之间的差异。
本文详细解析了ConcurrentHashMap在JDK1.7和JDK1.8中的实现原理,包括锁分段策略、数据结构变化、线程安全机制、源码分析等内容,对比了不同版本之间的差异。
文章目录
一、顶部注释分析
1.1 数据结构
1.1.1 JDK1.7实现
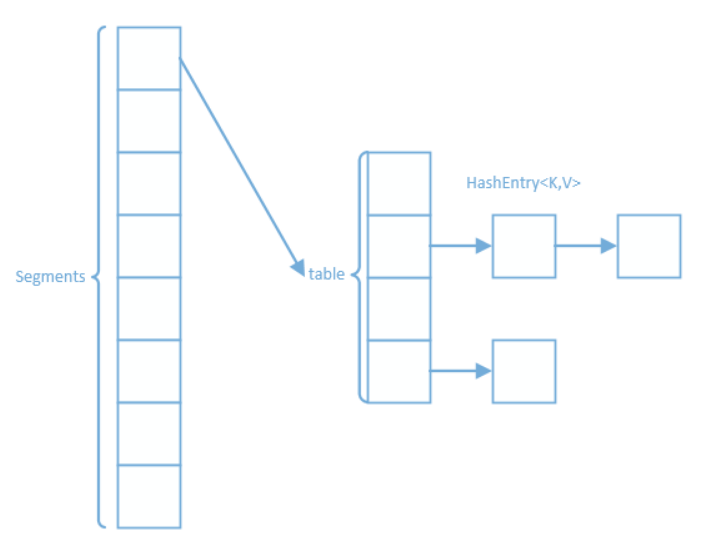
- 在 JDK1.7中,ConcurrentHashMap 通过**“锁分段”**来实现线程安全
- 通过将哈希表分成许多片段 (segments) ,每一个片段 (table) 都类似于 HashMap,有一个HashEntry 数组,数组的每项又是 HashEntry 组成的链表
- Segment 继承了ReentrantLock,所以 Segment 本质上是一个可重入的互斥锁
- 在访问某个键值对时,需要先获取该键值对所在的 segment 上的锁,获取锁后,其他线程就不能访问此segment了,但可以访问其他的segment,从而避免了把整个哈希表都锁住
1.1.2 JDK1.8实现
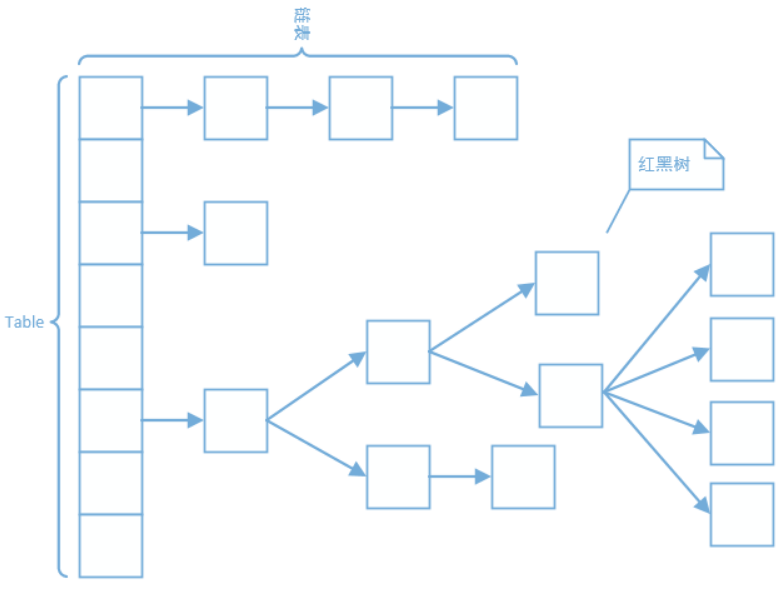
- JDK1.8中放弃了锁分段的方式,结构和 HashMap 相同,也是数组+链表+红黑树的方式
- 但是通过 CAS 和部分加锁的方式来实现线程安全
1.2 从注释中得到的结论
A hash table supporting full concurrency of retrievals and high expected concurrency for updates:ConcurrentHashMap 是一个支持高并发检索和更新的哈希表- ConcurrentHashMap 是线程安全的,但不是靠阻塞和封锁整个哈希表来实现的
- get 操作不是阻塞的,因此可以和一些更新操作并行,如 put 和 remove
- 一些和统计相关的方法,如
size、isEmpty、containsValue最好在单线程环境下使用,在多线程环境下只能反应一个暂时的状态,可用于估计或监视,但可能无法返回准确值,除非此时没有发生并发的修改 - 当散列碰撞过多时,ConcurrentHashMap 会动态增长。但是扩容非常消耗资源,因此最好提前估计好容量
- ConcurrentHashMap 不允许 key 或 value 为 null
二、源码分析
2.1 定义
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable
- ConcurrentHashMap<K,V>:HashMap 是以 key-value 形式存储数据的
- extends AbstractMap<K,V>:继承自 AbstractMap,大大减少了实现 Map 接口时需要的工作量
- implements ConcurrentMap<K,V>:实现了 ConcurrentMap 接口,一个提供线程安全性和原子性保证的 Map
- implements Serializable:可以序列化
2.2 字段
// 哈希表数组,用volatile修饰,大小总是为2的整数次幂
transient volatile Node<K,V>[] table;
// 基础计数器,通过CAS来更新
private transient volatile long baseCount;
/**
* 用于控制初始化和扩容
* 当为负数时,表示正在进行初始化或扩容操作:
* -1 表示正在初始化
* -N 表示有N-1个线程正在进行扩容操作
*
* 默认值为0
* 当初始化之后,保存下一次的扩容值
*/
private transient volatile int sizeCtl;
// 用于计算size
private transient volatile CounterCell[] counterCells
2.3 Node静态内部类
- 与 HashMap 中的 Node 相似,但有如下区别:
- 对 value 和 next 属性设置了 volatile 同步锁;
- 不允许调用 setValue 方法直接改变 Node 的 value,否则会抛出异常
- 增加了 find 方法用于辅助 get 方法
static class Node<K,V> implements Map.Entry<K,V>
{
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next)
{
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final V setValue(V value)
{
throw new UnsupportedOperationException();
}
Node<K,V> find(int h, Object k)
{
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
2.4 构造方法
public ConcurrentHashMap():构建一个空ConcurrentHashMap,默认容量为16public ConcurrentHashMap(int initialCapacity):构建一个空ConcurrentHashMap并根据参数设置下次扩容值public ConcurrentHashMap(Map<? extends K, ? extends V> m):根据给定的 Map 进行构建public ConcurrentHashMap(int initialCapacity, float loadFactor):根据给定的参数设置下次扩容值和加载因子,默认并行度为1public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel):根据给定的参数设置下次扩容值和加载因子,且容量至少为估计的线程数concurrencyLevel
2.5 put 操作
2.5.1 put 方法大致步骤
- 计算 key 的哈希值;
- 如果 table 数组为空,则先进行初始化 (2.5.2节);
- 根据 hash 值计算出 key 在表中所处的位置,即
(n - 1) & hash:
- 如果该位置没有值 ,则直接放入,且不需要加锁;
- 如果插入位置是连接点,说明正在进行扩容,则帮助当前线程扩容;
- 否则加锁,然后根据链表或树结构遍历查找 key 值,找到则进行更新,否则新增节点插入;
- 与 HashMap 类似,若链表长度超过阈值,则转为红黑树;
- 如果操作3中执行的是替换操作,返回被替换的value;
- 否则说明节点是被新插入的,因此将元素数量加1
整个过程中只有3中的第三步需要加锁,从而提高并行性能
2.5.2 初始化 table 数组
- 调用 ConcurrentHashMap 的构造方法仅仅只是设置了一些参数,而整个 table 的初始化是在向其中插入元素的时候发生的,例如 put 方法
- 初始化方法主要应用了关键属性 sizeCtl,如果
sizeCtl < 0,表示其他线程正在进行初始化,就放弃操作,从而保证只让一个线程对 table 进行初始化 - 如果获得了初始化权限,就先用 CAS 方法将 sizeCtl 置为-1,防止后续其他线程进入
- 初始化完成后,将 sizeCtl 的值设为
n - (n >>> 2)),即 0.75 × n
private final Node<K,V>[] initTable()
{
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0)
{
// 其他线程正在进行初始化
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1))
{
try
{
if ((tab = table) == null || tab.length == 0)
{
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2); // 0.75 × n
}
}
finally
{
sizeCtl = sc;
}
break;
}
}
return tab;
}
2.6 get 操作
- get 方法没有进行加锁,其大致步骤为:
- 计算 key 的哈希值;
- 根据哈希值查找节点位置;
- 如果节点直接在桶的头节点上,则直接返回;
- 否则说明有碰撞,根据树形结构或链表结构使用不同的方法继续查找;
- 如果找到则返回对应值,否则返回 null
// 从源码中可以看出,get方法没有加锁
public V get(Object key)
{
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null)
{
if ((eh = e.hash) == h)
{
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null)
{
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









