







//
深度神经网络是深度学习的一种框架,它是一种具备至少一个隐层的神经网络。与浅层神经网络类似,深度神经网络也能够为复杂非线性系统提供建模,但多出的层次为模型提供了更高的抽象层次,因而提高了模型的能力。深度神经网络是一种判别模型,可以使用反向传播算法进行训练。随着深度神经网络使用的越来越多,相应的压缩和加速技术也孕育而生。LiveVideoStackCon 2023上海站邀请到了胡浩基教授为我们分享他们实验室的一些实践。
文/胡浩基
编辑/LiveVideoStack
大家好,我是来自浙江大学信息与电子工程学院的胡浩基。今天我分享的主题是《深度神经网络压缩与加速技术》。
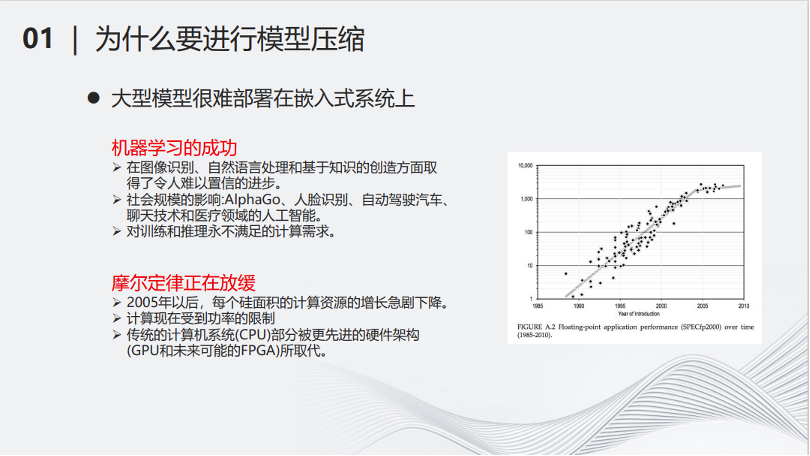
首先一个问题是,为什么要做深度神经网络压缩?有两个原因:第一个原因是大型的深度神经网络很难部署在小型化的设备上。另一个原因是当深度模型越来越大,需要消耗的计算和存储资源越来越多,但是物理的计算资源跟不上需求增长的速度。
从右边的图可以看出,从2005年开始,硬件的计算资源增长趋于放缓,而随着深度学习领域的蓬勃发展,对算力的需求却是指数级增长,这就导致了矛盾。因此,对深度模型进行简化,降低其计算量,成了当务之急。近年来,以ChatGPT为代表的大模型诞生,将这个问题变得更加直接和迫切。如果想要应用大模型,必须有能够负担得起的相对低廉计算和存储资源,在寻找计算和存储资源的同时,降低大模型的计算量,将是对解决算力问题的有益补充。
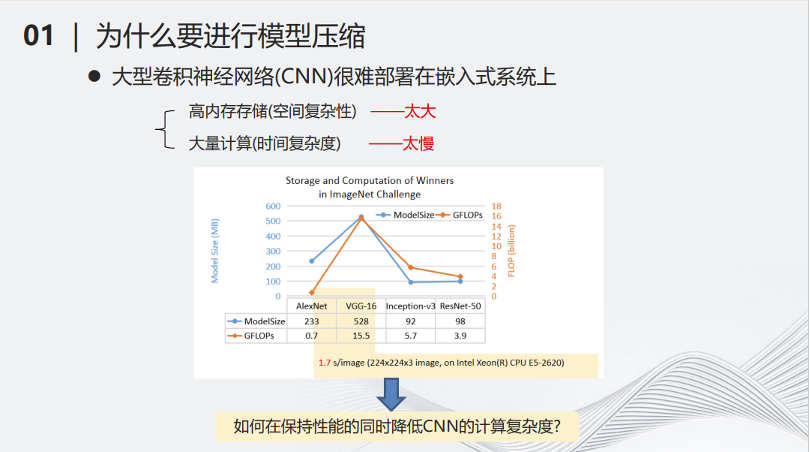
例如2017年流行的VGG-16网络,在当时比较主流的CPU上处理一张图片,可能需要1.7秒的时间,这样的时间显然不太适合用部署在小型化的设备当中。

深度神经网络的压缩用数学表述就是使用一个简单的函数来模拟复杂的函数。虽然这是一个已经研究了几百年的函数逼近问题,但是在当今的环境下,如何将几十亿甚至上千亿自由参数的模型缩小,是一个全新的挑战。这里有三个基本思想 -- 更少参数、更少计算和更少比特。在将参数变少的同时,用较为简单的计算来代替复杂的计算。用低精度量化的比特数来模拟高精度的数据,都可以让函数的计算复杂性大大降低。
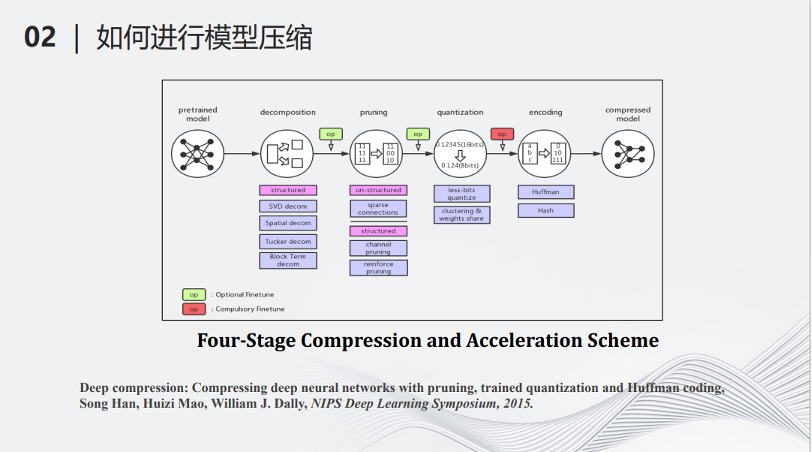
深度模型压缩和加速领域开创人MIT的副教授韩松在2015年的一篇文章,将深度学习的模型压缩分成了如下的5个步骤。最左边输入了一个深度学习的模型,首先要经过分解(decomposition),即用少量的计算代替以前复杂的计算,例如可以把很大的矩阵拆成多个小矩阵,将大矩阵的乘法变成小矩阵的乘法和加法。第二个操作叫做剪枝(pruning),它是一个减少参数的流程,即将一些对整个计算不那么重要的参数找出来并把它们从原来的神经网络中去掉。第三个操作叫做量化(Quantization),即将多比特的数据变成少比特的数据,用少比特的加法和乘法模拟原来的多比特的加法乘法,从而减少计算量。做完以上三步操作之后,接下来需要编码(encoding),即用统一的标准将网络的参数和结构进行一定程度的编码,进一步降低网络的储存量。经过以上四步的操作,最后可以得到一个被压缩的模型。
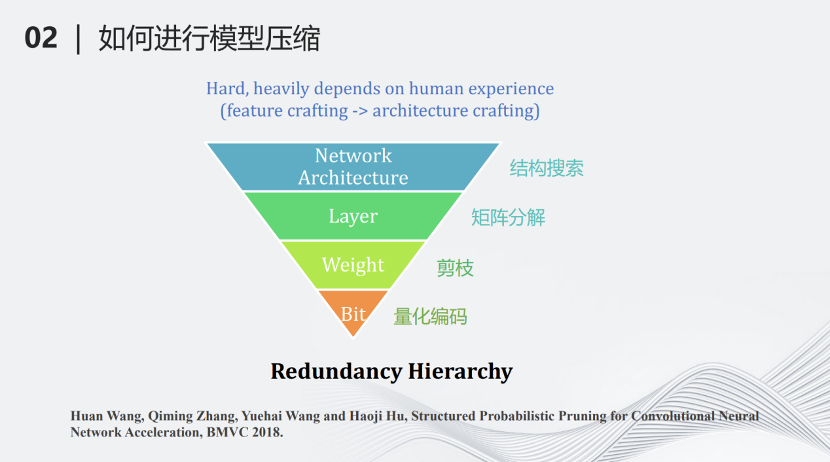
我们团队提出了另外一种基于层次的模型压缩分类。最上面一个层级叫做网络结构搜索(network architecture design),即搜索一个计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









