







 本文综述了ECCV 2020会议上关于半监督学习、无监督学习、迁移学习、表征学习及小样本学习的关键研究。文中介绍了几种学习方法,如Big Transfer(BiT)模型,它通过预训练和微调提高视觉表示的通用性和迁移性。此外,探讨了如何利用图像标题进行无监督预训练,提出图像条件化的掩蔽语言建模(ICMLM)来强化图像和文字之间的交互。其他研究包括视频表示学习、图像聚类、小样本图像分类以及通过神经辐射场(NeRF)进行三维场景渲染。
本文综述了ECCV 2020会议上关于半监督学习、无监督学习、迁移学习、表征学习及小样本学习的关键研究。文中介绍了几种学习方法,如Big Transfer(BiT)模型,它通过预训练和微调提高视觉表示的通用性和迁移性。此外,探讨了如何利用图像标题进行无监督预训练,提出图像条件化的掩蔽语言建模(ICMLM)来强化图像和文字之间的交互。其他研究包括视频表示学习、图像聚类、小样本图像分类以及通过神经辐射场(NeRF)进行三维场景渲染。

正文字数:8279 阅读时长:12分钟
2020年欧洲计算机视觉会议(ECCV)于8月23日至28日在网上举行,由1360篇论文组成,包括104场orals,160场spotlights以及1096篇posters,共进行有45场workshops和16场tutorials。与近年来的ML和CV会议一样,有时大量的论文可能不胜枚举。
作者 / Yassine
原文链接 / https://yassouali.github.io/ml-blog/eccv2020/
 往期阅读:ECCV 2020 亮点摘要(上)
往期阅读:ECCV 2020 亮点摘要(上)
半监督学习,无监督学习,迁移学习,表征学习以及小样本学习
Big Transfer (BiT): General Visual Representation Learning (paper)
(https://arxiv.org/abs/1912.11370)
在本文中,作者重新审视了迁移学习的简单范式:首先在一个大规模标记数据集(例如JFT-300M和ImageNet-21k数据集)上进行预训练,然后对目标任务上的每个训练权重进行精调任务,减少目标任务所需的数据量和优化时间。作者们拟议的迁移学习框架是BiT(大转移),由许多组件组成,包含了大量构建有效模型的必需组件,使其能够借助于大规模数据集学习到通用的、可迁移的特征表达。
在(上游)预训练方面,BiT包括以下内容:
对于非常大的数据集,由于Batch Normalization(BN)在测试结果期间使用训练数据中的统计信息会导致训练/测试差异,在这种情况下,训练损失可以正确优化和回传,但是验证损失非常不稳定。除了BN对批次大小的敏感性外。为了解决这个问题,BiT既使用了Group Norm,又使用了Weight Norm,而不是Batch Norm。
诸如ResNet 50之类的小型模型无法从大规模数据集中受益,因此模型的大小也需要相应地扩大规模,和数据集匹配。
对于(下游)目标任务,BiT建议以下内容:
使用标准SGD优化器,无需层冻结,dropout,L2正规化或任何适应梯度。别忘了把最后的预测层的权重初始化为0。
不用将所有输入缩放为固定大小,例如224。在训练过程中,输入图像会随机调整大小并裁剪为具有随机选择大小的正方形,并随机水平翻转。在测试阶段,图像会被缩放为固定大小,
尽管对于数据量充足的大规模数据集预训练来说,mixup 并没有多大用处,但BiT发现misup正则化对于用于下游任务的中型数据集训练非常有用。
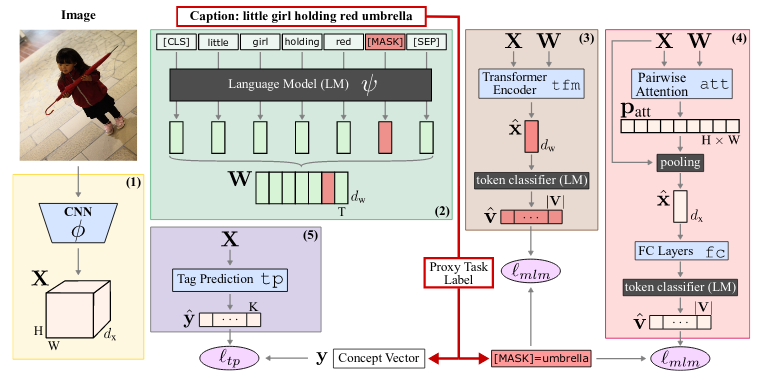
Learning Visual Representations with Caption Annotations
(https://arxiv.org/abs/2008.01392)
在大规模标注的数据集上训练深度模型不仅可以使手头的任务表现良好,还可以使模型学习对于下游任务的有用特征形式。但是,我们是否可以在不使用如此昂贵且细粒度的标注数据的情况下获得类似的特征表达能力呢?本文研究了使用噪声标注(在这种情况下为图像标题)的弱监督预训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









