




 本文详细介绍了聚类任务,包括无监督学习中的聚类应用,性能度量的外部指标与内部指标,以及原型聚类、密度聚类和层次聚类三种常见聚类算法的原理与特点。
本文详细介绍了聚类任务,包括无监督学习中的聚类应用,性能度量的外部指标与内部指标,以及原型聚类、密度聚类和层次聚类三种常见聚类算法的原理与特点。
要点
1. 聚类任务描述
2. 性能度量
3. 聚类算法
原型聚类
• K均值算法
• 学习向量算法
密度聚类
层次聚类
一、聚类任务
• 无监督学习unsupervised learning
标记未知;揭示数据的内在性质和规律
• 应用最广的无监督学习:聚类

二、性能度量

外部指标-计数
左边图是外部参考真实划分;右边是聚类算法推测结果。把数据集结果两两配对,根据它们在两个聚类的划分结果中进行点对的计数和比较。m个点两两配对,就有总共点对数:m(m-1)/2对;点对分为四类:
第一类:在两个划分结果中都在一个类别的点对数量 a
第二类:点对在外部模型中分为同一类,在聚类模型中分在不同类 b
第三类:点对在聚类模型中分为同一类,在外部模型中分为不同类 c
第四类:两种聚类中都不在同一类的点对数量 d
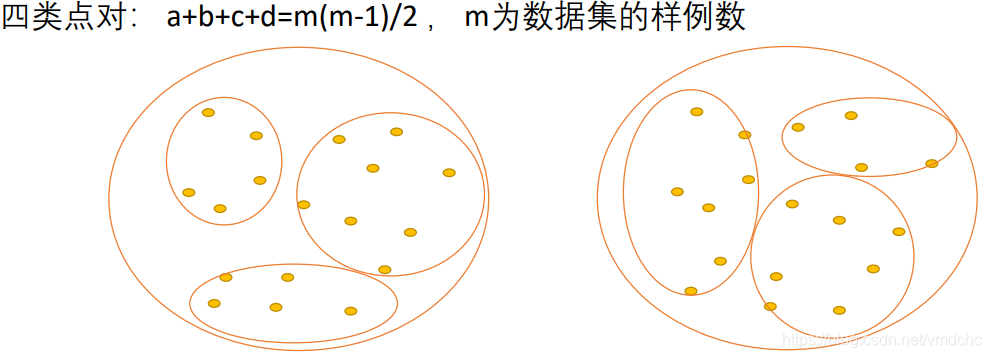
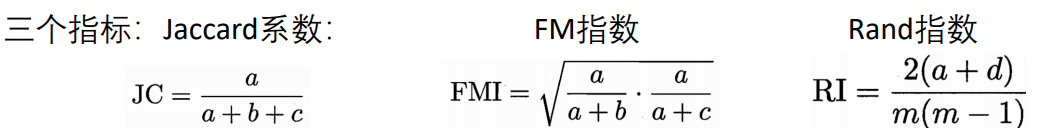
这些指标,都是越大越好。
内部指标-距离法
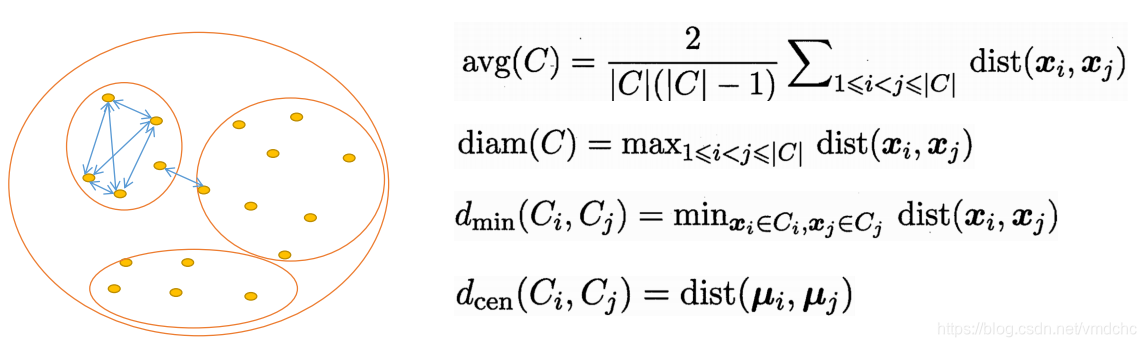
它们是:每簇内部的平均距离;每簇内部两两样例最大距离;簇与簇间最近的样本间的距离;簇与簇间中心点间的距离。
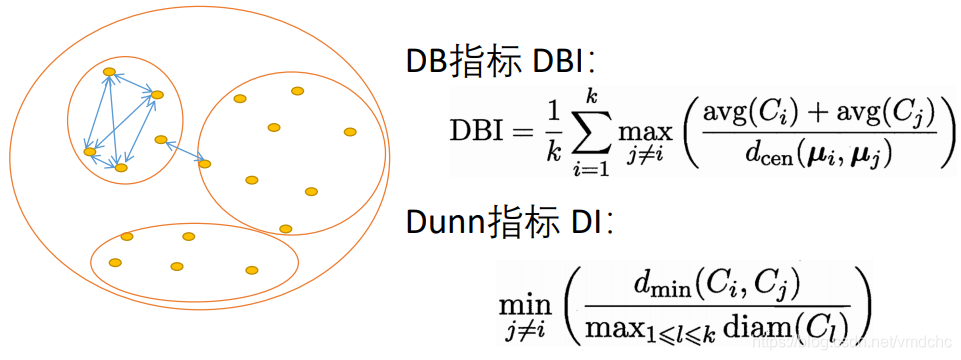
前者计算任意两个数的簇内平均距离之和两个簇中心距离的比值,然后找寻最大值,该值越小聚类效果越好。
后者先计算每个簇与其它簇的样本间距离最小值,再除以簇内样本间距离的最大值,这个值越大越好。


这是混合属性


三、聚类算法

原型聚类
原型聚类prototype-based clustering
所谓原型是有确定性的距离度量和模型方法,其特点是:
• 此类算法假设聚类结构能通过一组原型刻画;
• 算法先对原型进行初始化, 然后对原型进行迭代更新求解。


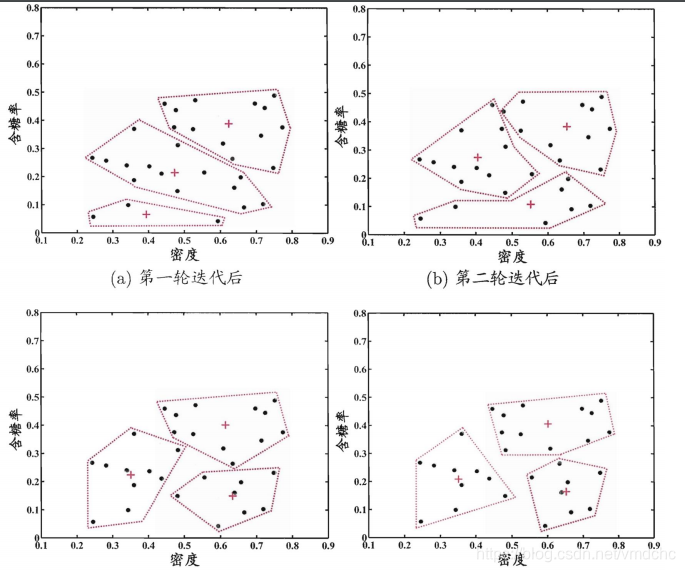


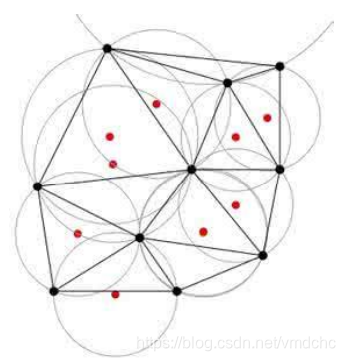
在原型向量量化学得一组原型向量之后,就可以实现对样本空间外的簇划分,每个原型向量定义了与之相关的一个区域,该区域中每个样本与自身类别的原型向量的距离不大于与其它原型向量的距离。该划分成为voronoi划分。
密度聚类
基于密度的聚类(density-based clustering)
特点:
• 假设聚类结构通过样本分布的紧密程度确定, 通常情形下,算法从样本密度的角度来考察样本之间的可连接性, 并基于可连接样本不 断扩展聚类簇以获得最终的聚类结果;

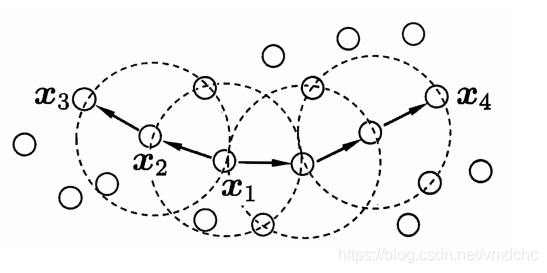
x2由x1密度直达,x3由x2密度可达,x4与x1密度相连

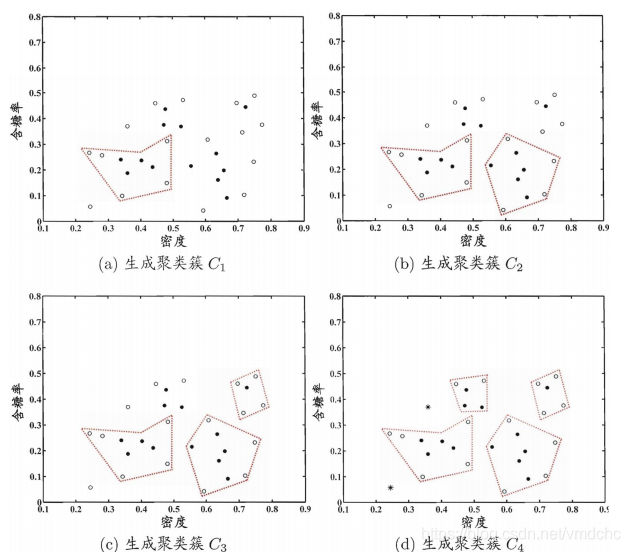
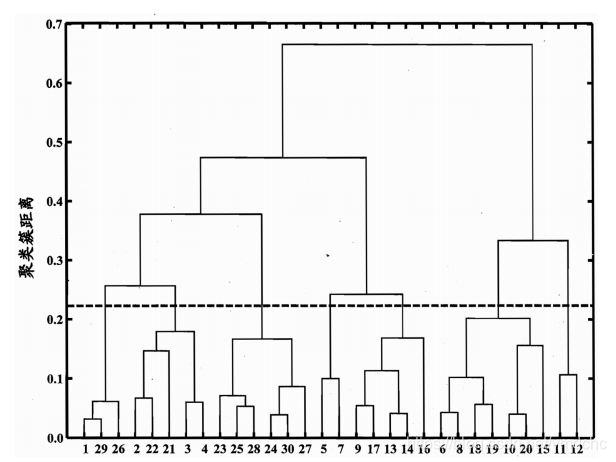
层次聚类
• 层次聚类(hierarchical clustering)试图在不同层次对数据集进行划 分, 从而形成树形的聚类结构。
AGNES方法
•自底向上聚合策略的层次聚类算法;
• 先将数据集中的每个样本看作一个初始聚类簇;
• 然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并;
• 该过程不断重复, 直至达到预设的聚类簇个数。

当聚类距离为dmin时, AGNES为单链算法,当聚类距离为dmax时候,为全链接算法,当聚类距离为davg时候,为均链接算法。下面看一个全链接算法的例子。横轴为样本编号,纵轴是聚类簇距离。

















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









