







回溯: 字符串的排列
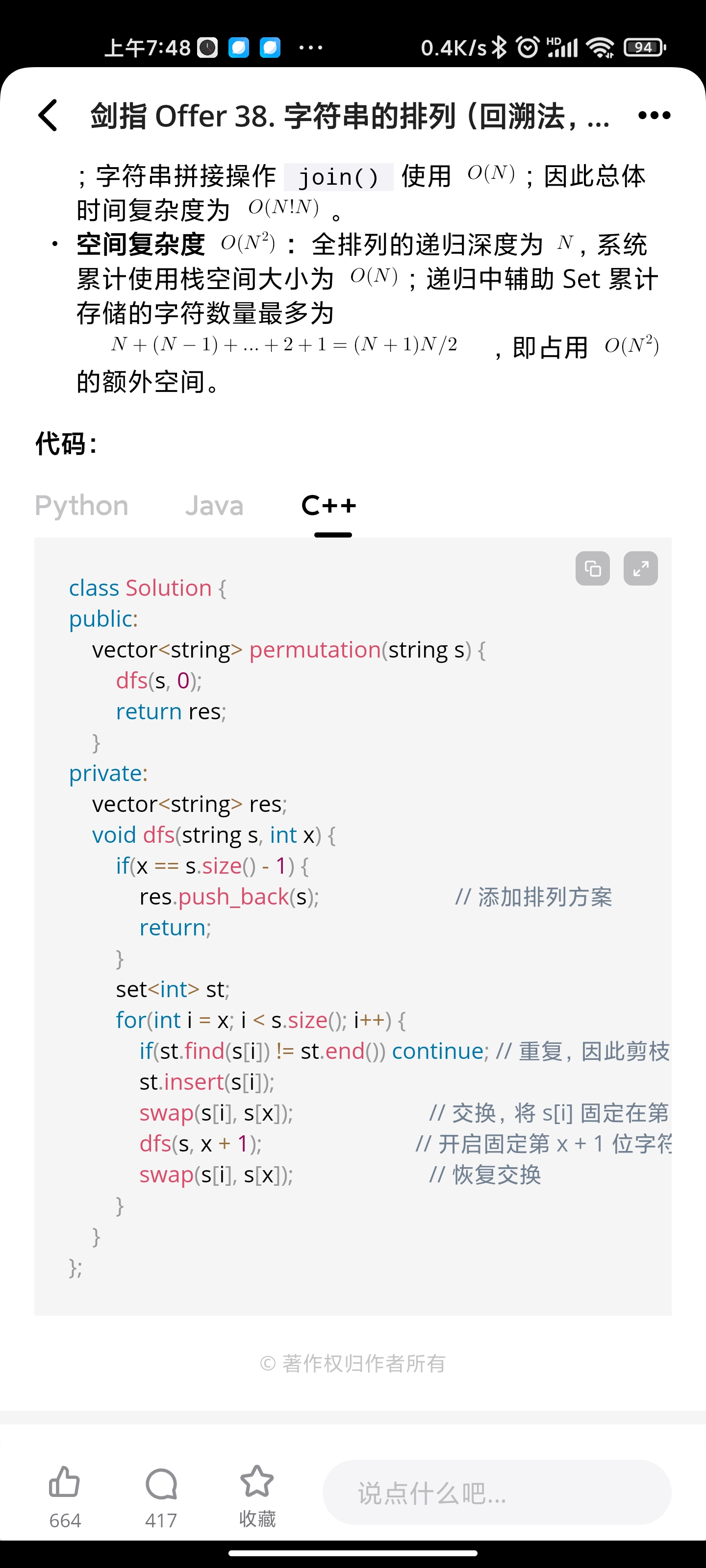

回溯:78. 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
nums 中的所有元素 互不相同

Solution1 回溯
https://leetcode.com/problems/subsets/comments/1011321
https://leetcode.com/problems/subsets/solution/c-zong-jie-liao-hui-su-wen-ti-lei-xing-dai-ni-gao-/
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
if (startIndex >= nums.size()) { // 终止条件可以不加
return;
}
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsets(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
回溯: 39. 组合总和
Solution1 暴力
Solution2 回溯
class Solution {
public:
void dfs(vector<int>& candidates, int target, vector<vector<int>>& ans, vector<int>& combine, int idx) {
if (idx == candidates.size()) {
return;
}
if (target == 0) {
ans.emplace_back(combine);
return;
}
// 直接跳过
dfs(candidates, target, ans, combine, idx + 1);
// 选择当前数
if (target - candidates[idx] >= 0) {
combine.emplace_back(candidates[idx]);
dfs(candidates, target - candidates[idx], ans, combine, idx);
combine.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<vector<int>> ans;
vector<int> combine;
dfs(candidates, target, ans, combine, 0);
return ans;
}
};
回溯: 40. 组合总和 II
Solution1 回溯
方法一:回溯
思路与算法
由于我们需要求出所有和为 \textit{target}target 的组合,并且每个数只能使用一次,因此我们可以使用递归 + 回溯的方法来解决这个问题:
我们用 \textit{dfs}(\textit{pos}, \textit{rest})dfs(pos,rest) 表示递归的函数,其中 \textit{pos}pos 表示我们当前递归到了数组 \textit{candidates}candidates 中的第 \textit{pos}pos 个数,而 \textit{rest}rest 表示我们还需要选择和为 \textit{rest}rest 的数放入列表作为一个组合;
对于当前的第 \textit{pos}pos 个数,我们有两种方法:选或者不选。如果我们选了这个数,那么我们调用 \textit{dfs}(\textit{pos} + 1, \textit{rest} - \textit{candidates}[\textit{pos}])dfs(pos+1,rest−candidates[pos]) 进行递归,注意这里必须满足 \textit{rest} \geq \textit{candidates}[\textit{pos}]rest≥candidates[pos]。如果我们不选这个数,那么我们调用 \textit{dfs}(\textit{pos} + 1, \textit{rest})dfs(pos+1,rest) 进行递归;
在某次递归开始前,如果 \textit{rest}rest 的值为 00,说明我们找到了一个和为 \textit{target}target 的组合,将其放入答案中。每次调用递归函数前,如果我们选了那个数,就需要将其放入列表的末尾,该列表中存储了我们选的所有数。在回溯时,如果我们选了那个数,就要将其从列表的末尾删除。
上述算法就是一个标准的递归 + 回溯算法,但是它并不适用于本题。这是因为题目描述中规定了解集不能包含重复的组合,而上述的算法中并没有去除重复的组合。
例如当 \textit{candidates} = [2, 2]candidates=[2,2],\textit{target} = 2target=2 时,上述算法会将列表 [2][2] 放入答案两次。
因此,我们需要改进上述算法,在求出组合的过程中就进行去重的操作。我们可以考虑将相同的数放在一起进行处理,也就是说,如果数 \textit{x}x 出现了 yy 次,那么在递归时一次性地处理它们,即分别调用选择 0, 1, \cdots, y0,1,⋯,y 次 xx 的递归函数。这样我们就不会得到重复的组合。具体地:
我们使用一个哈希映射(HashMap)统计数组 \textit{candidates}candidates 中每个数出现的次数。在统计完成之后,我们将结果放入一个列表 \textit{freq}freq 中,方便后续的递归使用。
列表 \textit{freq}freq 的长度即为数组 \textit{candidates}candidates 中不同数的个数。其中的每一项对应着哈希映射中的一个键值对,即某个数以及它出现的次数。
在递归时,对于当前的第 \textit{pos}pos 个数,它的值为 \textit{freq}[\textit{pos}][0]freq[pos][0],出现的次数为 \textit{freq}[\textit{pos}][1]freq[pos][1],那么我们可以调用
\textit{dfs}(\textit{pos} + 1, \textit{rest} - i \times \textit{freq}[\textit{pos}][0])
dfs(pos+1,rest−i×freq[pos][0])
即我们选择了这个数 ii 次。这里 ii 不能大于这个数出现的次数,并且 i \times \textit{freq}[\textit{pos}][0]i×freq[pos][0] 也不能大于 \textit{rest}rest。同时,我们需要将 ii 个 \textit{freq}[\textit{pos}][0]freq[pos][0] 放入列表中。
这样一来,我们就可以不重复地枚举所有的组合了。
我们还可以进行什么优化(剪枝)呢?一种比较常用的优化方法是,我们将 \textit{freq}freq 根据数从小到大排序,这样我们在递归时会先选择小的数,再选择大的数。这样做的好处是,当我们递归到 \textit{dfs}(\textit{pos}, \textit{rest})dfs(pos,rest) 时,如果 \textit{freq}[\textit{pos}][0]freq[pos][0] 已经大于 \textit{rest}rest,那么后面还没有递归到的数也都大于 \textit{rest}rest,这就说明不可能再选择若干个和为 \textit{rest}rest 的数放入列表了。此时,我们就可以直接回溯。
class Solution {
private:
vector<pair<int, int>> freq;
vector<vector<int>> ans;
vector<int> sequence;
public:
void dfs(int pos, int rest) {
if (rest == 0) {
ans.push_back(sequence);
return;
}
if (pos == freq.size() || rest < freq[pos].first) {
return;
}
dfs(pos + 1, rest);
int most = min(rest / freq[pos].first, freq[pos].second);
for (int i = 1; i <= most; ++i) {
sequence.push_back(freq[pos].first);
dfs(pos + 1, rest - i * freq[pos].first);
}
for (int i = 1; i <= most; ++i) {
sequence.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
for (int num: candidates) {
if (freq.empty() || num != freq.back().first) {
freq.emplace_back(num, 1);
} else {
++freq.back().second;
}
}
dfs(0, target);
return ans;
}
};





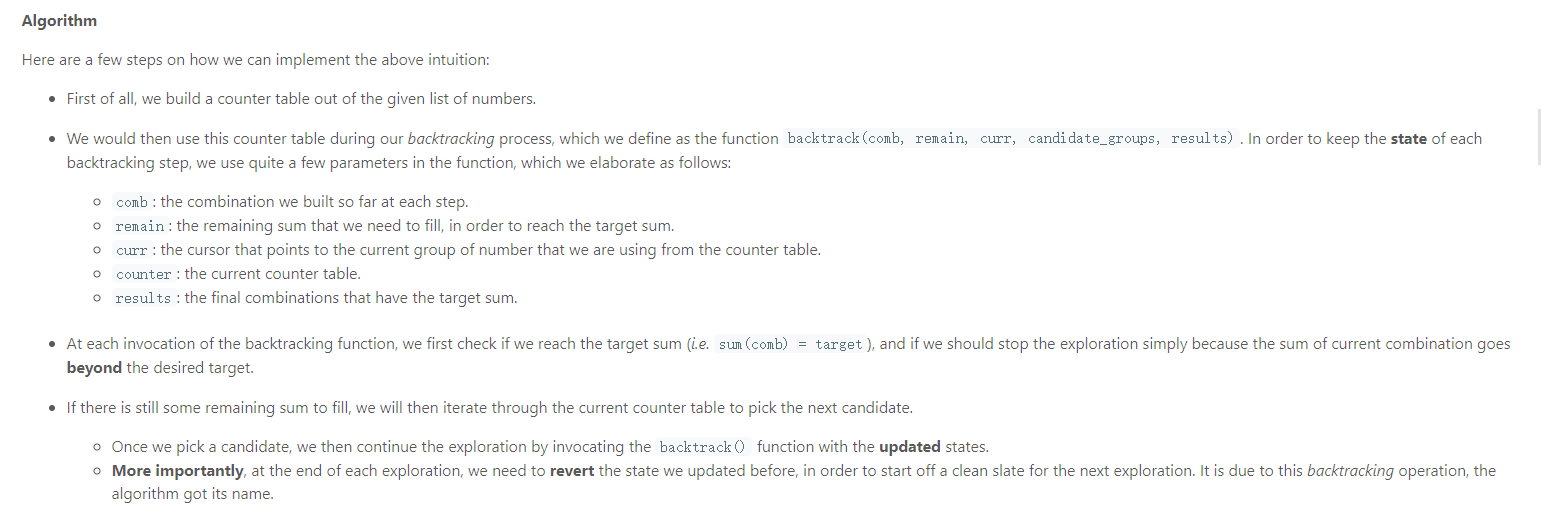
回溯: 46. 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
Solution1 暴力
Solution2 回溯
class Solution {
public:
void backtrack(vector<vector<int>>& res, vector<int>& output, int first, int len){
// 所有数都填完了
if (first == len) {
res.emplace_back(output);
return;
}
for (int i = first; i < len; ++i) {
// 动态维护数组
swap(output[i], output[first]);
// 继续递归填下一个数
backtrack(res, output, first + 1, len);
// 撤销操作
swap(output[i], output[first]);
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int> > res;
backtrack(res, nums, 0, (int)nums.size());
return res;
}
};
回溯:22. 括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”]
示例 2:
输入:n = 1
输出:[“()”]
提示:
1 <= n <= 8





Solution1 暴力

Solution2 递归 + 剪枝

回溯: 17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例 1:
输入:digits = “23”
输出:[“ad”,“ae”,“af”,“bd”,“be”,“bf”,“cd”,“ce”,“cf”]
示例 2:
输入:digits = “”
输出:[]
示例 3:
输入:digits = “2”
输出:[“a”,“b”,“c”]
提示:
0 <= digits.length <= 4
digits[i] 是范围 [‘2’, ‘9’] 的一个数字。
Solution 1 暴力
Simple and efficient iterative solution.
Explanation with sample input "123"
Initial state:
result = {""}
Stage 1 for number "1":
result has {""}
candiate is "abc"
generate three strings "" + "a", ""+"b", ""+"c" and put into tmp,
tmp = {"a", "b","c"}
swap result and tmp (swap does not take memory copy)
Now result has {"a", "b", "c"}
Stage 2 for number "2":
result has {"a", "b", "c"}
candidate is "def"
generate nine strings and put into tmp,
"a" + "d", "a"+"e", "a"+"f",
"b" + "d", "b"+"e", "b"+"f",
"c" + "d", "c"+"e", "c"+"f"
so tmp has {"ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf" }
swap result and tmp
Now result has {"ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf" }
Stage 3 for number "3":
result has {"ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf" }
candidate is "ghi"
generate 27 strings and put into tmp,
add "g" for each of "ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"
add "h" for each of "ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"
add "h" for each of "ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"
so, tmp has
{"adg", "aeg", "afg", "bdg", "beg", "bfg", "cdg", "ceg", "cfg"
"adh", "aeh", "afh", "bdh", "beh", "bfh", "cdh", "ceh", "cfh"
"adi", "aei", "afi", "bdi", "bei", "bfi", "cdi", "cei", "cfi" }
swap result and tmp
Now result has
{"adg", "aeg", "afg", "bdg", "beg", "bfg", "cdg", "ceg", "cfg"
"adh", "aeh", "afh", "bdh", "beh", "bfh", "cdh", "ceh", "cfh"
"adi", "aei", "afi", "bdi", "bei", "bfi", "cdi", "cei", "cfi" }
Finally, return result.
Soulution 2 回溯
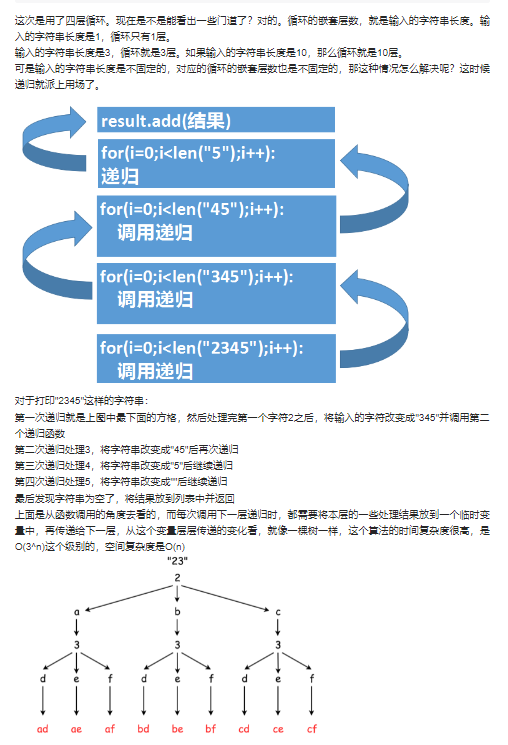

Solution 3 队列
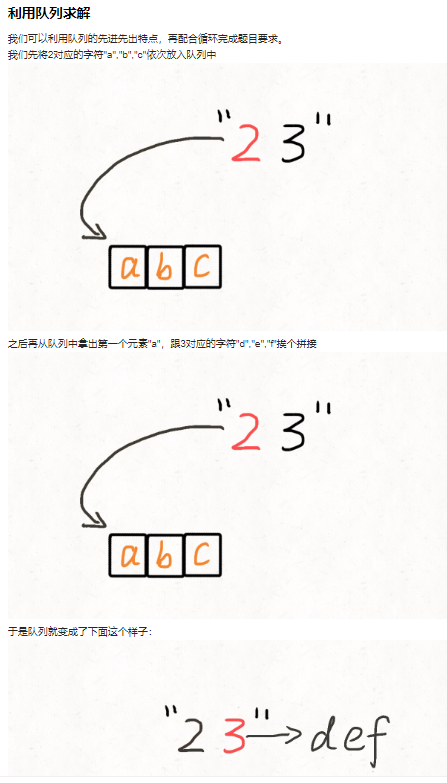
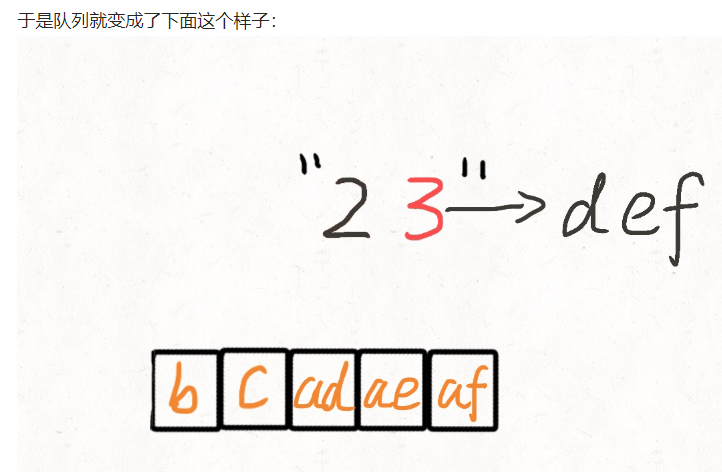

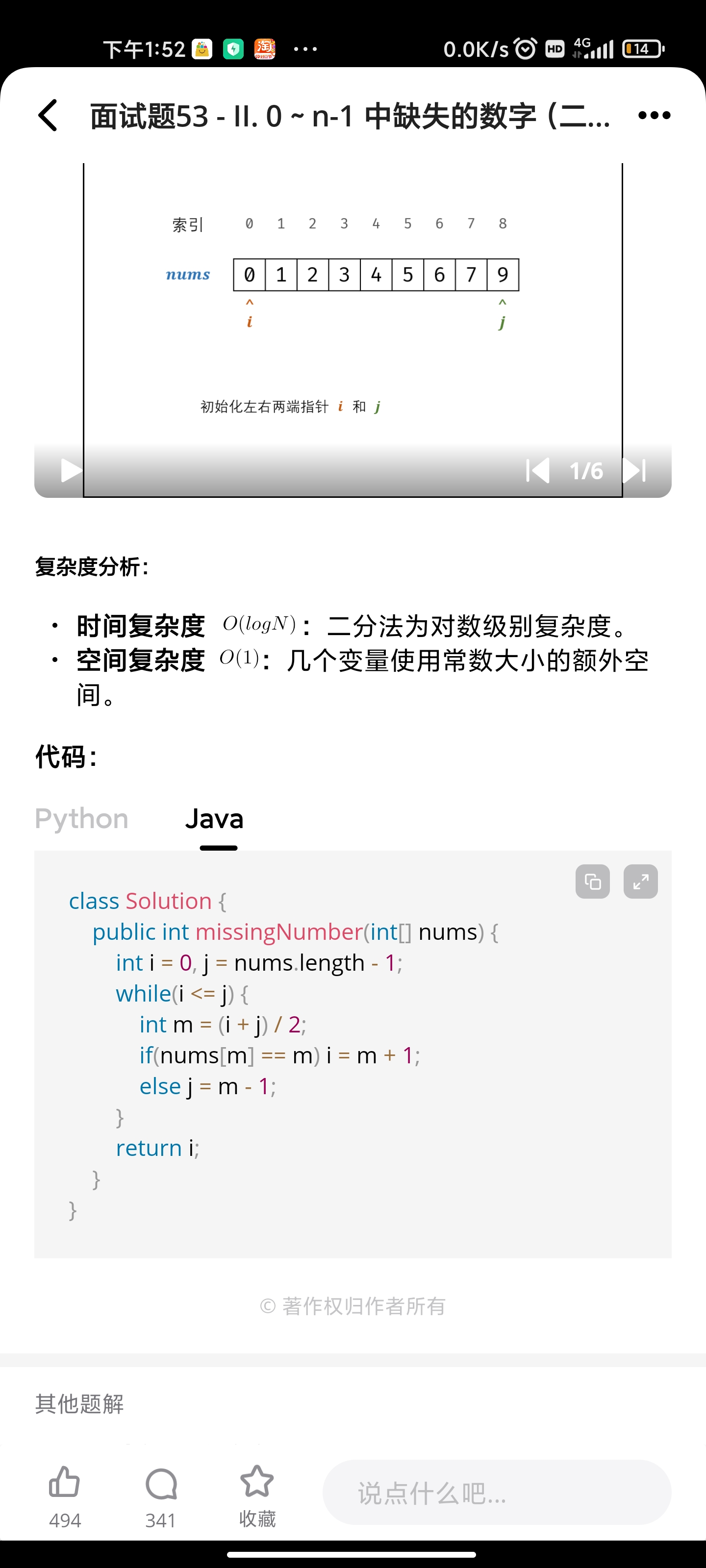
二分:0~n-1中缺失的数字

二分:162. 寻找峰值
峰值元素是指其值严格大于左右相邻值的元素。
给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞ 。
你必须实现时间复杂度为 O(log n) 的算法来解决此问题。
示例 1:
输入:nums = [1,2,3,1]
输出:2
解释:3 是峰值元素,你的函数应该返回其索引 2。
示例 2:
输入:nums = [1,2,1,3,5,6,4]
输出:1 或 5
解释:你的函数可以返回索引 1,其峰值元素为 2;
或者返回索引 5, 其峰值元素为 6。
提示:
1 <= nums.length <= 1000
-231 <= nums[i] <= 231 - 1
对于所有有效的 i 都有 nums[i] != nums[i + 1]
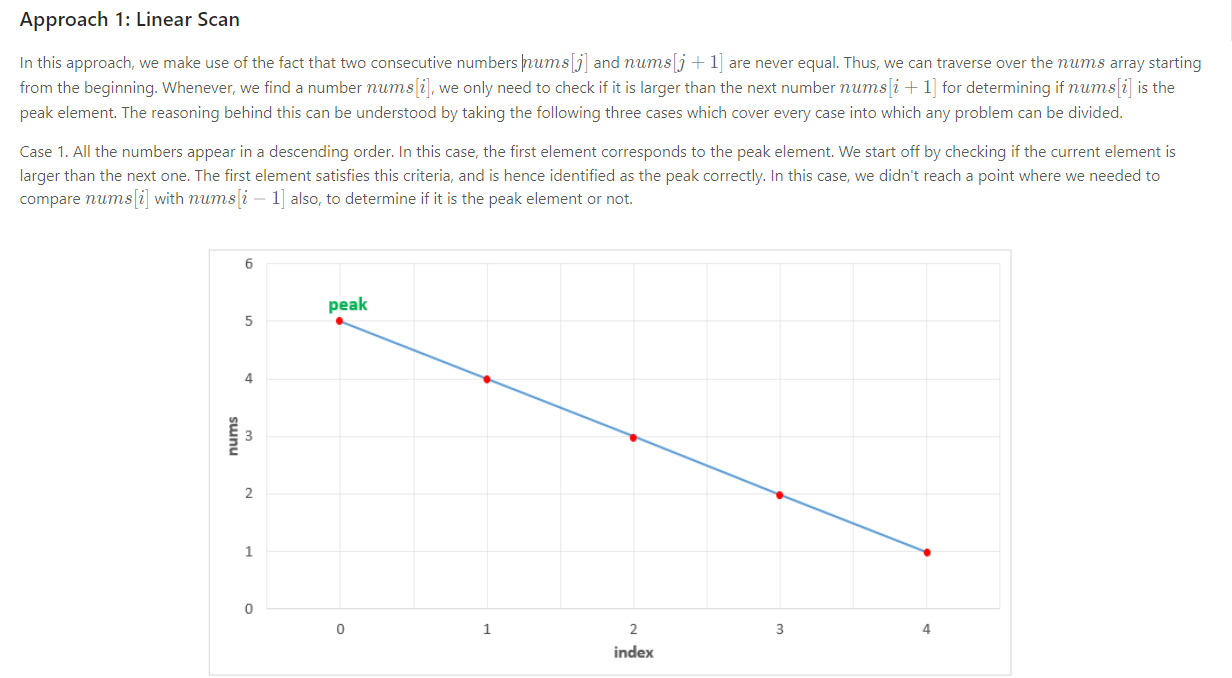
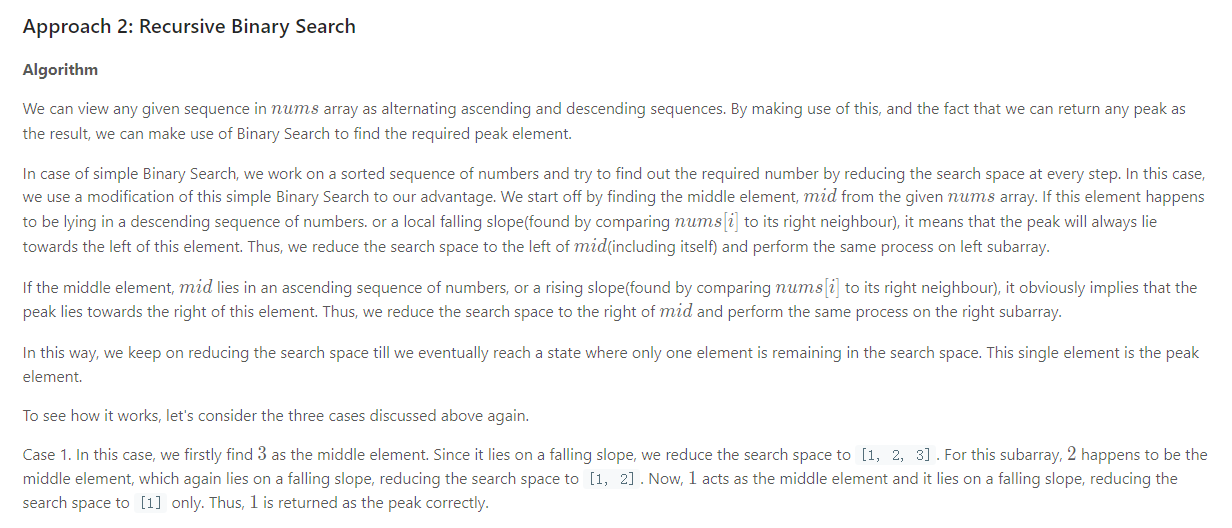
Solution1 暴力
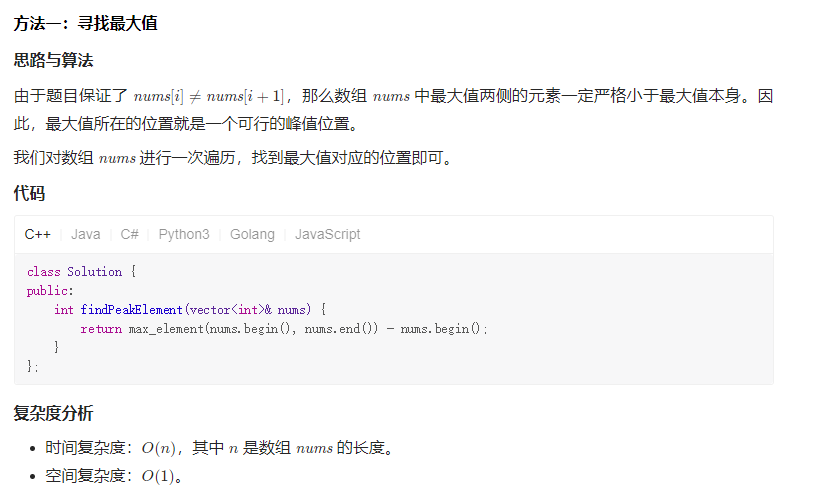
Solution2 二分法
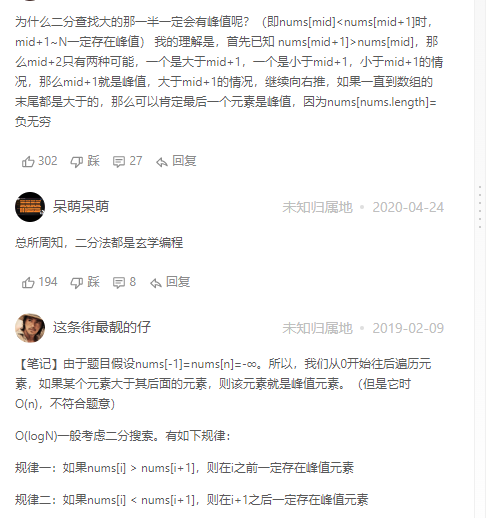
int findPeakElement(vector<int>& nums) {
int left = 0, right = nums.size() - 1;
while (left < right ) {
int mid = left + (right - left) / 2;
if (nums[mid] < nums[mid + 1]) {
left = mid+1;
} else {
right = mid+1;
}
}
return left;
}
二分: 旋转数组的最小数字


二分:33. 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
示例 2:
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
示例 3:
输入:nums = [1], target = 0
输出:-1
提示:
1 <= nums.length <= 5000
-104 <= nums[i] <= 104
nums 中的每个值都 独一无二
题目数据保证 nums 在预先未知的某个下标上进行了旋转
-104 <= target <= 104
Solution1 暴力
Solution2 二分查找


二分:34. 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
提示:
0 <= nums.length <= 105
-109 <= nums[i] <= 109
nums 是一个非递减数组
-109 <= target <= 109
Solution1 暴力
Solution2 二分

二分搜索讲解
https://www.bilibili.com/video/BV1fA4y1o715?spm_id_from=0.0.header_right.history_list.click
寻找target在数组里的左右边界,有如下三种情况:
- 情况一:target 在数组范围的右边或者左边,例如数组{3, 4, 5},target为2或者数组{3, 4, 5},target为6,此时应该返回{-1, -1}
- 情况二:target 在数组范围中,且数组中不存在target,例如数组{3,6,7},target为5,此时应该返回{-1, -1}
- 情况三:target 在数组范围中,且数组中存在target,例如数组{3,6,7},target为6,此时应该返回{1, 1}
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int leftBorder = getLeftBorder(nums, target);
int rightBorder = getRightBorder(nums, target);
// 情况一
if (leftBorder == -2 || rightBorder == -2) return {-1, -1};
// 情况三
if (rightBorder - leftBorder > 1) return {leftBorder + 1, rightBorder - 1};
// 情况二
return {-1, -1};
}
private:
int getRightBorder(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] > target) {
right = middle - 1;
} else { // 寻找右边界,nums[middle] == target的时候更新left
left = middle + 1;
rightBorder = left;
}
}
return rightBorder;
}
int getLeftBorder(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] >= target) { // 寻找左边界,nums[middle] == target的时候更新right
right = middle - 1;
leftBorder = right;
} else {
left = middle + 1;
}
}
return leftBorder;
}
};
二分: 35. 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
Solution1 暴力
public int searchInsert(int[] nums, int target) {
for(int i = 0; i < nums.length;i++){
if(nums[i] >= target){
return i;
}
}
return nums.length;
}
Solution2 二分
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
int n = nums.size();
int left = 0;
int right = n; // 定义target在左闭右开的区间里,[left, right) target
while (left < right) { // 因为left == right的时候,在[left, right)是无效的空间
int middle = left + ((right - left) >> 1);
if (nums[middle] > target) {
right = middle; // target 在左区间,在[left, middle)中
} else if (nums[middle] < target) {
left = middle + 1; // target 在右区间,在 [middle+1, right)中
} else { // nums[middle] == target
return middle; // 数组中找到目标值的情况,直接返回下标
}
}
// 分别处理如下四种情况
// 目标值在数组所有元素之前 [0,0)
// 目标值等于数组中某一个元素 return middle
// 目标值插入数组中的位置 [left, right) ,return right 即可
// 目标值在数组所有元素之后的情况 [left, right),这是右开区间,return right 即可
return right;
}
};
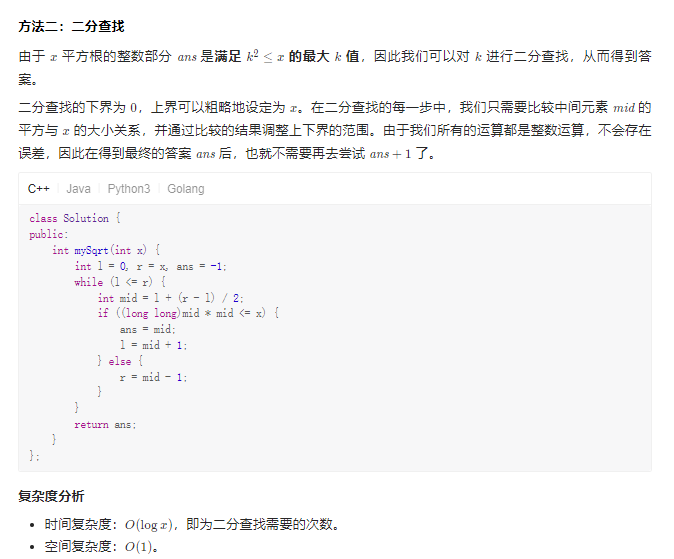
二分:69. x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
示例 1:
输入:x = 4
输出:2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842…, 由于返回类型是整数,小数部分将被舍去。
提示:
0 <= x <= 231 - 1
Time Complexity: O(logn) | due to binary search using while loop.
Space Complexity: O(1) | as only 4 variables are initialized at the beginning. Which is constant irrespective of given input.
long long s=0, e=x, ans, mid; //long long due to some of test cases overflows integer limit.
while(s<=e){
mid=(s+e)/2;
if(mid*mid==x) return mid; //if the 'mid' value ever gives the result, we simply return it.
else if(mid*mid<x){
s=mid+1; //if 'mid' value encounterted gives lower result, we simply discard all the values lower than mid.
ans=mid; //an extra pointer 'ans' is maintained to keep track of only lowest 'mid' value.
}
else e=mid-1; //if 'mid' value encountered gives greater result, we simply discard all the values greater than mid.
}
return ans;
Solution1 暴力
Solution2 二分搜索
:287. 寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间。
示例 1:
输入:nums = [1,3,4,2,2]
输出:2
示例 2:
输入:nums = [3,1,3,4,2]
输出:3
提示:
1 <= n <= 105
nums.length == n + 1
1 <= nums[i] <= n
nums 中 只有一个整数 出现 两次或多次 ,其余整数均只出现 一次
进阶:
如何证明 nums 中至少存在一个重复的数字?
你可以设计一个线性级时间复杂度 O(n) 的解决方案吗?
Overview
Finding the Duplicate Number is a classic problem, and as such there are many different ways to approach it; a total of 7 approaches are presented here. The first 4 approaches involve rearranging or modifying elements of the array, and hence do not meet the constraints specified in the problem statement. However, they are included here since they are more feasible to come up with as the first approach in an interview setting. Since each approach is independent of the other approaches, they can be read in any order.
Proof
Proving that at least one duplicate must exist in numsnums is an application of the pigeonhole principle. Here, each number in numsnums is a "pigeon" and each distinct number that can appear in numsnums is a "pigeonhole." Because there are n+1n+1 numbers and nn distinct possible numbers, the pigeonhole principle implies that if you were to put each of the n + 1n+1 pigeons into nn pigeonholes, at least one of the pigeonholes would have 2 or more pigeons.
Approach 1: Sort
Note: This approach modifies individual elements and does not use constant space, and hence does not meet the problem constraints. However, it utilizes a fundamental concept that can help solve similar problems.
Intuition
In an unsorted array, duplicate elements may be scattered across the array. However, in a sorted array, duplicate numbers will be next to each other.
Algorithm
Sort the input array (numsnums).
Iterate through the array, comparing the current number to the previous number (i.e. compare nums[i]nums[i] to nums[i - 1]nums[i−1] where i > 0i>0).
Return the first number that is equal to its predecessor.
Complexity Analysis
Time Complexity: O(n \log n)O(nlogn)
Sorting takes O(n \log n)O(nlogn) time. This is followed by a linear scan, resulting in a total of O(n \log n)O(nlogn) + O(n)O(n) = O(n \log n)O(nlogn) time.
Space Complexity: O(\log n)O(logn) or O(n)O(n)
The space complexity of the sorting algorithm depends on the implementation of each programming language:
In Java, Arrays.sort() for primitives is implemented using a variant of the Quick Sort algorithm, which has a space complexity of O(\log n)O(logn)
In C++, the sort() function provided by STL uses a hybrid of Quick Sort, Heap Sort and Insertion Sort, with a worst case space complexity of O(\log n)O(logn)
In Python, the sort() function is implemented using the Timsort algorithm, which has a worst-case space complexity of O(n)O(n)
Approach 2: Set
Note: This approach does not use constant space, and hence does not meet the problem constraints. However, it utilizes a fundamental concept that can help solve similar problems.
Intuition
As we traverse the array, we need a way to "remember" values that we've seen. If we come across a number that we've seen before, we've found the duplicate. An efficient way to record the seen values is by adding each number to a set as we iterate over the numsnums array.
Algorithm
In order to achieve linear time complexity, we need to be able to insert elements into a data structure and look them up in constant time. A HashSet/unordered_set is well suited for this purpose. Initialize an empty hashset, seenseen.
Iterate over the array and first check if the current element exists in the hashset (seenseen).
If it does exist in the hashset, that number is the duplicate and can be returned right away.
Otherwise, insert the current element into seenseen, move to the next element in the array and repeat step 2.
Complexity Analysis
Time Complexity: O(n)O(n)
HashSet insertions and lookups have amortized constant time complexities. Hence, this algorithm requires linear time, since it consists of a single for loop that iterates over each element, looking up the element and inserting it into the set at most once.
Space Complexity: O(n)O(n)
We use a set that may need to store at most nn elements, leading to a linear space complexity of O(n)O(n).
Solution1 二分法
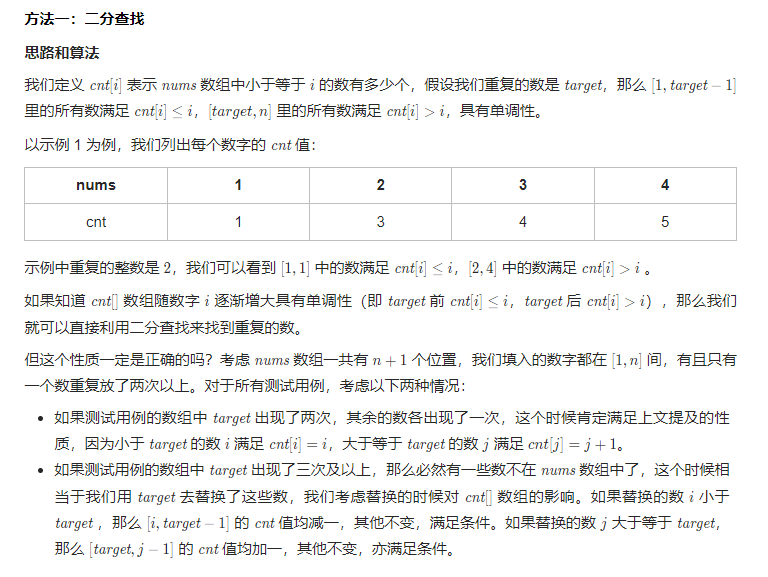
class Solution {
public:
int findDuplicate(vector<int>& nums) {
int n = nums.size();
int l = 1, r = n - 1, ans = -1;
while (l <= r) {
int mid = (l + r) >> 1;
int cnt = 0;
for (int i = 0; i < n; ++i) {
cnt += nums[i] <= mid;
}
if (cnt <= mid) {
l = mid + 1;
} else {
r = mid - 1;
ans = mid;
}
}
return ans;
}
};
Solution2 二进制
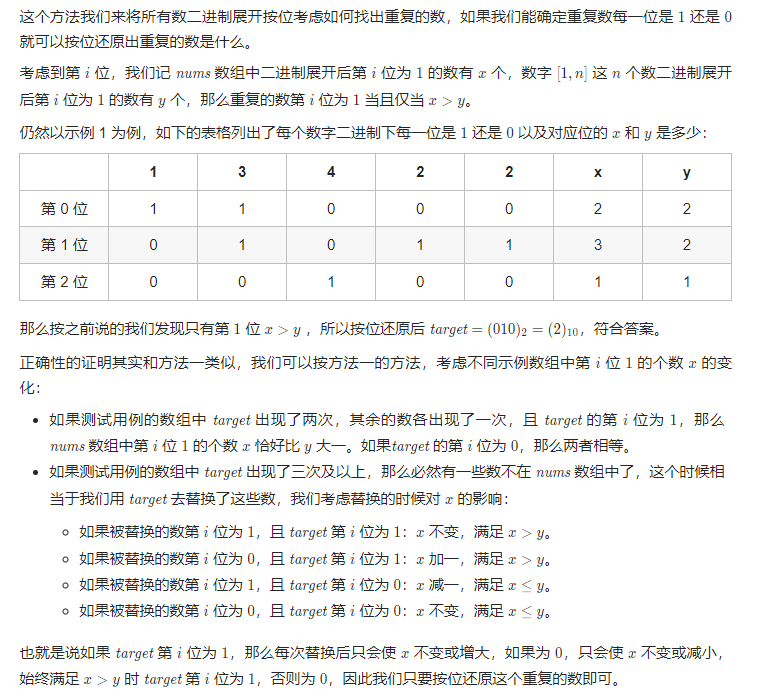
class Solution {
public:
int findDuplicate(vector<int>& nums) {
int n = nums.size(), ans = 0;
// 确定二进制下最高位是多少
int bit_max = 31;
while (!((n - 1) >> bit_max)) {
bit_max -= 1;
}
for (int bit = 0; bit <= bit_max; ++bit) {
int x = 0, y = 0;
for (int i = 0; i < n; ++i) {
if (nums[i] & (1 << bit)) {
x += 1;
}
if (i >= 1 && (i & (1 << bit))) {
y += 1;
}
}
if (x > y) {
ans |= 1 << bit;
}
}
return ans;
}
};
Solution3 快慢指针


class Solution {
public:
int findDuplicate(vector<int>& nums) {
int slow = 0, fast = 0;
do {
slow = nums[slow];
fast = nums[nums[fast]];
} while (slow != fast);
slow = 0;
while (slow != fast) {
slow = nums[slow];
fast = nums[fast];
}
return slow;
}
};
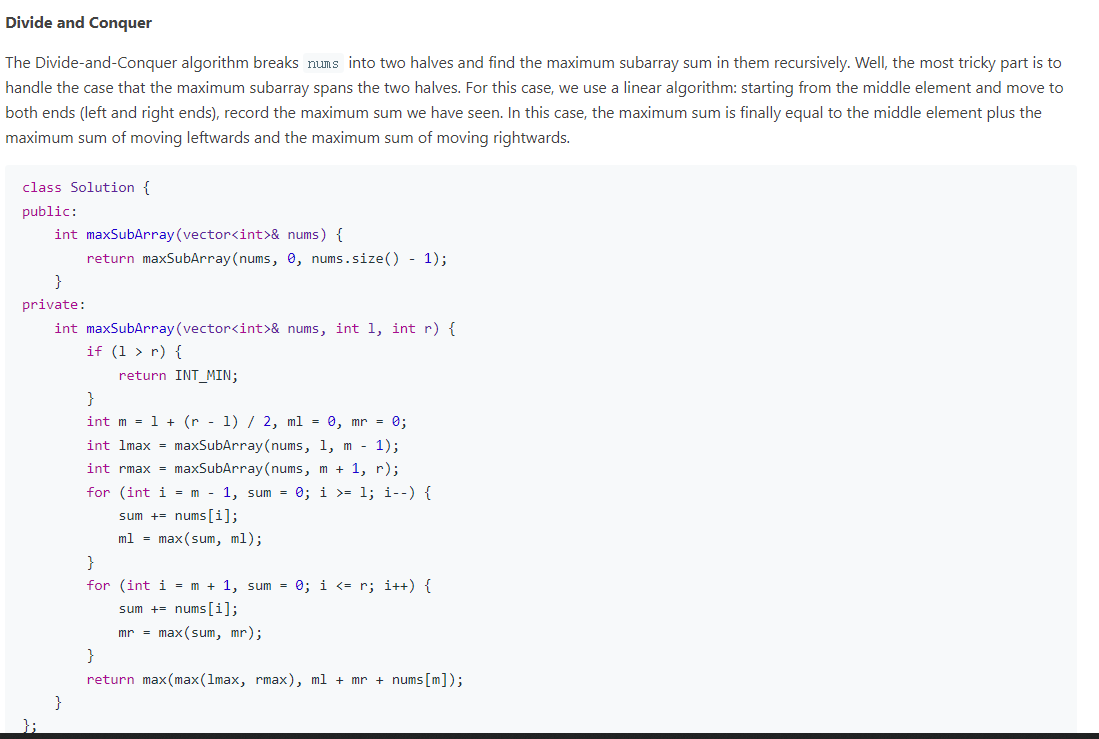
动态规划:53. 最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1]
输出:1
示例 3:
输入:nums = [5,4,-1,7,8]
输出:23
提示:
1 <= nums.length <= 105
-104 <= nums[i] <= 104
Solution1 暴力
Solution2 动态规划

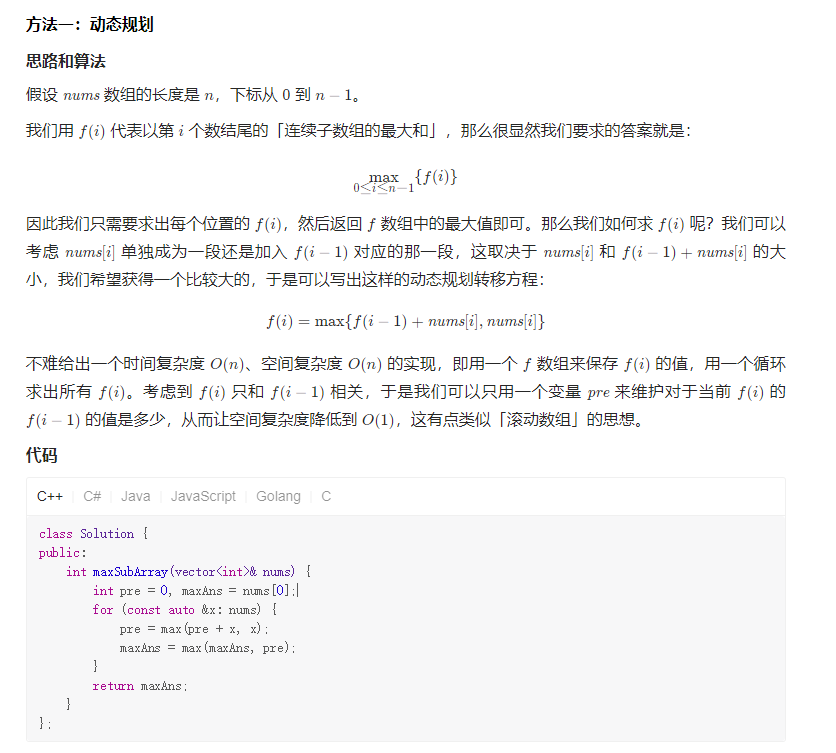

Solution3 分治
动态规划:62. 不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
输入:m = 3, n = 7
输出:28
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
- 向右 -> 向下 -> 向下
- 向下 -> 向下 -> 向右
- 向下 -> 向右 -> 向下
示例 3:
输入:m = 7, n = 3
输出:28
示例 4:
输入:m = 3, n = 3
输出:6
提示:
1 <= m, n <= 100
题目数据保证答案小于等于 2 * 109
Since the robot can only move right and down, when it arrives at a point, it either arrives from left or above. If we use dp[i][j] for the number of unique paths to arrive at the point (i, j), then the state equation is dp[i][j] = dp[i][j - 1] + dp[i - 1][j]. Moreover, we have the base cases dp[0][j] = dp[i][0] = 1 for all valid i and j.
class Solution {
public:
int uniquePaths(int m, int n) {
vector<vector<int>> dp(m, vector&l 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









