




文章目录
一、原子操作CAS与锁实现
1. 原子操作
什么是原子操作? (Compare-And-Swap)
原子变量对应的操作,在多线程环境下,确保对共享变量的操作在执行是不会被干扰从而避免静态条件。
定义:原子操作指的是在执行过程中不可被中断的操作,该操作要么完整地执行完毕,要么完全不执行,不存在执行到一半的中间状态。
在多线程或者多进程环境里,原子操作能够保证在同一时刻仅有一个线程或者进程可以对共享资源进行访问和修改,从而避免数据竞争和不一致的问题。
ABA 问题
CAS 操作在比较内存位置的值时,只关注值是否相等,而不关心值的变化过程。如果一个值从 A 变为 B,再从 B 变回 A,CAS 操作会认为值没有发生变化,从而继续进行更新操作。这种情况被称为 ABA 问题。
自旋开销
在 CAS 操作失败时,通常会采用自旋的方式不断重试,直到操作成功。如果竞争非常激烈,自旋会消耗大量的 CPU 资源,降低系统性能。
2. 互斥锁和自旋锁
为什么要在多线程并发中引入锁?
在多线程并发中引入锁的核心目的是为了解决共享资源竞争和执行顺序不确定性带来的问题。例如我现在有4个线程,每个线程的操作都是对变量a进行++,一共500次。如果不加锁的话,两个线程可能会同时对a进行操作,这时候加入a=10,经过两个线程操作后期望值为12,但是两个线程同时操作的话可能结果就为11(同时加1)。
互斥锁 与 自旋锁(Mutex & Spin Lock)
- 互斥锁在线性运行时,其余线程会让出CPU,没有资源时会引起线程上下文切换,转入阻塞态。
- 自旋锁在线程运行时,其余线程会在用户态空转自旋检测,检测资源是否就绪,空转CPU,不会进入阻塞态,如果当前有锁没释放会直接进入就绪态,等待自己被下一次调度。
- 互斥锁 适用于锁的持有时间较长、线程竞争较为激烈的场景;例如对数据库的读写操作、文件的访问。
自旋锁 适用于锁的持有时间非常短、线程竞争不激烈的场景;例如在一些内核代码中对临界区的保护
当该系统中间连接池操作比较耗时时,选用互斥锁效率比较高,反之自旋锁
对于某个变量,想在多线程环境下,让他避免静态的情况,确保它的数据安全,可以直接声明它为原子变量类型。此时方法效率: 原子变量 > 自旋锁 > 互斥锁
3. 原子性
什么是原子性?(原子锁)
原子性可以保证在同一时刻只有一个线程或进程能够对共享资源进行特定操作,避免了多个线程或进程同时修改共享资源而引发的错误。
这个整体要么都做要么还没做, 不会让其他核心运行线程看到执行的一个中间结果的状态。
本质:基于硬件支持的原子操作(如CAS指令)实现,直接依赖CPU指令保证操作的不可分割性
特点:无锁(Lock-Free)设计:无需显式加锁,通过原子指令直接操作共享变量。粒度极细:仅能保护单一变量(如整型、指针)的原子性,无法覆盖复合操作。
单核或多核处理器实现原子性

4. 存储体系结构
CPU缓存结构(cache)
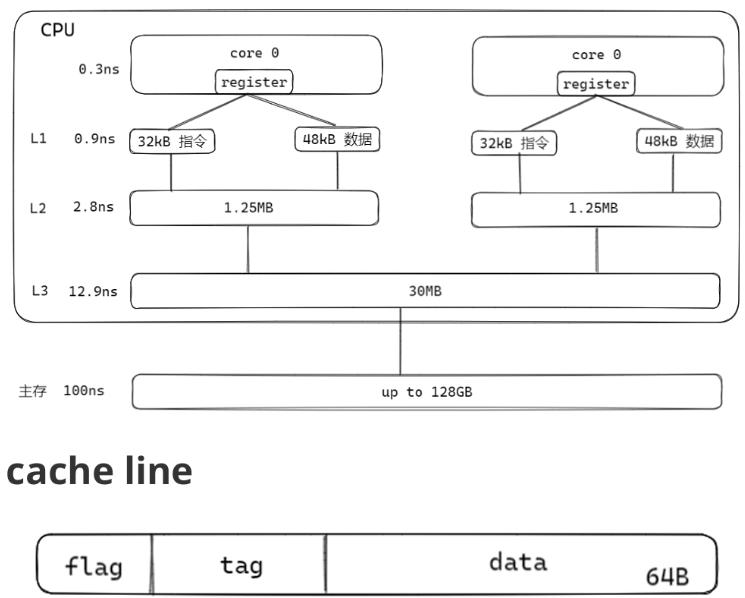
cache 为了解决CPU运算速度与内存访问速度不匹配的问题。
cpu采用多级缓存来解决cpu与内存的速度差异,可以通过预先加载的方式弥补差距。
cache line是缓存的最小单位,里面的tag代表的是这个单位是否被加载到缓存内。
CPU如何读写数据 (写回策略)


举一个例子:CPU核心A修改共享数据X=42
- 核心A写入X=42:
- 缓存行(cache block)标记为Modified(脏)
- 数据未立即写入主内存
- 核心B尝试读取X:
- 缓存一致性协议检测到核心A的缓存行状态为Modified
- 核心A将脏数据写回主内存,并降级缓存行状态为Shared
- 核心B从主内存加载最新数据
- 核心A的缓存行被替换:
- 若状态为Modified,必须先将数据写回内存
- 缓存行状态变为Invalid
缓存一致性问题 (多核CPU + 写回策略引起)
产生原因:CPU是多核的,会访问到未同步的数据,基于写回策略引起
解决方法:
写传播(总线嗅探bus snooping 监听发布)
定义:写传播是解决缓存一致性问题的一种基本策略,其核心目标是确保在多处理器系统中,当一个处理器对共享数据进行写操作时,这个写操作的结果能够被其他处理器感知到,进而保证所有处理器的缓存中该数据副本的一致性。
工作原理:当一个处理器对其缓存中的数据进行写操作时,需要将这个写操作传播到其他处理器的缓存或者主存中。具体的传播方式可以分为写直达(Write-Through)和写回(Write-Back)两种:
- 写直达:处理器在对缓存进行写操作的同时,也会将数据写回到主存中。这样可以保证主存中的数据始终是最新的,但缺点是每次写操作都需要访问主存,会增加写操作的延迟。
- 写回:处理器只对缓存进行写操作,只有当缓存行被替换时,才将修改后的数据写回到主存中。这种方式减少了对主存的访问次数,提高了写操作的性能,但会增加缓存一致性协议的复杂度。
事务串行化(锁指令)
定义:事务串行化是数据库管理系统中用于保证事务并发执行正确性的一种隔离级别。事务是一组不可分割的数据库操作序列,事务串行化要求所有事务按照某种顺序依次执行,就好像这些事务是一个接一个串行执行的一样,从而避免了并发执行可能带来的数据不一致问题。
工作原理:在事务串行化隔离级别下,数据库系统会对事务进行排序,并按照这个顺序依次执行。为了实现这一点,数据库系统通常会使用锁机制来保证同一时间只有一个事务可以访问和修改共享数据。当一个事务获得了所需的锁后,其他事务必须等待该事务释放锁后才能继续执行。
优点:可以保证事务的一致性和隔离性,避免了脏读、不可重复读和幻读等并发问题。
缺点:并发性能较低,因为事务必须串行执行,会导致大量的事务等待时间,降低了系统的吞吐量
MESI一致性协议(四种状态)
MESI协议 是一个基于失效的缓存一致性协议,支持 write-back 写回缓存的常用协议。主要原理:通过总线嗅探策略(将读写请求通过总线广播给所有核心,核心根据本地状态进行响应)
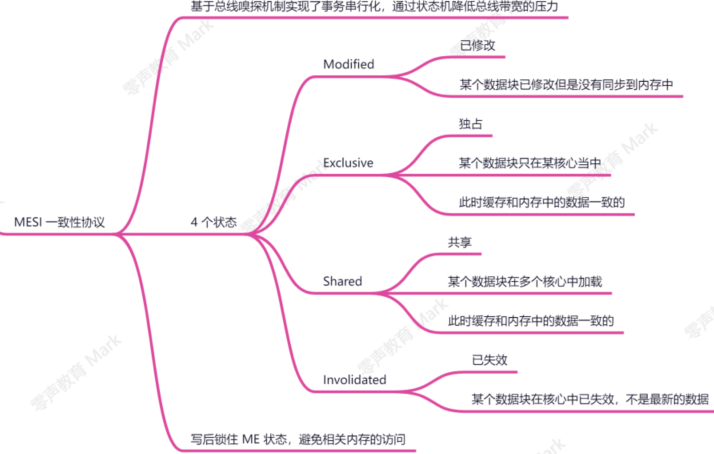
结合下面这张状态机图来看:
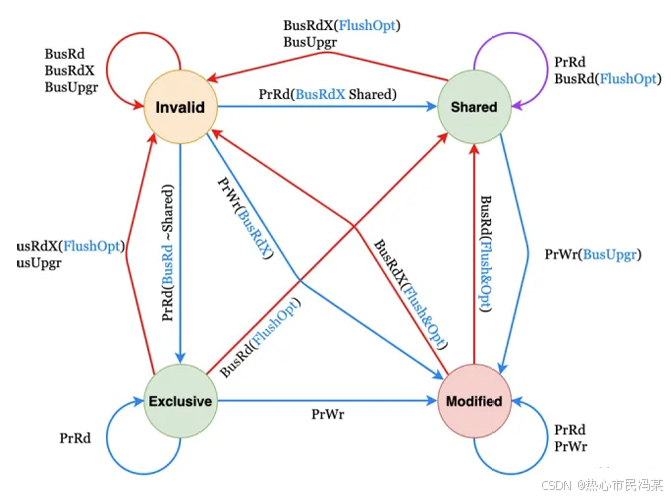
图中的事件解析:
PrRd:核心请求从换存块中读出数据;
PrWr:核心请求向缓存块写入数据;
BusRd:总线嗅探器收到来自其他核心的读出缓存请求;
BusRdX:总线嗅探器收到另一核心写⼀个其不拥有的缓存块的 请求;
BusUpgr:总线嗅探器收到另一核心写⼀个其拥有的缓存块的 请求;
Flush:总线嗅探器收到另一核心把一个缓存块写回到主存的请 求;
FlushOpt:总线嗅探器收到一个缓存块被放置在总线以提供给另一核心的请求,和 Flush 类似,但只不过是从缓存到缓存的传输请求。
5. 内存序
为什么有内存序问题
由于 CPU指令优化重排 | 编译器优化重排

下面主要介绍一下原子操作中的内存模型,作用是对同一时间的读写操作进行排序。在不同的 CPU 架构上,这些模型的具体实现方式可能不同,但是C++11帮你屏蔽了内部细节,不用考虑内存屏障,只要符合上面的使用规则,就能得到想要的效果。
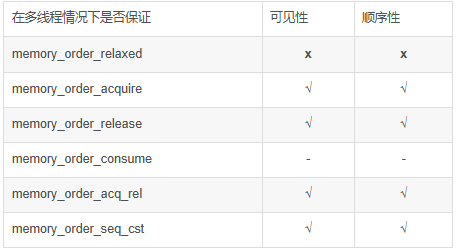
内存序分类(6->5)
6种内存序之间还有依赖关系: 因果关系==> 提升效率优化
-
memory_order_relaxed:松散内存序,只用来保证对原子对 象的操作是原子的,在不需要保证顺序时使用;
-
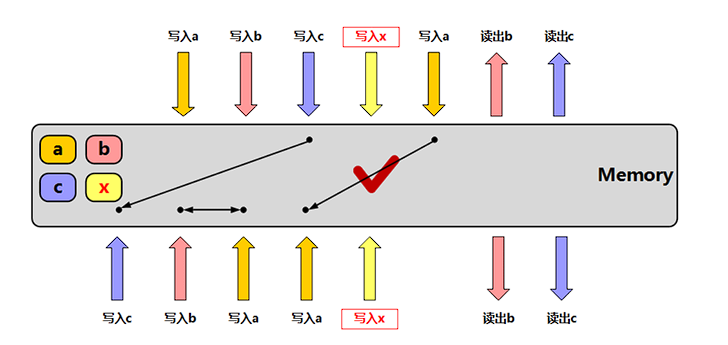
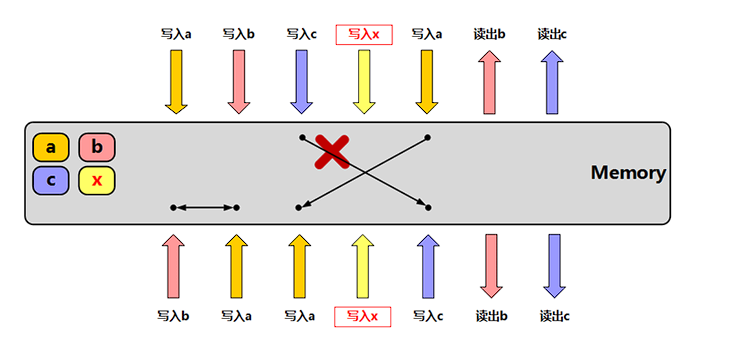
memory_order_release:释放操作,在写入某原子对象时, 当前线程的任何前面的读写操作都不允许重排到这个操作的后面 去,并且当前线程的所有内存写入都在对同一个原子对象进行获 取的其他线程可见;
-
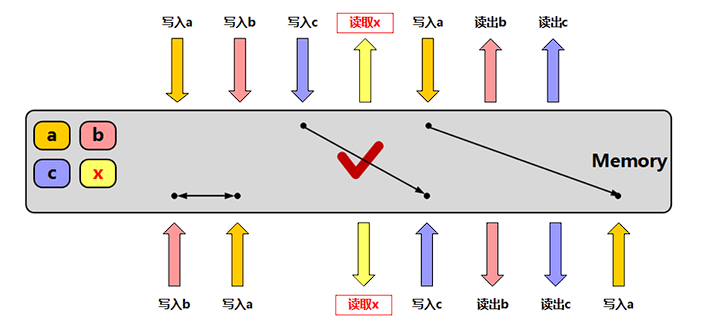
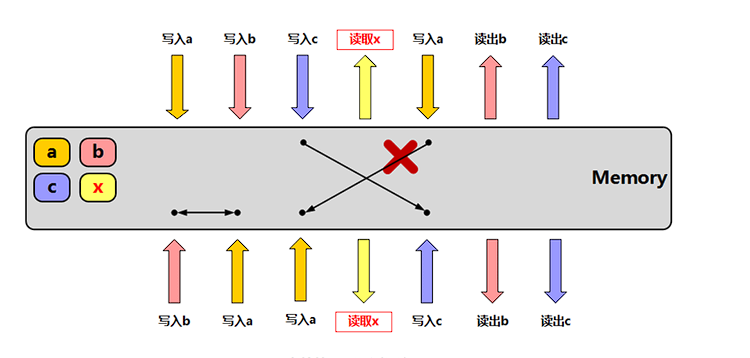
memory_order_acquire:获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见;
-
memory_order_consume:不建议使用; -
memory_order_acq_rel:获得释放操作,一个读‐修改‐写操作 同时具有获得语义和释放语义,即它前后的任何读写操作都不允 许重排,并且其他线程在对同一个原子对象释放之前的所有内存 写入都在当前线程可见,当前线程的所有内存写入都在对同一个 原子对象进行获取的其他线程可见;
-
memory_order_seq_cst:顺序一致性语义,对于读操作相当 于获得,对于写操作相当于释放,对于读‐修改‐写操作相当于获 得释放,是所有原子操作的默认内存序,并且会对所有使用此模 型的原子操作建立一个全局顺序,保证了多个原子变量的操作在 所有线程里观察到的操作顺序相同,当然它是最慢的同步模型。
eg.原子变量来实现指令重排
#include <atomic>
#include <thread>
#include <assert.h>
#include <iostream>
std::atomic<bool> x,y;
std::atomic<int> z;
// 提升效率
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_release); // 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire)); // 3 自旋,等待y被设置为true
if(x.load(std::memory_order_relaxed)) // 4
++z; // 会不会一定等于 1
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
std::cout << z.load(std::memory_order_relaxed) << std::endl;
return 0;
}
这里a、b线程同时进行,a线程中y变量写入用了memory_order_release操作,b线程中y变量用了memory_order_acquire,这就保证了在b线程中必须先获取到y的写入之后才会触发后面的x获取操作,这就使Z一定为1,如果换成released松散操作的话,cpu可能对两个线程中的指令进行重排,结果可能就不为1了。
优秀笔记:
1. 原子操作CAS和锁
2. 原子操作CAS与锁实现
参考学习:https://github.com/0voice


















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









