




集成学习-11-XGBoost算法
XGBoost算法简介
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是一种基于GBDT的算法或者说工程实现。XGBoost的基本思想和GBDT相同,但是做了一些优化,比如二阶导数使损失函数更精准;正则项避免树过拟合;Block存储可以并行计算等。XGBoost具有高效、灵活和轻便的特点,在数据挖掘、推荐系统等领域得到广泛的应用。
XGBoost基础
-
函数的近似计算与泰勒公式


-
一元二次函数的最优解
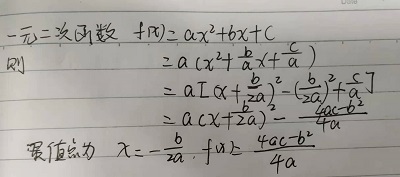
XGBoost模型构建
定义数据集:
XGBoost的目标函数由损失函数和正则化项两部分组成。
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为 :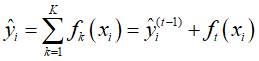
因此,目标函数的构建为:
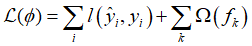
(2) 叠加式的训练(Additive Training)
用GBDT梯度提升树表达方式XGBoost。因此,目标函数可以分解为:

(3) 使用泰勒级数近似目标函数,去除常数项,优化损失函数。

其中 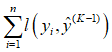 在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故损失函数为:
在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故损失函数为:
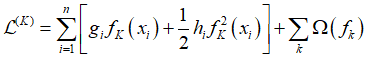
(4) 正则化项展开,去除常数项,优化正则函数
同样的正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度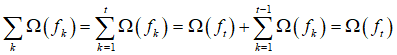
故损失函数最终为:

(5)重新定义一棵树
为了说明如何定义一棵树的问题,我们需要定义几个概念:
第一个概念是样本所在的节点位置 q(x)是一种映射关系
第二个概念是有哪些样本落在节点j上
I
j
=
I_j=
Ij={i∣q(x_i)=j}$
第三个概念是每个结点的预测值
w
q
(
x
)
w_q(x)
wq(x),
第四个概念是模型复杂度
Ω
(
f
K
)
Ω(f_K)
Ω(fK)它可以由叶子节点的个数以及节点函数值来构建:

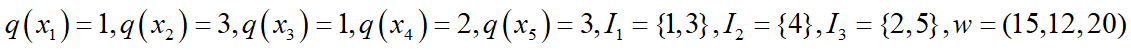

XGBoost应用
import pandas as pd
from sklearn import metrics
from sklearn.model_selection import train_test_split
import xgboost as xgb
import matplotlib.pyplot as plt
# 导入数据集
df = pd.read_csv("./data/diabetes.csv")
data=df.iloc[:,:8]
target=df.iloc[:,-1]
# 切分训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(data,target,test_size=0.2,random_state=7)
# xgboost模型初始化设置
dtrain=xgb.DMatrix(train_x,label=train_y)
dtest=xgb.DMatrix(test_x)
watchlist = [(dtrain,'train')]
# booster:
params={'booster':'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'max_depth':5,
'lambda':10,
'subsample':0.75,
'colsample_bytree':0.75,
'min_child_weight':2,
'eta': 0.025,
'seed':0,
'nthread':8,
'gamma':0.15,
'learning_rate' : 0.01}
# 建模与预测:50棵树
bst=xgb.train(params,dtrain,num_boost_round=50,evals=watchlist)
ypred=bst.predict(dtest)
# 设置阈值、评价指标
y_pred = (ypred >= 0.5)*1
print ('Precesion: %.4f' %metrics.precision_score(test_y,y_pred))
print ('Recall: %.4f' % metrics.recall_score(test_y,y_pred))
print ('F1-score: %.4f' %metrics.f1_score(test_y,y_pred))
print ('Accuracy: %.4f' % metrics.accuracy_score(test_y,y_pred))
print ('AUC: %.4f' % metrics.roc_auc_score(test_y,ypred))
ypred = bst.predict(dtest)
print("测试集每个样本的得分\n",ypred)
ypred_leaf = bst.predict(dtest, pred_leaf=True)
print("测试集每棵树所属的节点数\n",ypred_leaf)
ypred_contribs = bst.predict(dtest, pred_contribs=True)
print("特征的重要性\n",ypred_contribs )
xgb.plot_importance(bst,height=0.8,title='影响糖尿病的重要特征', ylabel='特征')
plt.rc('font', family='Arial Unicode MS', size=14)
plt.show()
参考链接:
[1] https://zhuanlan.zhihu.com/p/162001079.
[2] https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning.

















 6340
6340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









