




 本文深入探讨Titanic数据集的预处理和特征工程,包括数据清洗、特征提取、缺失值填充、特征离散化和分类,以及模型训练与评估,揭示关键特征对生存预测的影响。
本文深入探讨Titanic数据集的预处理和特征工程,包括数据清洗、特征提取、缺失值填充、特征离散化和分类,以及模型训练与评估,揭示关键特征对生存预测的影响。
参照kaggle来学习Python数据分析的思路和方法:https://www.kaggle.com/startupsci/titanic-data-science-solutions
简书上这个写的也蛮有趣可以看一下https://www.jianshu.com/p/9a5bce0de13f
完成整个项目后对如何认识数据、清洗数据有了更具体的认识。数据处理过程中有两点习惯需要养成::尽量备份原数据,在对数据进行操作处理后及时输出查看数据是否得到想要的结果。
数据认识
导入需要的包
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import warnings
warnings.filterwarnings('ignore')
plt.rcParams["patch.force_edgecolor"] = True#边缘线导入数据,读取head来看一下数据的格式
#读取数据
os.chdir('D:\\数据分析\\微专业\\kaggle\\titanic\\')
train_data=pd.read_csv('train.csv')
test_data=pd.read_csv('test.csv')
print(train_data.columns.values)
head=train_data.head()
观察数据的格式
categorical:某些数据可以将样本数据分类,从而选择后续合适的可视化图。可以发现Survived, Sex, Embarked、Pclass都是代表分类的变量。
Numerical:是否存在数值类的数据,如离散、连续、时间序列等。连续数据 Age, Fare. 离散数据SibSp(
Number of Siblings/Spouses Aboard,兄弟姐妹/配偶登船), Parch(Number of Parents/Children Aboard 父母/子女登船)
mixed data types:Ticke、Cabint是字母+数字的格式
train_data.info()
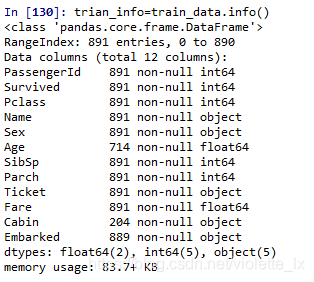
一共891条训练数据
Age\Cabin\Embarked数据存在数据缺失
train_d=train_data.describe()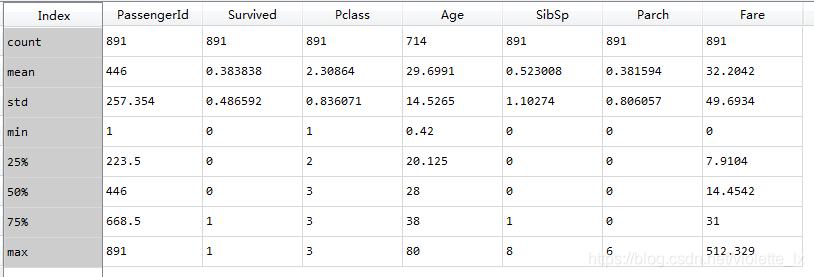
* Passengerid作为唯一标识,共891条数据
* 因Survived仅有0标识去世,1标识存活,mean均值0.38说明38%的存活率
* Age中上到80下至婴儿0.42,均值为29.7,Age-75%说明有75%的乘客小于38岁。
* Parch %75=0 超过75%的样本没有和父母/子女登船
* SibSp %50=0 %75=1 超过%50的样本没有兄弟姐妹/配偶登船(
Nearly 30% of the passengers had siblings and/or spouse aboard. 原文可能是估计?)
* 原文这两条不知道是怎么从describe中解读的
Fares varied significantly with few passengers (<1%) paying as high as $512.
Few elderly passengers (<1%) within age range 65-80.
train_d2=train_data.describe(include='O')describe默认是只计算数值型特征的统计量,输入参数include=['O'],describe可以计算离散型变量的统计特征,得到总数、唯一值个数、出现最多的数据和出现频数。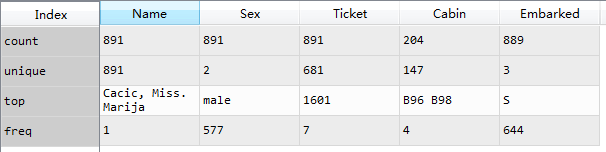
* 姓名是唯一变量
* 男性多于女性,男性占比577/891=65%
* Cabin房间号是重复使用的,多个人共享一个房间
* Ticket不是唯一编号,存在多人同一Ticket的情况
* Embarked登陆港口共3个,S最多
基于数据分析的假设
分析各数据和存活的关联
可能无分析意义的数据:
* Ticket数据重复率过高,不作为特征
* Cabin缺失过度,不作为特征
* Passengerid作为唯一标识没有作为分类的意义
* Name因为格式不标准可能无关不作为分析特征(看到过博客提取title如Mr,Ms作为分析)
数据处理:
* 填充Age,Embarked特征
* 基于Parch和SibSp创建新的数据Family标志船上所有家庭成员数目
* 姓名中提取title作为新的特征
* 可以将Age参数进行分类,转换为多个类别
* 创建Fare特征,可能有助于分析
假设:
* Sex中female女性可能存活率更高
* 儿童(需要设定Age的范围)可能存活率更高
* 一等舱(Pclass=1)可能存活率更高
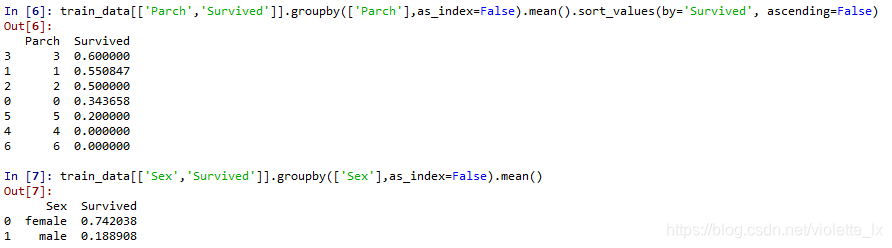
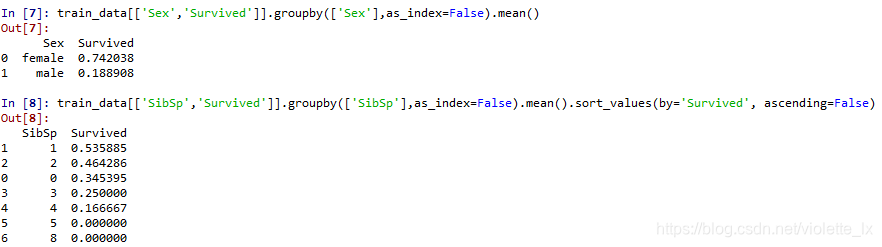
粗略判断分类特征Pclass\Sex\SibSp and Parch和survived的关系
Pclass和sex明显和存活率相关
数据可视化
#复制了一个新的数据来用均值填充一下Age, 查看Age的分布
#真实分布应该去除空值而非填充train_data_age=train_data[train_data['Age'].notnull()]
train_data_age=train_data
train_data_age['Age'].fillna(train_data['Age'].mean()).astype(np.int)
#年龄分布
fig,axes=plt.subplots(1,2,figsize=(18,8))
train_data_age['Age'].hist(bins=80,ax=axes[0])
train_data_age.boxplot(column='Age',showfliers=False,ax=axes[1])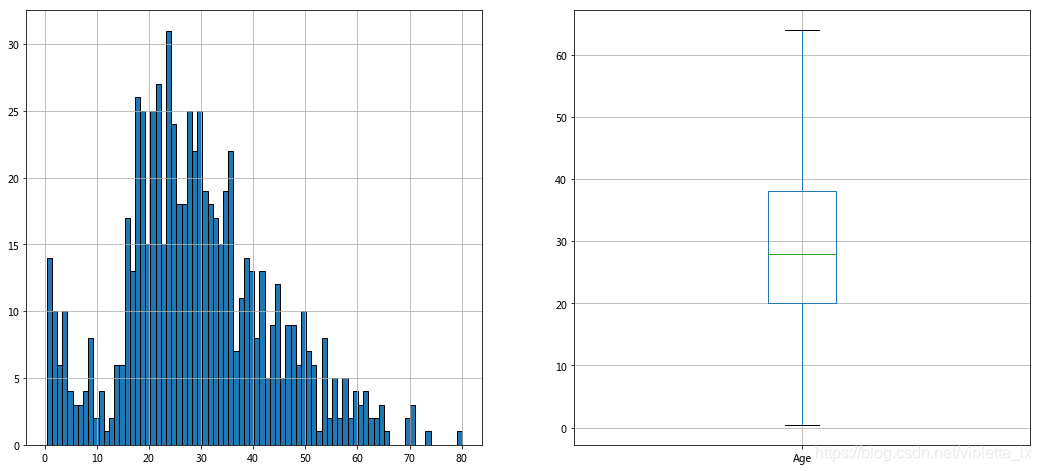
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1787
1787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









