




在进行机器学习项目时,首先需要获取数据,这些数据可以来自数据库、API、网络抓取,或从CSV、Excel等文件中读取。数据可能包含数值、文本和类别等多种特征,但原始数据通常无法直接用于训练模型。
数据预处理包括清洗、填补缺失值和处理异常值。之后,数据向量化将原始表格数据转换为机器学习模型能理解的数值格式。由于大多数算法只能处理数值数据,向量化是至关重要的一步,常用的方法包括独热编码和标签编码。
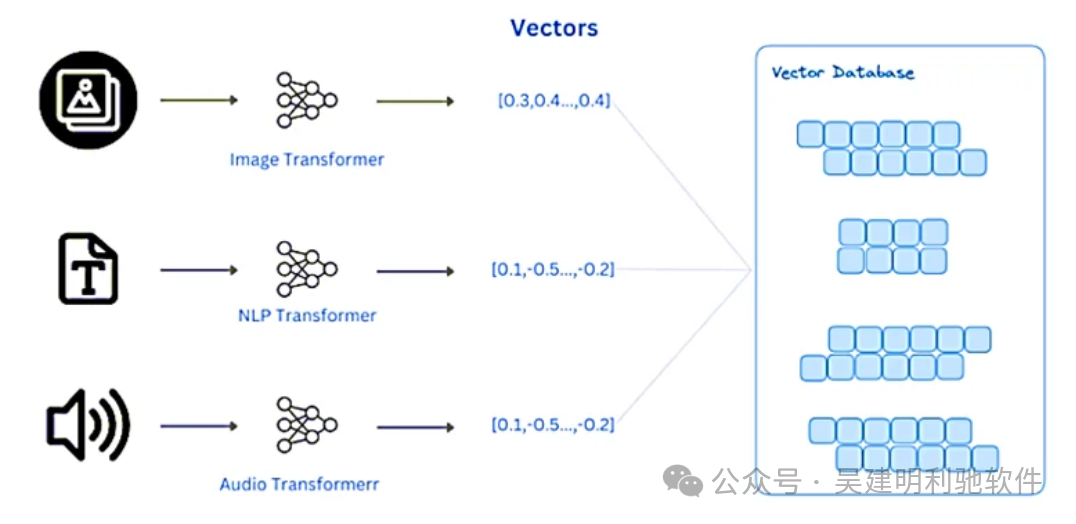
这个步骤对于模型的训练和预测至关重要,因为大多数机器学习算法(如线性回归、决策树、神经网络等)只能处理数值数据,而不是文本、类别或其他非数值数据。
数据向量化有啥用?
- • 机器学习模型的输入 :大多数机器学习模型只能接受数值形式的数据。向量化将原始数据转换成模型可接受的输入形式,使模型能够进行学习和预测。
- • 提高模型性能 :通过合理的向量化处理,模型可以更好地捕捉数据中的信息,提高学习和预测的准确性。例如,将类别变量转换为数值后,算法可以通过数值关系理解类别之间的区别。
- • 数据一致性和规范化 :向量化可以标准化不同格式的输入数据,如将分类、文本或其他类型的特征转换为数值,确保所有输入特征都能够被模型一致地处理。
什么是向量化?
向量化通常指的是将表格中的不同类型的数据(如数值、分类、文本等)转换为向量形式的过程。
常见的向量化方法包括:
数值特征标准化
直接对原始数值进行标准化处理,如归一化、Z-score 标准化,使数据保持在相同的量级上。
在机器学习中,标准化是一种常见的数据预处理技术,旨在将数值特征转换为具有相同尺度的分布。
使用标准化可以提高模型的收敛速度和性能,特别是在使用基于距离的算法(如K-近邻、SVM等)时。
标准化是将 特征的均值转换为0,方差转换为1的过程。
公式如下:
其中:
- • 是标准化后的值。
- • 是原始值。
- • 是特征的均值。
- • 是特征的标准差。
类别特征的编码
对类别数据进行编码,使其能够被机器学习模型处理。
1、 独热编码(One-Hot Encoding) :将每个类别表示为一个二进制向量,适用于没有顺序关系的分类特征,如性别、城市、颜色等。
2、 标签编码(Label Encoding) :将类别变量转换为整数表示,适用于类别有顺序关系的情况。
文本特征的向量化
对文本特征进行处理,通常使用以下方法:
1、 词袋模型(Bag of Words) :统计文本中出现的词汇,形成词频向量。
2、 TF-IDF :基于词语在文档中的频率和其在整个语料库中的逆频率,将文本表示为向量。
词频(TF) :某个词在文档中出现的频率。
逆文档频率(IDF) :衡量词在整个语料库中的普遍重要性,通常通过以下公式计算:
其中, 是文档总数,是包含词 (t) 的文档数。
TF-IDF 计算公式:
其中,是词, 是文档。
3、 词向量(Word Embeddings) :使用预训练的词向量模型(如Word2Vec、GloVe)将文本表示为向量。
如何实现向量化?
向量化可以通过编程实现,下面以Python的常用库为例说明实现过程。
1. 数值特征标准化
示例:
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 创建示例数据
data = pd.DataFrame({
'用户ID': [1, 2, 3, 4],
'浏览时长(秒)': [120, 300, 180, 240]
})
# 实例化标准化器
scaler = StandardScaler()
# 选择要标准化的特征
num_feature = data[['浏览时长(秒)']]
# 执行标准化
scaled_feature = scaler.fit_transform(num_feature)
# 打印标准化后的特征
print(scaled_feature)
# 输出
# [[-1.34164079]
# [ 1.34164079]
# [-0.4472136 ]
# [ 0.4472136 ]]
2. 类别特征的独热编码
import pandas as pd
# 创建示例数据
data = pd.DataFrame({
'颜色': ['红', '绿', '蓝', '绿']
})
# 进行独热编码
one_hot_encoded_data = pd.get_dummies(data, columns=['颜色'])
# 打印编码后的数据
print(one_hot_encoded_data)
# 颜色_红 颜色_绿 颜色_蓝
# 0 1 0 0
# 1 0 1 0
# 2 0 0 1
# 3 0 1 0
3. 文本特征向量化(TF-IDF)
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
# 定义文档
documents = [
"我爱学习机器学习",
"机器学习非常有趣",
"我喜欢学习编程"
]
# 使用 jieba 进行分词
def tokenize(text):
return " ".join(jieba.cut(text))
# 对每个文档进行分词
tokenized_documents = [tokenize(doc) for doc in documents]
# 创建 TF-IDF 向量化器
vectorizer = TfidfVectorizer()
# 拟合并转换文档
tfidf_matrix = vectorizer.fit_transform(tokenized_documents)
# 获取特征名称(词汇)
feature_names = vectorizer.get_feature_names_out()
# 转换为数组并打印
tfidf_array = tfidf_matrix.toarray()
# 输出结果
for i in range(len(documents)):
print(f"文档 {i + 1} 的 TF-IDF 向量:")
for j in range(len(feature_names)):
print(f"{feature_names[j]}: {tfidf_array[i][j]:.4f}")
print()
输出:

在机器学习项目中,表格数据通常会混合多种类型的特征(数值、类别、文本等)。
向量化的关键在于根据特征的类型选择适合的编码方式,并将所有特征统一到一个数值向量中。
完整的处理流程可能涉及多个步骤的向量化组合,然后将其作为机器学习模型的输入。
一个完整示例
下面是一个完整的模拟用户活动日志数据,包含了多种类型的数据,包括数值型、类别型和日期型。这个数据集可以用于用户活动分析的向量化。
模拟数据集:用户活动日志

向量化示例代码
接下来,我们将使用这份数据来进行向量化处理。以下是 Python 代码示例,展示如何对这个数据集进行预处理和向量化。
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# 创建示例数据
data = pd.DataFrame({
'用户ID': [1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5, 5],
'活动类型': ['登录', '浏览商品', '添加到购物车', '购买商品',
'登录', '浏览商品', '添加到购物车', '购买商品',
'登录', '浏览商品', '添加到购物车', '购买商品',
'登录', '浏览商品', '添加到购物车',
'登录', '浏览商品', '浏览商品', '购买商品'],
'日期': pd.to_datetime(['2024-10-01', '2024-10-01', '2024-10-02', '2024-10-02',
'2024-10-01', '2024-10-03', '2024-10-03', '2024-10-04',
'2024-10-02', '2024-10-02', '2024-10-02', '2024-10-02',
'2024-10-01', '2024-10-03', '2024-10-03',
'2024-10-01', '2024-10-01', '2024-10-02', '2024-10-03']),
'浏览时长(秒)': [0, 120, 90, 30, 0, 300, 50, 20, 0, 180, 60, 15, 0, 240, 10, 0, 150, 300, 40],
'购买金额(元)': [0, 0, 0, 299, 0, 0, 0, 150, 0, 0, 0, 499, 0, 0, 0, 0, 0, 0, 250],
'用户设备': ['手机', '手机', '平板', '手机', '电脑', '电脑', '手机', '电脑',
'平板', '手机', '手机', '平板', '手机', '电脑', '电脑',
'手机', '手机', '平板', '手机']
})
# 提取日期特征
data['年'] = data['日期'].dt.year
data['月'] = data['日期'].dt.month
data['日'] = data['日期'].dt.day
data['星期几'] = data['日期'].dt.weekday # 0=星期一, 6=星期日
data['是否为周末'] = data['星期几'].apply(lambda x: 1 if x >= 5 else 0) # 1=周末, 0=工作日
# 进行独热编码
encoder_活动类型 = OneHotEncoder(sparse=False)
活动类型_encoded = encoder_活动类型.fit_transform(data[['活动类型']])
encoder_设备 = OneHotEncoder(sparse=False)
设备_encoded = encoder_设备.fit_transform(data[['用户设备']])
# 创建一个新的DataFrame,将独热编码的结果和其他特征合并
活动类型_df = pd.DataFrame(活动类型_encoded, columns=encoder_活动类型.get_feature_names_out(['活动类型']))
设备_df = pd.DataFrame(设备_encoded, columns=encoder_设备.get_feature_names_out(['用户设备']))
# 合并数据
data = pd.concat([data, 活动类型_df, 设备_df], axis=1)
# 删除原始列
data = data.drop(columns=['活动类型', '日期', '用户设备'])
# 打印处理后的数据
print(data)
处理后的数据
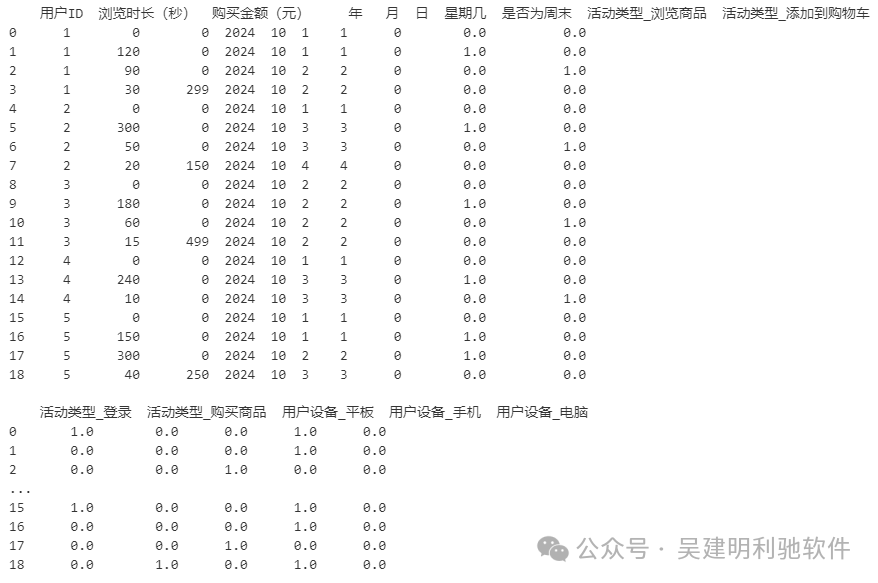
这个模拟数据集为用户活动分析提供了一个基础,涵盖用户行为、时间、花费以及设备等多维度信息。
总结
向量化是机器学习模型应用的前提步骤,它确保了模型能够处理不同类型的特征数据,并且在训练和预测中提高模型的性能和准确性。
通过对数值、类别、文本等特征进行合适的向量化处理,可以有效地提升模型的效果。


















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











