




 P-TuningV2通过在Transformer各层加入prompttokens,解决V1的局限性,增强了模型的通用性和参数学习能力,尤其在复杂任务和序列标注上表现出色,与全量fine-tuning相比毫不逊色。
P-TuningV2通过在Transformer各层加入prompttokens,解决V1的局限性,增强了模型的通用性和参数学习能力,尤其在复杂任务和序列标注上表现出色,与全量fine-tuning相比毫不逊色。
项目地址: P-Tuning
理论基础
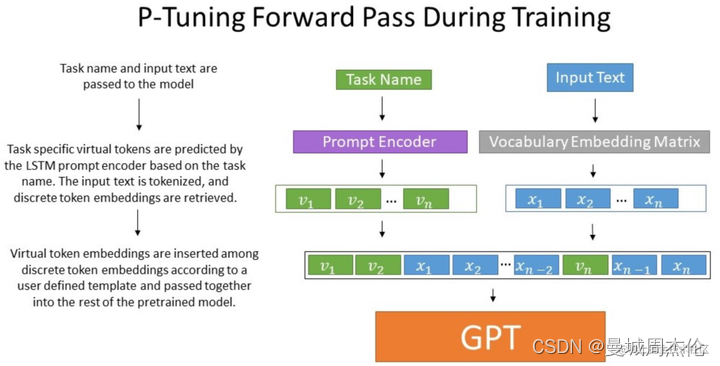
在上一篇第十三章P-tuing系列之P-tuning V1-优快云博客 简单的介绍了P-tuning V1的核心思想,其核心思想主要是通过构造训练一个少量参数的prompt-encoder(lstm+mlp) 构建无真实语义信息的 virtual token 结合原始的input从而达到能与全量fine-tuning 一样效果的预训练过程,但是V1版本同时存在下面三个方面的局限性:
-
模型通用性: 只有在1B以上的参数的预训练模型效果才能超过fine-tuing
-
任务通用性:现存在的prompt-tuning 不能很好地处理序列标签标注的任务(1. 序列标注需要预测一连串得标签而不是单一标签 2. 序列标注通常预测得是无实际意义的标签)
-
缺少深度提示优化: 在Prompt Tuning和P-tuning中,连续提示只被插入transf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











