




项目地址: P-Tuning
论文地址: [2103.10385] GPT Understands, Too (arxiv.org)
理论基础
正如果上一节介绍LoRA(自然语言处理: 第十二章LoRA解读_lora自然英语处理-优快云博客)一样,本次介绍的在21年由清华团推提出来的 P-Tuning V1系列也属于PEFT(参数高效微调系列)里的一种,其核心思想就是利用在下游任务中前置添加若干个可更新参数的虚拟[tokens] 所构成的模板prompt 再输入到文本中(不同于BERT添加额外的编码器层或者任务头),从而能达到在模型达到一定量规模以上时,效果就可以媲美全量微调。如同下面的例子,对于一个文本(情感)分类的任务,你输入一个 I love this movie ,LM(language model)通过prompt(模板:就是由 [token] 构成的前缀/后缀,注意下面的例子的模板是自然语言的,但是在p-tuing里这些token是否真的需要有意义? 通过这些模版我们使得下游任务跟预训练任务一致,这样才能更加充分地利用原始预训练模型,起到更好的零样本、小样本学习效果)的加入就会输出[pos] / [neg] 从而自动的完成这个文本分类任务或者其他NLP任务。
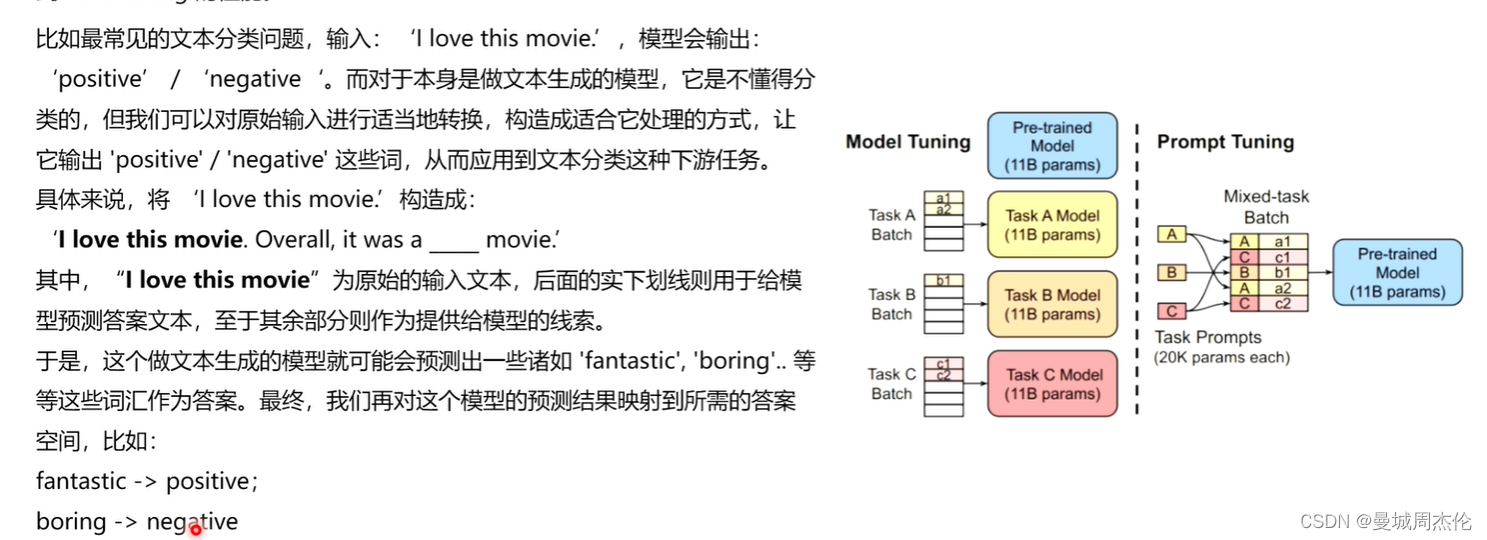
但是这种人为的去构prompt造模板有一系列问题,比如,在GPT-3采用人工构造的模版来做上下文学习(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











